 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Apprenticeship Learning from Imperfect Demonstrations with Evolving Rewards
Mar 31, 2026While apprenticeship learning has shown promise for inducing effective pedagogical policies directly from student interactions in e-learning environments, most existing approaches rely on optimal or near-optimal expert demonstrations under a fixed reward. Real-world student interactions, however, are often inherently imperfect and evolving: students explore, make errors, revise strategies, and refine their goals as understanding develops. In this work, we argue that imperfect student demonstrations are not noise to be discarded, but structured signals-provided their relative quality is ranked. We introduce HALIDE, Hierarchical Apprenticeship Learning from Imperfect Demonstrations with Evolving Rewards, which not only leverages sub-optimal student demonstrations, but ranks them within a hierarchical learning framework. HALIDE models student behavior at multiple levels of abstraction, enabling inference of higher-level intent and strategy from suboptimal actions while explicitly capturing the temporal evolution of student reward functions. By integrating demonstration quality into hierarchical reward inference,HALIDE distinguishes transient errors from suboptimal strategies and meaningful progress toward higher-level learning goals. Our results show that HALIDE more accurately predicts student pedagogical decisions than approaches that rely on optimal trajectories, fixed rewards, or unranked imperfect demonstrations.
Adaptive Scaffolding for Cognitive Engagement in an Intelligent Tutoring System
Feb 07, 2026The ICAP framework defines four cognitive engagement levels: Passive, Active, Constructive, and Interactive, where increased cognitive engagement can yield improved learning. However, personalizing learning activities that elicit the optimal level of cognitive engagement remains a key challenge in intelligent tutoring systems (ITS). In this work, we develop and evaluate a system that adaptively scaffolds cognitive engagement by dynamically selecting worked examples in two different ICAP modes: (active) Guided examples and (constructive) Buggy examples. We compare Bayesian Knowledge Tracing (BKT) and Deep Reinforcement Learning (DRL) as adaptive methods against a non-adaptive baseline method for selecting example type in a logic ITS. Our experiment with 113 students demonstrates that both adaptive policies significantly improved student performance on test problems. BKT yielded the largest improvement in posttest scores for low prior knowledge students, helping them catch up with their high prior knowledge peers, whereas DRL yielded significantly higher posttest scores among high prior knowledge students. This paper contributes new insights into the complex interactions of cognitive engagement and adaptivity and their results on learning outcomes.
FoodRL: A Reinforcement Learning Ensembling Framework For In-Kind Food Donation Forecasting
Nov 06, 2025Food banks are crucial for alleviating food insecurity, but their effectiveness hinges on accurately forecasting highly volatile in-kind donations to ensure equitable and efficient resource distribution. Traditional forecasting models often fail to maintain consistent accuracy due to unpredictable fluctuations and concept drift driven by seasonal variations and natural disasters such as hurricanes in the Southeastern U.S. and wildfires in the West Coast. To address these challenges, we propose FoodRL, a novel reinforcement learning (RL) based metalearning framework that clusters and dynamically weights diverse forecasting models based on recent performance and contextual information. Evaluated on multi-year data from two structurally distinct U.S. food banks-one large regional West Coast food bank affected by wildfires and another state-level East Coast food bank consistently impacted by hurricanes, FoodRL consistently outperforms baseline methods, particularly during periods of disruption or decline. By delivering more reliable and adaptive forecasts, FoodRL can facilitate the redistribution of food equivalent to 1.7 million additional meals annually, demonstrating its significant potential for social impact as well as adaptive ensemble learning for humanitarian supply chains.
Attention-Based Reward Shaping for Sparse and Delayed Rewards
May 16, 2025



Sparse and delayed reward functions pose a significant obstacle for real-world Reinforcement Learning (RL) applications. In this work, we propose Attention-based REward Shaping (ARES), a general and robust algorithm which uses a transformer's attention mechanism to generate shaped rewards and create a dense reward function for any environment. ARES requires a set of episodes and their final returns as input. It can be trained entirely offline and is able to generate meaningful shaped rewards even when using small datasets or episodes produced by agents taking random actions. ARES is compatible with any RL algorithm and can handle any level of reward sparsity. In our experiments, we focus on the most challenging case where rewards are fully delayed until the end of each episode. We evaluate ARES across a diverse range of environments, widely used RL algorithms, and baseline methods to assess the effectiveness of the shaped rewards it produces. Our results show that ARES can significantly improve learning in delayed reward settings, enabling RL agents to train in scenarios that would otherwise require impractical amounts of data or even be unlearnable. To our knowledge, ARES is the first approach that works fully offline, remains robust to extreme reward delays and low-quality data, and is not limited to goal-based tasks.
Iterative Counterfactual Data Augmentation
Feb 25, 2025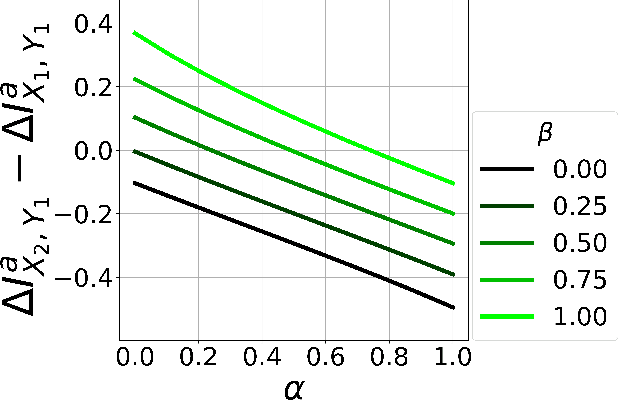

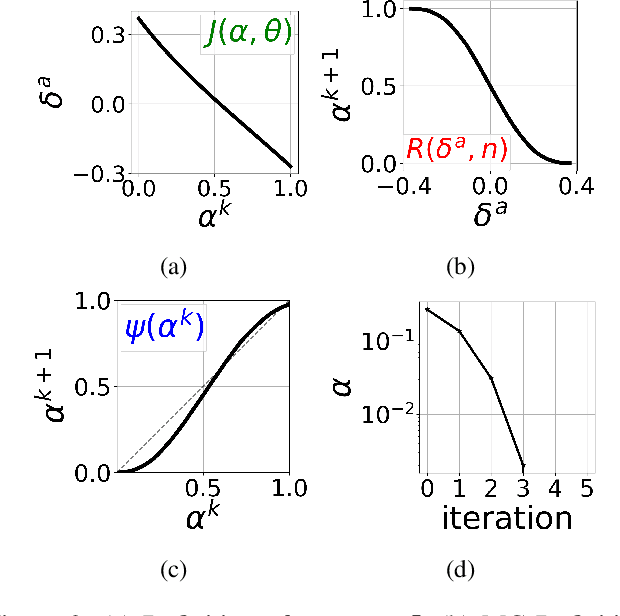

Counterfactual data augmentation (CDA) is a method for controlling information or biases in training datasets by generating a complementary dataset with typically opposing biases. Prior work often either relies on hand-crafted rules or algorithmic CDA methods which can leave unwanted information in the augmented dataset. In this work, we show iterative CDA (ICDA) with initial, high-noise interventions can converge to a state with significantly lower noise. Our ICDA procedure produces a dataset where one target signal in the training dataset maintains high mutual information with a corresponding label and the information of spurious signals are reduced. We show training on the augmented datasets produces rationales on documents that better align with human annotation. Our experiments include six human produced datasets and two large-language model generated datasets.
Off-Policy Selection for Initiating Human-Centric Experimental Design
Oct 26, 2024



In human-centric tasks such as healthcare and education, the heterogeneity among patients and students necessitates personalized treatments and instructional interventions. While reinforcement learning (RL) has been utilized in those tasks, off-policy selection (OPS) is pivotal to close the loop by offline evaluating and selecting policies without online interactions, yet current OPS methods often overlook the heterogeneity among participants. Our work is centered on resolving a pivotal challenge in human-centric systems (HCSs): how to select a policy to deploy when a new participant joining the cohort, without having access to any prior offline data collected over the participant? We introduce First-Glance Off-Policy Selection (FPS), a novel approach that systematically addresses participant heterogeneity through sub-group segmentation and tailored OPS criteria to each sub-group. By grouping individuals with similar traits, FPS facilitates personalized policy selection aligned with unique characteristics of each participant or group of participants. FPS is evaluated via two important but challenging applications, intelligent tutoring systems and a healthcare application for sepsis treatment and intervention. FPS presents significant advancement in enhancing learning outcomes of students and in-hospital care outcomes.
A Generalized Apprenticeship Learning Framework for Modeling Heterogeneous Student Pedagogical Strategies
Jun 04, 2024

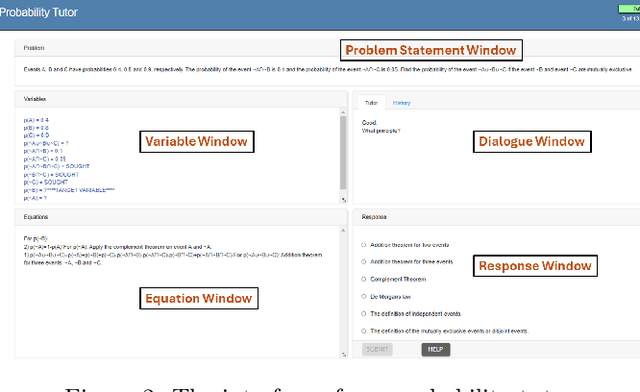

A key challenge in e-learning environments like Intelligent Tutoring Systems (ITSs) is to induce effective pedagogical policies efficiently. While Deep Reinforcement Learning (DRL) often suffers from sample inefficiency and reward function design difficulty, Apprenticeship Learning(AL) algorithms can overcome them. However, most AL algorithms can not handle heterogeneity as they assume all demonstrations are generated with a homogeneous policy driven by a single reward function. Still, some AL algorithms which consider heterogeneity, often can not generalize to large continuous state space and only work with discrete states. In this paper, we propose an expectation-maximization(EM)-EDM, a general AL framework to induce effective pedagogical policies from given optimal or near-optimal demonstrations, which are assumed to be driven by heterogeneous reward functions. We compare the effectiveness of the policies induced by our proposed EM-EDM against four AL-based baselines and two policies induced by DRL on two different but related tasks that involve pedagogical action prediction. Our overall results showed that, for both tasks, EM-EDM outperforms the four AL baselines across all performance metrics and the two DRL baselines. This suggests that EM-EDM can effectively model complex student pedagogical decision-making processes through the ability to manage a large, continuous state space and adapt to handle diverse and heterogeneous reward functions with very few given demonstrations.
Off-Policy Evaluation for Human Feedback
Oct 14, 2023



Off-policy evaluation (OPE) is important for closing the gap between offline training and evaluation of reinforcement learning (RL), by estimating performance and/or rank of target (evaluation) policies using offline trajectories only. It can improve the safety and efficiency of data collection and policy testing procedures in situations where online deployments are expensive, such as healthcare. However, existing OPE methods fall short in estimating human feedback (HF) signals, as HF may be conditioned over multiple underlying factors and is only sparsely available; as opposed to the agent-defined environmental rewards (used in policy optimization), which are usually determined over parametric functions or distributions. Consequently, the nature of HF signals makes extrapolating accurate OPE estimations to be challenging. To resolve this, we introduce an OPE for HF (OPEHF) framework that revives existing OPE methods in order to accurately evaluate the HF signals. Specifically, we develop an immediate human reward (IHR) reconstruction approach, regularized by environmental knowledge distilled in a latent space that captures the underlying dynamics of state transitions as well as issuing HF signals. Our approach has been tested over two real-world experiments, adaptive in-vivo neurostimulation and intelligent tutoring, as well as in a simulation environment (visual Q&A). Results show that our approach significantly improves the performance toward estimating HF signals accurately, compared to directly applying (variants of) existing OPE methods.
An Offline Time-aware Apprenticeship Learning Framework for Evolving Reward Functions
May 15, 2023


Apprenticeship learning (AL) is a process of inducing effective decision-making policies via observing and imitating experts' demonstrations. Most existing AL approaches, however, are not designed to cope with the evolving reward functions commonly found in human-centric tasks such as healthcare, where offline learning is required. In this paper, we propose an offline Time-aware Hierarchical EM Energy-based Sub-trajectory (THEMES) AL framework to tackle the evolving reward functions in such tasks. The effectiveness of THEMES is evaluated via a challenging task -- sepsis treatment. The experimental results demonstrate that THEMES can significantly outperform competitive state-of-the-art baselines.
Bridging Declarative, Procedural, and Conditional Metacognitive Knowledge Gap Using Deep Reinforcement Learning
Apr 23, 2023



In deductive domains, three metacognitive knowledge types in ascending order are declarative, procedural, and conditional learning. This work leverages Deep Reinforcement Learning (DRL) in providing adaptive metacognitive interventions to bridge the gap between the three knowledge types and prepare students for future learning across Intelligent Tutoring Systems (ITSs). Students received these interventions that taught how and when to use a backward-chaining (BC) strategy on a logic tutor that supports a default forward-chaining strategy. Six weeks later, we trained students on a probability tutor that only supports BC without interventions. Our results show that on both ITSs, DRL bridged the metacognitive knowledge gap between students and significantly improved their learning performance over their control peers. Furthermore, the DRL policy adapted to the metacognitive development on the logic tutor across declarative, procedural, and conditional students, causing their strategic decisions to be more autonomous.