 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Q-Networks: Resolving Temporal Irregularity for Deep Reinforcement Learning
May 06, 2021


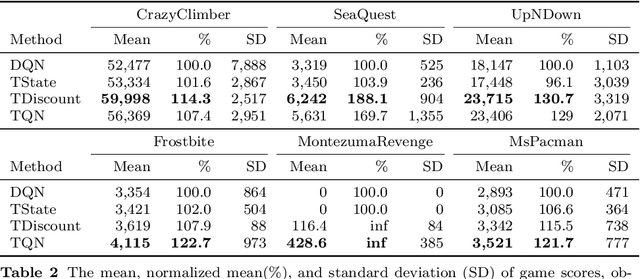
Deep Reinforcement Learning (DRL) has shown outstanding performance on inducing effective action policies that maximize expected long-term return on many complex tasks. Much of DRL work has been focused on sequences of events with discrete time steps and ignores the irregular time intervals between consecutive events. Given that in many real-world domains, data often consists of temporal sequences with irregular time intervals, and it is important to consider the time intervals between temporal events to capture latent progressive patterns of states. In this work, we present a general Time-Aware RL framework: Time-aware Q-Networks (TQN), which takes into account physical time intervals within a deep RL framework. TQN deals with time irregularity from two aspects: 1) elapsed time in the past and an expected next observation time for time-aware state approximation, and 2) action time window for the future for time-aware discounting of rewards. Experimental results show that by capturing the underlying structures in the sequences with time irregularities from both aspects, TQNs significantly outperform DQN in four types of contexts with irregular time intervals. More specifically, our results show that in classic RL tasks such as CartPole and MountainCar and Atari benchmark with randomly segmented time intervals, time-aware discounting alone is more important while in the real-world tasks such as nuclear reactor operation and septic patient treatment with intrinsic time intervals, both time-aware state and time-aware discounting are crucial. Moreover, to improve the agent's learning capacity, we explored three boosting methods: Double networks, Dueling networks, and Prioritized Experience Replay, and our results show that for the two real-world tasks, combining all three boosting methods with TQN is especially effective.
InferNet for Delayed Reinforcement Tasks: Addressing the Temporal Credit Assignment Problem
May 02, 2021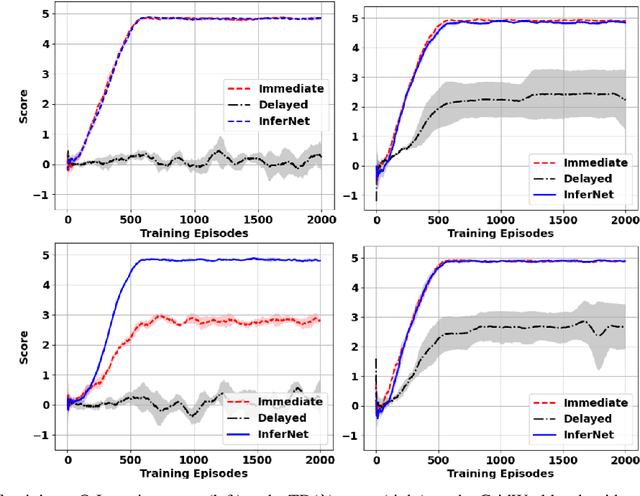



The temporal Credit Assignment Problem (CAP) is a well-known and challenging task in AI. While Reinforcement Learning (RL), especially Deep RL, works well when immediate rewards are available, it can fail when only delayed rewards are available or when the reward function is noisy. In this work, we propose delegating the CAP to a Neural Network-based algorithm named InferNet that explicitly learns to infer the immediate rewards from the delayed rewards. The effectiveness of InferNet was evaluated on two online RL tasks: a simple GridWorld and 40 Atari games; and two offline RL tasks: GridWorld and a real-life Sepsis treatment task. For all tasks, the effectiveness of using the InferNet inferred rewards is compared against the immediate and the delayed rewards with two settings: with noisy rewards and without noise. Overall, our results show that the effectiveness of InferNet is robust against noisy reward functions and is an effective add-on mechanism for solving temporal CAP in a wide range of RL tasks, from classic RL simulation environments to a real-world RL problem and for both online and offline learning.