 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
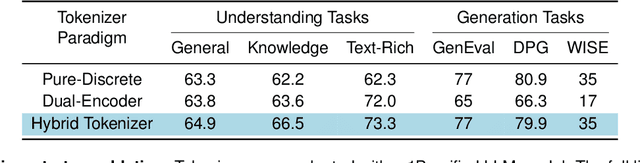
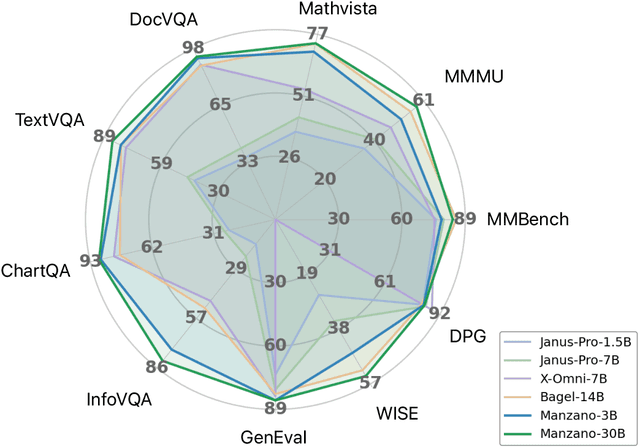
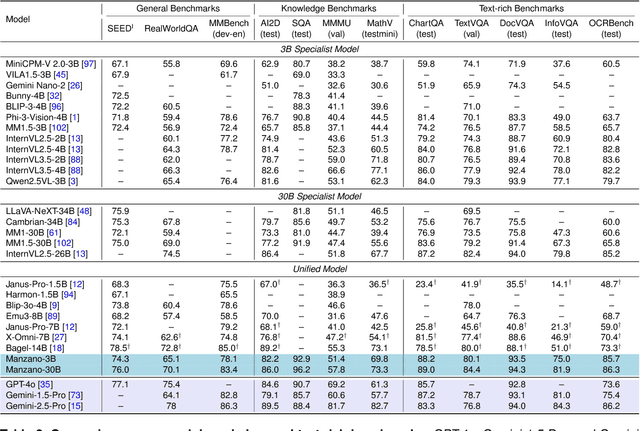
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
Students' Perceptions and Preferences of Generative Artificial Intelligence Feedback for Programming
Dec 17, 2023The rapid evolution of artificial intelligence (AI), specifically large language models (LLMs), has opened opportunities for various educational applications. This paper explored the feasibility of utilizing ChatGPT, one of the most popular LLMs, for automating feedback for Java programming assignments in an introductory computer science (CS1) class. Specifically, this study focused on three questions: 1) To what extent do students view LLM-generated feedback as formative? 2) How do students see the comparative affordances of feedback prompts that include their code, vs. those that exclude it? 3) What enhancements do students suggest for improving AI-generated feedback? To address these questions, we generated automated feedback using the ChatGPT API for four lab assignments in the CS1 class. The survey results revealed that students perceived the feedback as aligning well with formative feedback guidelines established by Shute. Additionally, students showed a clear preference for feedback generated by including the students' code as part of the LLM prompt, and our thematic study indicated that the preference was mainly attributed to the specificity, clarity, and corrective nature of the feedback. Moreover, this study found that students generally expected specific and corrective feedback with sufficient code examples, but had diverged opinions on the tone of the feedback. This study demonstrated that ChatGPT could generate Java programming assignment feedback that students perceived as formative. It also offered insights into the specific improvements that would make the ChatGPT-generated feedback useful for students.
Noise2Music: Text-conditioned Music Generation with Diffusion Models
Feb 08, 2023

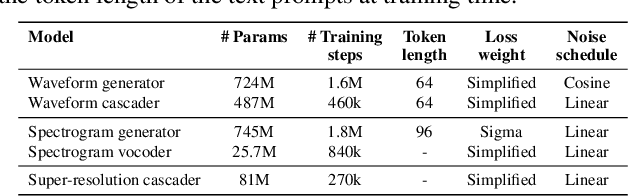
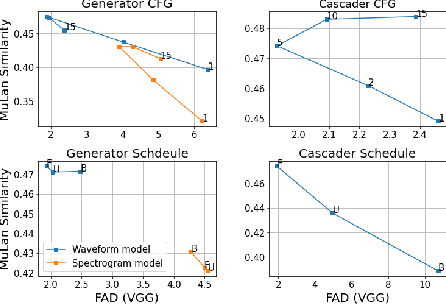
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
Scene Transformer: A unified multi-task model for behavior prediction and planning
Jun 15, 2021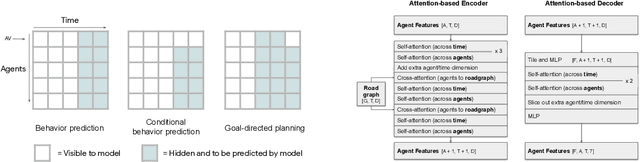
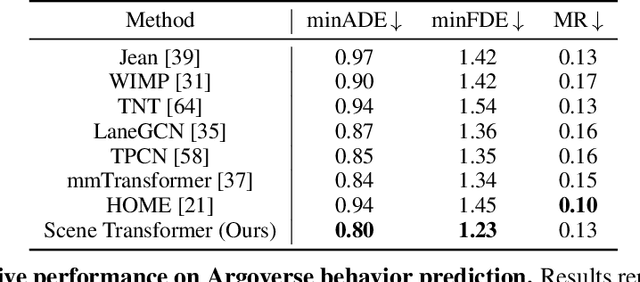
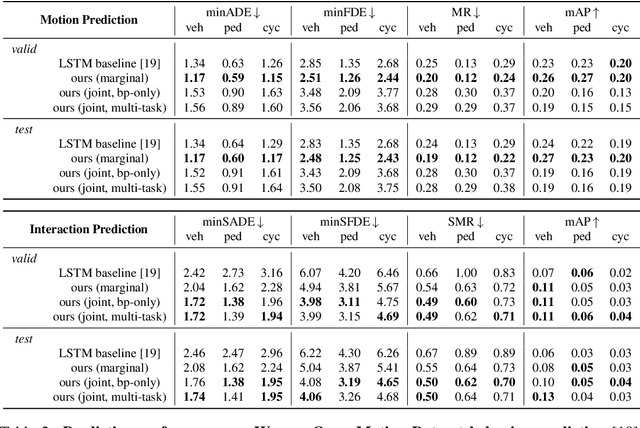
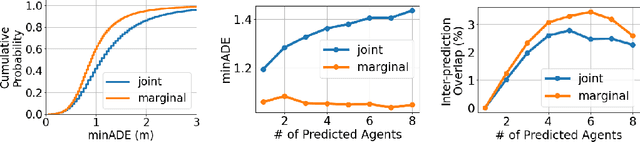
Predicting the future motion of multiple agents is necessary for planning in dynamic environments. This task is challenging for autonomous driving since agents (e.g., vehicles and pedestrians) and their associated behaviors may be diverse and influence each other. Most prior work has focused on first predicting independent futures for each agent based on all past motion, and then planning against these independent predictions. However, planning against fixed predictions can suffer from the inability to represent the future interaction possibilities between different agents, leading to sub-optimal planning. In this work, we formulate a model for predicting the behavior of all agents jointly in real-world driving environments in a unified manner. Inspired by recent language modeling approaches, we use a masking strategy as the query to our model, enabling one to invoke a single model to predict agent behavior in many ways, such as potentially conditioned on the goal or full future trajectory of the autonomous vehicle or the behavior of other agents in the environment. Our model architecture fuses heterogeneous world state in a unified Transformer architecture by employing attention across road elements, agent interactions and time steps. We evaluate our approach on autonomous driving datasets for behavior prediction, and achieve state-of-the-art performance. Our work demonstrates that formulating the problem of behavior prediction in a unified architecture with a masking strategy may allow us to have a single model that can perform multiple motion prediction and planning related tasks effectively.
RRA-U-Net: a Residual Encoder to Attention Decoder by Residual Connections Framework for Spine Segmentation under Noisy Labels
Sep 27, 2020


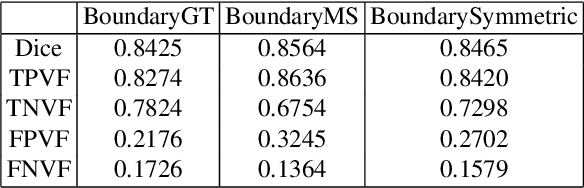
Segmentation algorithms of medical image volumes are widely studied for many clinical and research purposes. We propose a novel and efficient framework for medical image segmentation. The framework functions under a deep learning paradigm, incorporating four novel contributions. Firstly, a residual interconnection is explored in different scale encoders. Secondly, four copy and crop connections are replaced to residual-block-based concatenation to alleviate the disparity between encoders and decoders, respectively. Thirdly, convolutional attention modules for feature refinement are studied on all scale decoders. Finally, an adaptive clean noisy label learning strategy(ACNLL) based on the training process from underfitting to overfitting is studied. Experimental results are illustrated on a publicly available benchmark database of spine CTs. Our segmentation framework achieves competitive performance with other state-of-the-art methods over a variety of different evaluation measures.
Conformer: Convolution-augmented Transformer for Speech Recognition
May 16, 2020
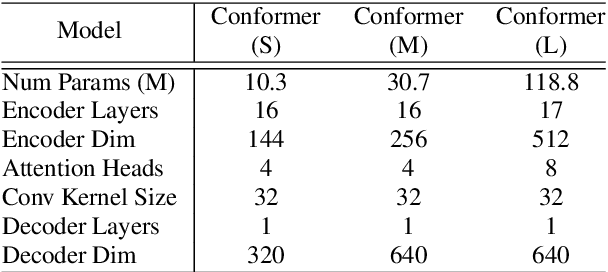

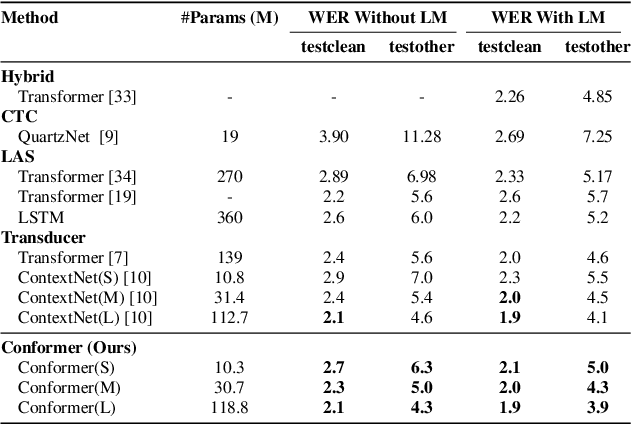
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
May 16, 2020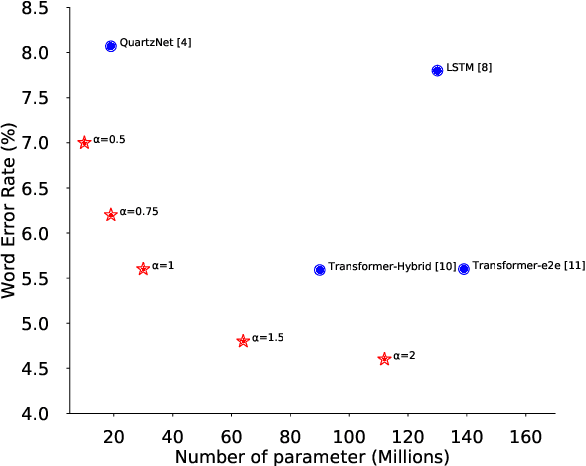
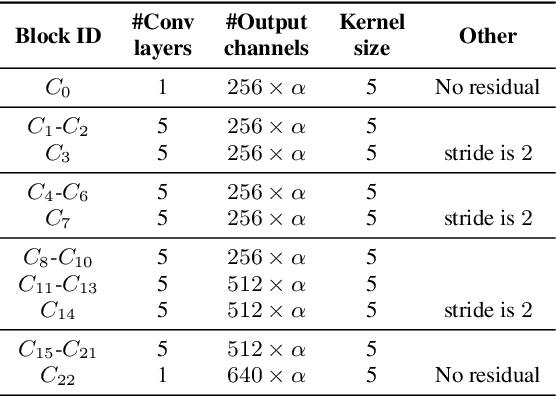
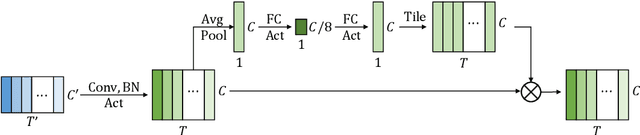

Convolutional neural networks (CNN) have shown promising results for end-to-end speech recognition, albeit still behind other state-of-the-art methods in performance. In this paper, we study how to bridge this gap and go beyond with a novel CNN-RNN-transducer architecture, which we call ContextNet. ContextNet features a fully convolutional encoder that incorporates global context information into convolution layers by adding squeeze-and-excitation modules. In addition, we propose a simple scaling method that scales the widths of ContextNet that achieves good trade-off between computation and accuracy. We demonstrate that on the widely used LibriSpeech benchmark, ContextNet achieves a word error rate (WER) of 2.1%/4.6% without external language model (LM), 1.9%/4.1% with LM and 2.9%/7.0% with only 10M parameters on the clean/noisy LibriSpeech test sets. This compares to the previous best published system of 2.0%/4.6% with LM and 3.9%/11.3% with 20M parameters. The superiority of the proposed ContextNet model is also verified on a much larger internal dataset.
Streaming Object Detection for 3-D Point Clouds
May 04, 2020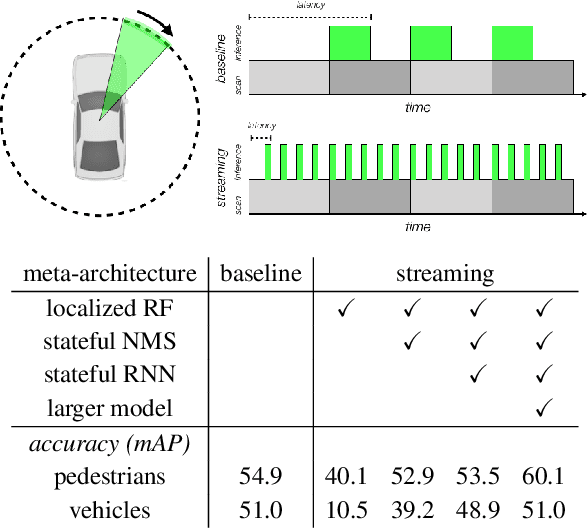
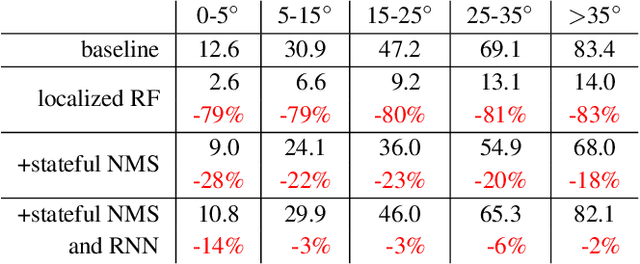
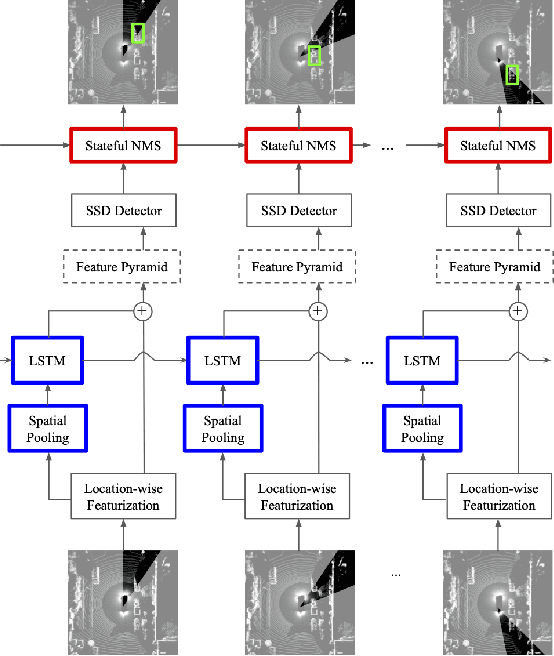
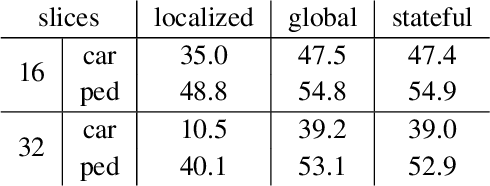
Autonomous vehicles operate in a dynamic environment, where the speed with which a vehicle can perceive and react impacts the safety and efficacy of the system. LiDAR provides a prominent sensory modality that informs many existing perceptual systems including object detection, segmentation, motion estimation, and action recognition. The latency for perceptual systems based on point cloud data can be dominated by the amount of time for a complete rotational scan (e.g. 100 ms). This built-in data capture latency is artificial, and based on treating the point cloud as a camera image in order to leverage camera-inspired architectures. However, unlike camera sensors, most LiDAR point cloud data is natively a streaming data source in which laser reflections are sequentially recorded based on the precession of the laser beam. In this work, we explore how to build an object detector that removes this artificial latency constraint, and instead operates on native streaming data in order to significantly reduce latency. This approach has the added benefit of reducing the peak computational burden on inference hardware by spreading the computation over the acquisition time for a scan. We demonstrate a family of streaming detection systems based on sequential modeling through a series of modifications to the traditional detection meta-architecture. We highlight how this model may achieve competitive if not superior predictive performance with state-of-the-art, traditional non-streaming detection systems while achieving significant latency gains (e.g. 1/15'th - 1/3'rd of peak latency). Our results show that operating on LiDAR data in its native streaming formulation offers several advantages for self driving object detection -- advantages that we hope will be useful for any LiDAR perception system where minimizing latency is critical for safe and efficient operation.
Deep Learning in Medical Ultrasound Image Segmentation: a Review
Feb 25, 2020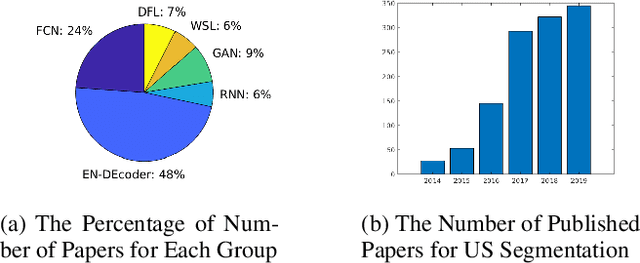
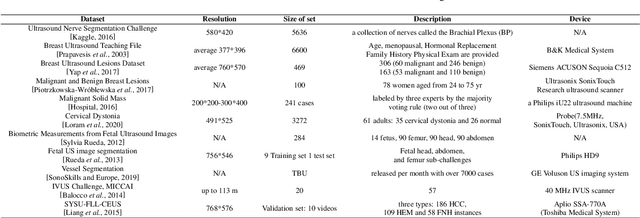


Applying machine learning technologies, especially deep learning, into medical image segmentation is being widely studied because of its state-of-the-art performance and results. It can be a key step to provide a reliable basis for clinical diagnosis, such as 3D reconstruction of human tissues, image-guided interventions, image analyzing and visualization. In this review article, deep-learning-based methods for ultrasound image segmentation are categorized into six main groups according to their architectures and training at first. Secondly, for each group, several current representative algorithms are selected, introduced, analyzed and summarized in detail. In addition, common evaluation methods for image segmentation and ultrasound image segmentation datasets are summarized. Further, the performance of the current methods and their evaluations are reviewed. In the end, the challenges and potential research directions for medical ultrasound image segmentation are discussed.
A Novel and Efficient Tumor Detection Framework for Pancreatic Cancer via CT Images
Feb 11, 2020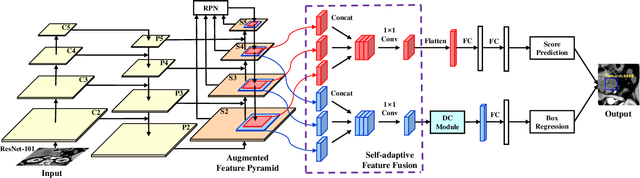
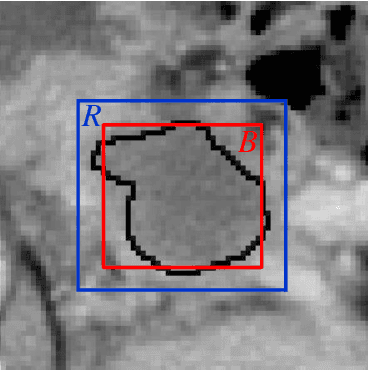
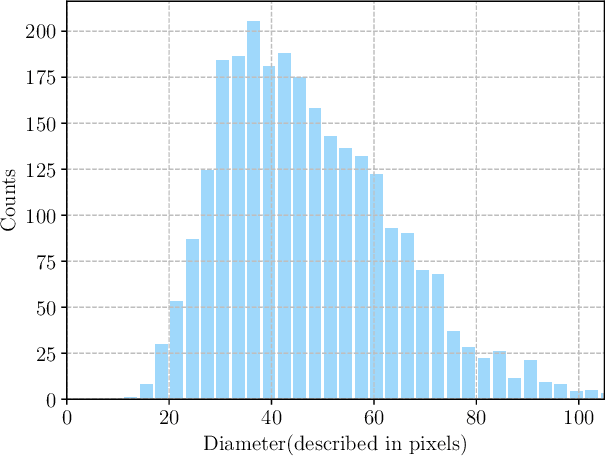
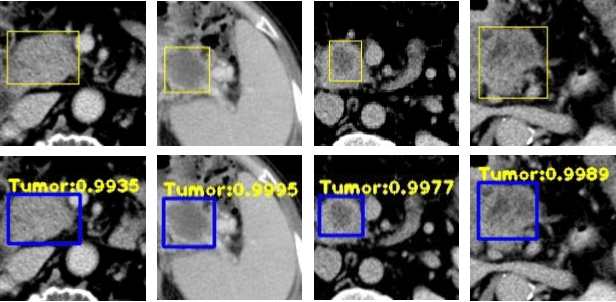
As Deep Convolutional Neural Networks (DCNNs) have shown robust performance and results in medical image analysis, a number of deep-learning-based tumor detection methods were developed in recent years. Nowadays, the automatic detection of pancreatic tumors using contrast-enhanced Computed Tomography (CT) is widely applied for the diagnosis and staging of pancreatic cancer. Traditional hand-crafted methods only extract low-level features. Normal convolutional neural networks, however, fail to make full use of effective context information, which causes inferior detection results. In this paper, a novel and efficient pancreatic tumor detection framework aiming at fully exploiting the context information at multiple scales is designed. More specifically, the contribution of the proposed method mainly consists of three components: Augmented Feature Pyramid networks, Self-adaptive Feature Fusion and a Dependencies Computation (DC) Module. A bottom-up path augmentation to fully extract and propagate low-level accurate localization information is established firstly. Then, the Self-adaptive Feature Fusion can encode much richer context information at multiple scales based on the proposed regions. Finally, the DC Module is specifically designed to capture the interaction information between proposals and surrounding tissues. Experimental results achieve competitive performance in detection with the AUC of 0.9455, which outperforms other state-of-the-art methods to our best of knowledge, demonstrating the proposed framework can detect the tumor of pancreatic cancer efficiently and accurately.