 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudents' Perceptions and Preferences of Generative Artificial Intelligence Feedback for Programming
Dec 17, 2023The rapid evolution of artificial intelligence (AI), specifically large language models (LLMs), has opened opportunities for various educational applications. This paper explored the feasibility of utilizing ChatGPT, one of the most popular LLMs, for automating feedback for Java programming assignments in an introductory computer science (CS1) class. Specifically, this study focused on three questions: 1) To what extent do students view LLM-generated feedback as formative? 2) How do students see the comparative affordances of feedback prompts that include their code, vs. those that exclude it? 3) What enhancements do students suggest for improving AI-generated feedback? To address these questions, we generated automated feedback using the ChatGPT API for four lab assignments in the CS1 class. The survey results revealed that students perceived the feedback as aligning well with formative feedback guidelines established by Shute. Additionally, students showed a clear preference for feedback generated by including the students' code as part of the LLM prompt, and our thematic study indicated that the preference was mainly attributed to the specificity, clarity, and corrective nature of the feedback. Moreover, this study found that students generally expected specific and corrective feedback with sufficient code examples, but had diverged opinions on the tone of the feedback. This study demonstrated that ChatGPT could generate Java programming assignment feedback that students perceived as formative. It also offered insights into the specific improvements that would make the ChatGPT-generated feedback useful for students.
Code-DKT: A Code-based Knowledge Tracing Model for Programming Tasks
Jun 07, 2022

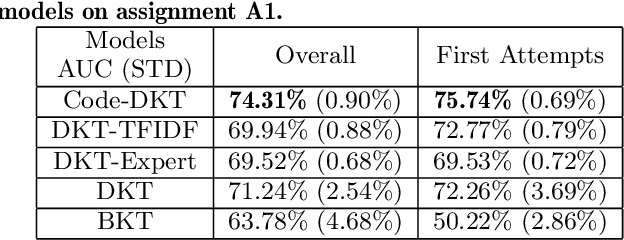
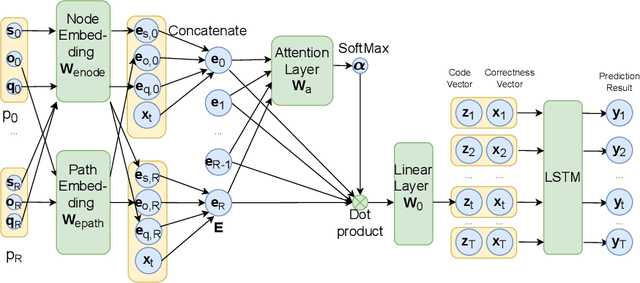
Knowledge tracing (KT) models are a popular approach for predicting students' future performance at practice problems using their prior attempts. Though many innovations have been made in KT, most models including the state-of-the-art Deep KT (DKT) mainly leverage each student's response either as correct or incorrect, ignoring its content. In this work, we propose Code-based Deep Knowledge Tracing (Code-DKT), a model that uses an attention mechanism to automatically extract and select domain-specific code features to extend DKT. We compared the effectiveness of Code-DKT against Bayesian and Deep Knowledge Tracing (BKT and DKT) on a dataset from a class of 50 students attempting to solve 5 introductory programming assignments. Our results show that Code-DKT consistently outperforms DKT by 3.07-4.00% AUC across the 5 assignments, a comparable improvement to other state-of-the-art domain-general KT models over DKT. Finally, we analyze problem-specific performance through a set of case studies for one assignment to demonstrate when and how code features improve Code-DKT's predictions.