 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Verification Hurts: Asymmetric Effects of Multi-Agent Feedback in Logic Proof Tutoring
Mar 28, 2026Large language models (LLMs) are increasingly used for automated tutoring, but their reliability in structured symbolic domains remains unclear. We study step-level feedback for propositional logic proofs, which require precise symbolic reasoning aligned with a learner's current proof state. We introduce a knowledge-graph-grounded benchmark of 516 unique proof states with step-level annotations and difficulty metrics. Unlike prior tutoring evaluations that rely on model self-assessment or binary correctness, our framework enables fine-grained analysis of feedback quality against verified solution paths. We evaluate three role-specialized pipelines with varying solution access: Tutor (partial solution access), Teacher (full derivation access), and Judge (verification of Tutor feedback). Our results reveal a striking asymmetry: verification improves outcomes when upstream feedback is error-prone (<70% accuracy), but degrades performance by 4-6 percentage points through over-specification when feedback is already reliable (>85%). Critically, we identify a shared complexity ceiling; no model or pipeline reliably succeeds on proof states exceeding complexity 4-5. These findings challenge the assumption that adding verifiers or richer context universally improves tutoring, motivating adaptive, difficulty-aware architectures that route problems by estimated complexity and upstream reliability.
Adaptive Scaffolding for Cognitive Engagement in an Intelligent Tutoring System
Feb 07, 2026The ICAP framework defines four cognitive engagement levels: Passive, Active, Constructive, and Interactive, where increased cognitive engagement can yield improved learning. However, personalizing learning activities that elicit the optimal level of cognitive engagement remains a key challenge in intelligent tutoring systems (ITS). In this work, we develop and evaluate a system that adaptively scaffolds cognitive engagement by dynamically selecting worked examples in two different ICAP modes: (active) Guided examples and (constructive) Buggy examples. We compare Bayesian Knowledge Tracing (BKT) and Deep Reinforcement Learning (DRL) as adaptive methods against a non-adaptive baseline method for selecting example type in a logic ITS. Our experiment with 113 students demonstrates that both adaptive policies significantly improved student performance on test problems. BKT yielded the largest improvement in posttest scores for low prior knowledge students, helping them catch up with their high prior knowledge peers, whereas DRL yielded significantly higher posttest scores among high prior knowledge students. This paper contributes new insights into the complex interactions of cognitive engagement and adaptivity and their results on learning outcomes.
Enhancing Mathematical Problem Solving in LLMs through Execution-Driven Reasoning Augmentation
Feb 03, 2026Mathematical problem solving is a fundamental benchmark for assessing the reasoning capabilities of artificial intelligence and a gateway to applications in education, science, and engineering where reliable symbolic reasoning is essential. Although recent advances in multi-agent LLM-based systems have enhanced their mathematical reasoning capabilities, they still lack a reliably revisable representation of the reasoning process. Existing agents either operate in rigid sequential pipelines that cannot correct earlier steps or rely on heuristic self-evaluation that can fail to identify and fix errors. In addition, programmatic context can distract language models and degrade accuracy. To address these gaps, we introduce Iteratively Improved Program Construction (IIPC), a reasoning method that iteratively refines programmatic reasoning chains and combines execution feedback with the native Chain-of-thought abilities of the base LLM to maintain high-level contextual focus. IIPC surpasses competing approaches in the majority of reasoning benchmarks on multiple base LLMs. All code and implementations are released as open source.
The Promise and Limits of LLMs in Constructing Proofs and Hints for Logic Problems in Intelligent Tutoring Systems
May 07, 2025Intelligent tutoring systems have demonstrated effectiveness in teaching formal propositional logic proofs, but their reliance on template-based explanations limits their ability to provide personalized student feedback. While large language models (LLMs) offer promising capabilities for dynamic feedback generation, they risk producing hallucinations or pedagogically unsound explanations. We evaluated the stepwise accuracy of LLMs in constructing multi-step symbolic logic proofs, comparing six prompting techniques across four state-of-the-art LLMs on 358 propositional logic problems. Results show that DeepSeek-V3 achieved superior performance with 84.4% accuracy on stepwise proof construction and excelled particularly in simpler rules. We further used the best-performing LLM to generate explanatory hints for 1,050 unique student problem-solving states from a logic ITS and evaluated them on 4 criteria with both an LLM grader and human expert ratings on a 20% sample. Our analysis finds that LLM-generated hints were 75% accurate and rated highly by human evaluators on consistency and clarity, but did not perform as well explaining why the hint was provided or its larger context. Our results demonstrate that LLMs may be used to augment tutoring systems with logic tutoring hints, but requires additional modifications to ensure accuracy and pedagogical appropriateness.
LLMs' Reshaping of People, Processes, Products, and Society in Software Development: A Comprehensive Exploration with Early Adopters
Mar 06, 2025Large language models (LLMs) like OpenAI ChatGPT, Google Gemini, and GitHub Copilot are rapidly gaining traction in the software industry, but their full impact on software engineering remains insufficiently explored. Despite their growing adoption, there is a notable lack of formal, qualitative assessments of how LLMs are applied in real-world software development contexts. To fill this gap, we conducted semi-structured interviews with sixteen early-adopter professional developers to explore their use of LLMs throughout various stages of the software development life cycle. Our investigation examines four dimensions: people - how LLMs affect individual developers and teams; process - how LLMs alter software engineering workflows; product - LLM impact on software quality and innovation; and society - the broader socioeconomic and ethical implications of LLM adoption. Thematic analysis of our data reveals that while LLMs have not fundamentally revolutionized the development process, they have substantially enhanced routine coding tasks, including code generation, refactoring, and debugging. Developers reported the most effective outcomes when providing LLMs with clear, well-defined problem statements, indicating that LLMs excel with decomposed problems and specific requirements. Furthermore, these early-adopters identified that LLMs offer significant value for personal and professional development, aiding in learning new languages and concepts. Early-adopters, highly skilled in software engineering and how LLMs work, identified early and persisting challenges for software engineering, such as inaccuracies in generated content and the need for careful manual review before integrating LLM outputs into production environments. Our study provides a nuanced understanding of how LLMs are shaping the landscape of software development, with their benefits, limitations, and ongoing implications.
Bridging Declarative, Procedural, and Conditional Metacognitive Knowledge Gap Using Deep Reinforcement Learning
Apr 23, 2023



In deductive domains, three metacognitive knowledge types in ascending order are declarative, procedural, and conditional learning. This work leverages Deep Reinforcement Learning (DRL) in providing adaptive metacognitive interventions to bridge the gap between the three knowledge types and prepare students for future learning across Intelligent Tutoring Systems (ITSs). Students received these interventions that taught how and when to use a backward-chaining (BC) strategy on a logic tutor that supports a default forward-chaining strategy. Six weeks later, we trained students on a probability tutor that only supports BC without interventions. Our results show that on both ITSs, DRL bridged the metacognitive knowledge gap between students and significantly improved their learning performance over their control peers. Furthermore, the DRL policy adapted to the metacognitive development on the logic tutor across declarative, procedural, and conditional students, causing their strategic decisions to be more autonomous.
Leveraging Deep Reinforcement Learning for Metacognitive Interventions across Intelligent Tutoring Systems
Apr 17, 2023

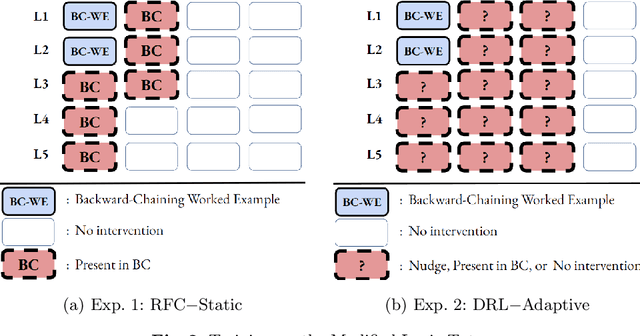

This work compares two approaches to provide metacognitive interventions and their impact on preparing students for future learning across Intelligent Tutoring Systems (ITSs). In two consecutive semesters, we conducted two classroom experiments: Exp. 1 used a classic artificial intelligence approach to classify students into different metacognitive groups and provide static interventions based on their classified groups. In Exp. 2, we leveraged Deep Reinforcement Learning (DRL) to provide adaptive interventions that consider the dynamic changes in the student's metacognitive levels. In both experiments, students received these interventions that taught how and when to use a backward-chaining (BC) strategy on a logic tutor that supports a default forward-chaining strategy. Six weeks later, we trained students on a probability tutor that only supports BC without interventions. Our results show that adaptive DRL-based interventions closed the metacognitive skills gap between students. In contrast, static classifier-based interventions only benefited a subset of students who knew how to use BC in advance. Additionally, our DRL agent prepared the experimental students for future learning by significantly surpassing their control peers on both ITSs.
The Power of Nudging: Exploring Three Interventions for Metacognitive Skills Instruction across Intelligent Tutoring Systems
Mar 18, 2023



Deductive domains are typical of many cognitive skills in that no single problem-solving strategy is always optimal for solving all problems. It was shown that students who know how and when to use each strategy (StrTime) outperformed those who know neither and stick to the default strategy (Default). In this work, students were trained on a logic tutor that supports a default forward-chaining and a backward-chaining (BC) strategy, then a probability tutor that only supports BC. We investigated three types of interventions on teaching the Default students how and when to use which strategy on the logic tutor: Example, Nudge and Presented. Meanwhile, StrTime students received no interventions. Overall, our results show that Nudge outperformed their Default peers and caught up with StrTime on both tutors.
Mixing Backward- with Forward-Chaining for Metacognitive Skill Acquisition and Transfer
Mar 18, 2023Metacognitive skills have been commonly associated with preparation for future learning in deductive domains. Many researchers have regarded strategy- and time-awareness as two metacognitive skills that address how and when to use a problem-solving strategy, respectively. It was shown that students who are both strategy-and time-aware (StrTime) outperformed their nonStrTime peers across deductive domains. In this work, students were trained on a logic tutor that supports a default forward-chaining (FC) and a backward-chaining (BC) strategy. We investigated the impact of mixing BC with FC on teaching strategy- and time-awareness for nonStrTime students. During the logic instruction, the experimental students (Exp) were provided with two BC worked examples and some problems in BC to practice how and when to use BC. Meanwhile, their control (Ctrl) and StrTime peers received no such intervention. Six weeks later, all students went through a probability tutor that only supports BC to evaluate whether the acquired metacognitive skills are transferred from logic. Our results show that on both tutors, Exp outperformed Ctrl and caught up with StrTime.
Investigating the Impact of Backward Strategy Learning in a Logic Tutor: Aiding Subgoal Learning towards Improved Problem Solving
Jul 27, 2022

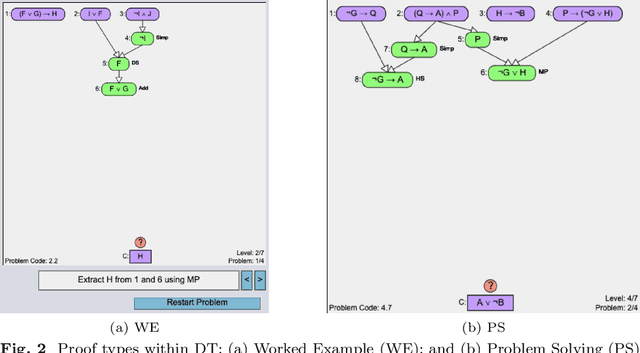
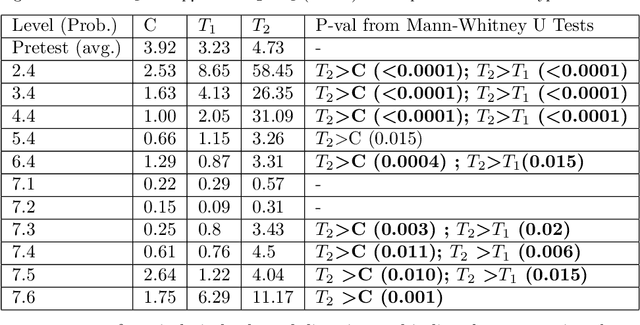
Learning to derive subgoals reduces the gap between experts and students and makes students prepared for future problem solving. Researchers have explored subgoal labeled instructional materials with explanations in traditional problem solving and within tutoring systems to help novices learn to subgoal. However, only a little research is found on problem-solving strategies in relationship with subgoal learning. Also, these strategies are under-explored within computer-based tutors and learning environments. Backward problem-solving strategy is closely related to the process of subgoaling, where problem solving iteratively refines the goal into a new subgoal to reduce difficulty. In this paper, we explore a training strategy for backward strategy learning within an intelligent logic tutor that teaches logic proof construction. The training session involved backward worked examples (BWE) and problem-solving (BPS) to help students learn backward strategy towards improving their subgoaling and problem-solving skills. To evaluate the training strategy, we analyzed students' 1) experience with and engagement in learning backward strategy, 2) performance, and 3) proof construction approaches in new problems that they solved independently without tutor help after each level of training and in post-test. Our results showed that, when new problems were given to solve without any tutor help, students who were trained with both BWE and BPS outperformed students who received none of the treatment or only BWE during training. Additionally, students trained with both BWE and BPS derived subgoals during proof construction with significantly higher efficiency than the other two groups.