 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
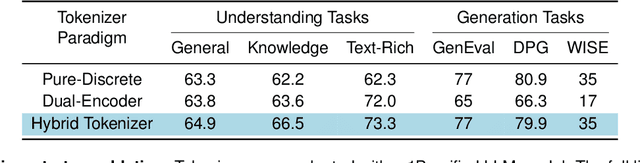
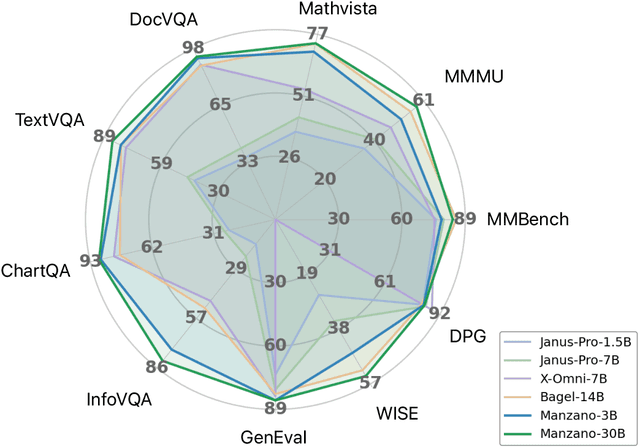
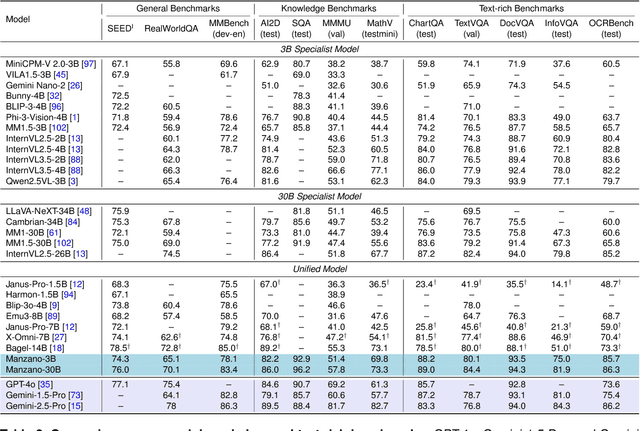
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
Autellix: An Efficient Serving Engine for LLM Agents as General Programs
Feb 19, 2025Large language model (LLM) applications are evolving beyond simple chatbots into dynamic, general-purpose agentic programs, which scale LLM calls and output tokens to help AI agents reason, explore, and solve complex tasks. However, existing LLM serving systems ignore dependencies between programs and calls, missing significant opportunities for optimization. Our analysis reveals that programs submitted to LLM serving engines experience long cumulative wait times, primarily due to head-of-line blocking at both the individual LLM request and the program. To address this, we introduce Autellix, an LLM serving system that treats programs as first-class citizens to minimize their end-to-end latencies. Autellix intercepts LLM calls submitted by programs, enriching schedulers with program-level context. We propose two scheduling algorithms-for single-threaded and distributed programs-that preempt and prioritize LLM calls based on their programs' previously completed calls. Our evaluation demonstrates that across diverse LLMs and agentic workloads, Autellix improves throughput of programs by 4-15x at the same latency compared to state-of-the-art systems, such as vLLM.
SeCo-INR: Semantically Conditioned Implicit Neural Representations for Improved Medical Image Super-Resolution
Sep 02, 2024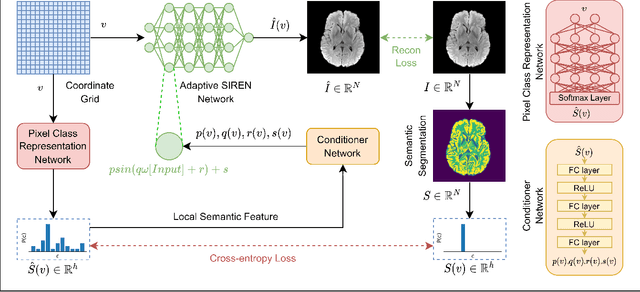
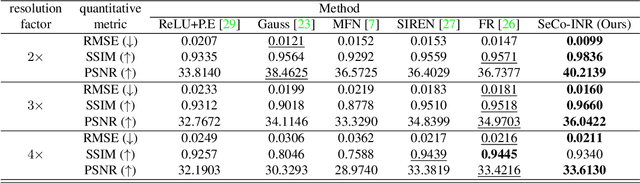
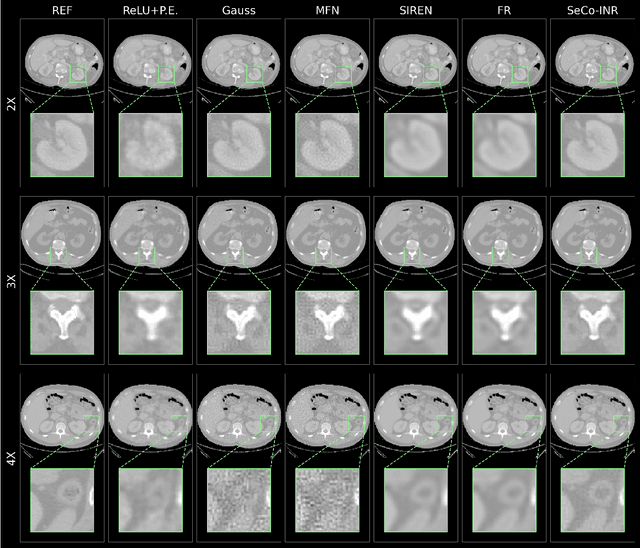
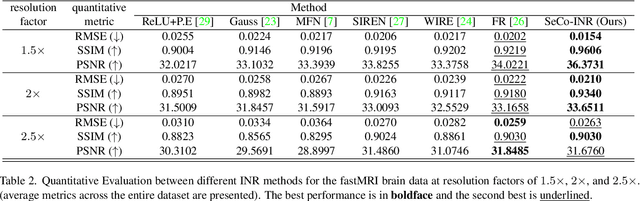
Implicit Neural Representations (INRs) have recently advanced the field of deep learning due to their ability to learn continuous representations of signals without the need for large training datasets. Although INR methods have been studied for medical image super-resolution, their adaptability to localized priors in medical images has not been extensively explored. Medical images contain rich anatomical divisions that could provide valuable local prior information to enhance the accuracy and robustness of INRs. In this work, we propose a novel framework, referred to as the Semantically Conditioned INR (SeCo-INR), that conditions an INR using local priors from a medical image, enabling accurate model fitting and interpolation capabilities to achieve super-resolution. Our framework learns a continuous representation of the semantic segmentation features of a medical image and utilizes it to derive the optimal INR for each semantic region of the image. We tested our framework using several medical imaging modalities and achieved higher quantitative scores and more realistic super-resolution outputs compared to state-of-the-art methods.
Motion-Informed Deep Learning for Brain MR Image Reconstruction Framework
May 28, 2024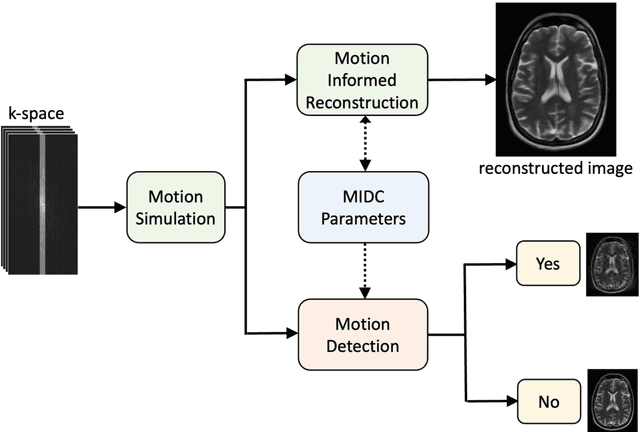
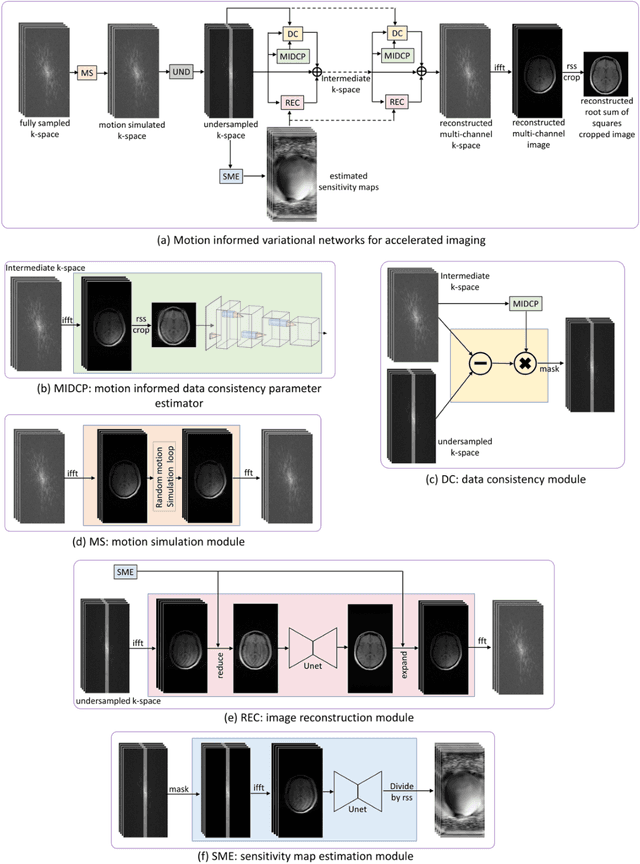
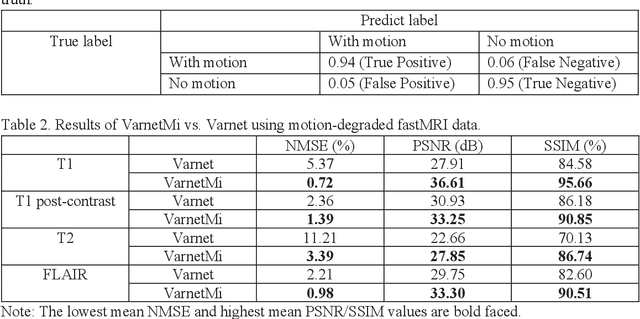
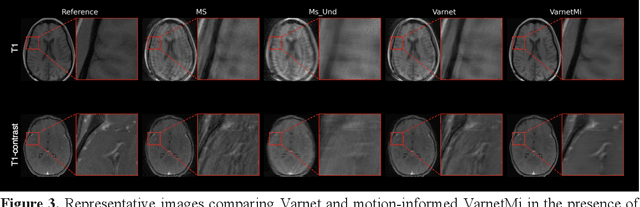
Motion artifacts in Magnetic Resonance Imaging (MRI) are one of the frequently occurring artifacts due to patient movements during scanning. Motion is estimated to be present in approximately 30% of clinical MRI scans; however, motion has not been explicitly modeled within deep learning image reconstruction models. Deep learning (DL) algorithms have been demonstrated to be effective for both the image reconstruction task and the motion correction task, but the two tasks are considered separately. The image reconstruction task involves removing undersampling artifacts such as noise and aliasing artifacts, whereas motion correction involves removing artifacts including blurring, ghosting, and ringing. In this work, we propose a novel method to simultaneously accelerate imaging and correct motion. This is achieved by integrating a motion module into the deep learning-based MRI reconstruction process, enabling real-time detection and correction of motion. We model motion as a tightly integrated auxiliary layer in the deep learning model during training, making the deep learning model 'motion-informed'. During inference, image reconstruction is performed from undersampled raw k-space data using a trained motion-informed DL model. Experimental results demonstrate that the proposed motion-informed deep learning image reconstruction network outperformed the conventional image reconstruction network for motion-degraded MRI datasets.
Stylus: Automatic Adapter Selection for Diffusion Models
Apr 29, 2024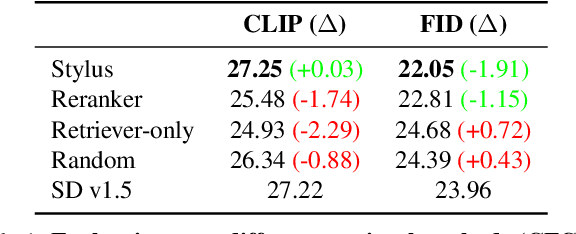
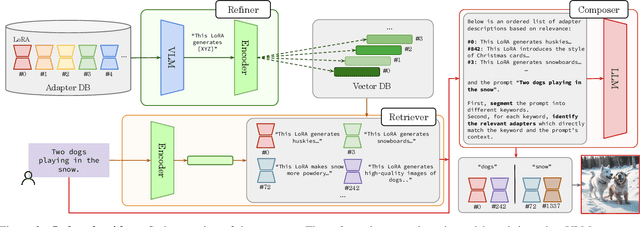

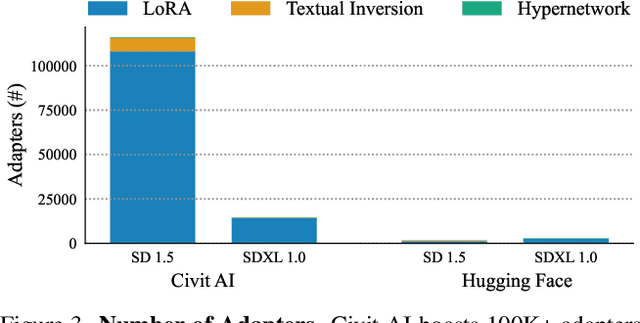
Beyond scaling base models with more data or parameters, fine-tuned adapters provide an alternative way to generate high fidelity, custom images at reduced costs. As such, adapters have been widely adopted by open-source communities, accumulating a database of over 100K adapters-most of which are highly customized with insufficient descriptions. This paper explores the problem of matching the prompt to a set of relevant adapters, built on recent work that highlight the performance gains of composing adapters. We introduce Stylus, which efficiently selects and automatically composes task-specific adapters based on a prompt's keywords. Stylus outlines a three-stage approach that first summarizes adapters with improved descriptions and embeddings, retrieves relevant adapters, and then further assembles adapters based on prompts' keywords by checking how well they fit the prompt. To evaluate Stylus, we developed StylusDocs, a curated dataset featuring 75K adapters with pre-computed adapter embeddings. In our evaluation on popular Stable Diffusion checkpoints, Stylus achieves greater CLIP-FID Pareto efficiency and is twice as preferred, with humans and multimodal models as evaluators, over the base model. See stylus-diffusion.github.io for more.
Learning to Skip for Language Modeling
Nov 26, 2023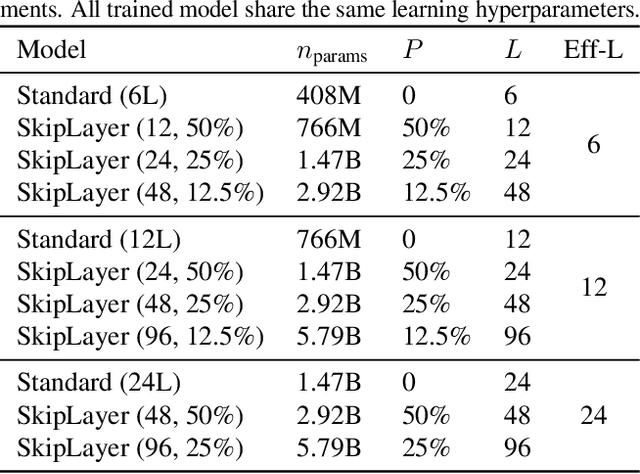
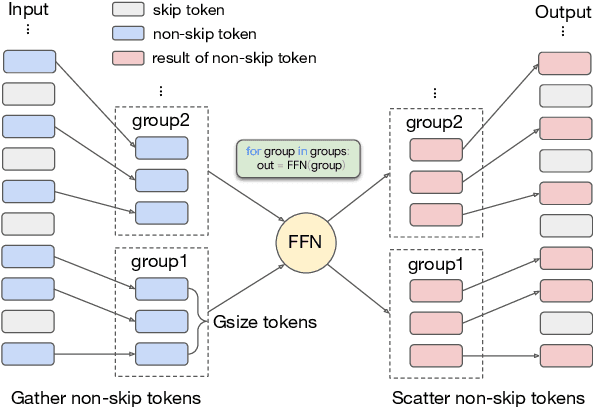
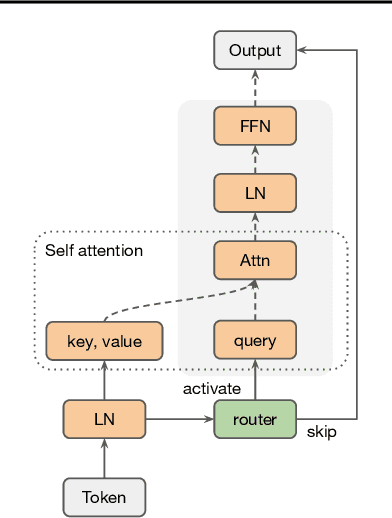
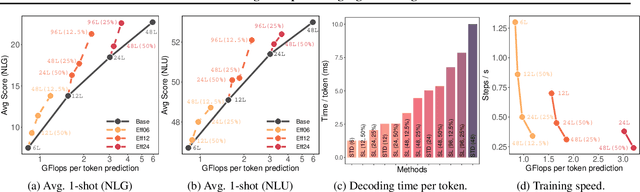
Overparameterized large-scale language models have impressive generalization performance of in-context few-shot learning. However, most language models allocate the same amount of parameters or computation to each token, disregarding the complexity or importance of the input data. We argue that in language model pretraining, a variable amount of computation should be assigned to different tokens, and this can be efficiently achieved via a simple routing mechanism. Different from conventional early stopping techniques where tokens can early exit at only early layers, we propose a more general method that dynamically skips the execution of a layer (or module) for any input token with a binary router. In our extensive evaluation across 24 NLP tasks, we demonstrate that the proposed method can significantly improve the 1-shot performance compared to other competitive baselines only at mild extra cost for inference.
Controlled Decoding from Language Models
Oct 25, 2023



We propose controlled decoding (CD), a novel off-policy reinforcement learning method to control the autoregressive generation from language models towards high reward outcomes. CD solves an off-policy reinforcement learning problem through a value function for the reward, which we call a prefix scorer. The prefix scorer is used at inference time to steer the generation towards higher reward outcomes. We show that the prefix scorer may be trained on (possibly) off-policy data to predict the expected reward when decoding is continued from a partially decoded response. We empirically demonstrate that CD is effective as a control mechanism on Reddit conversations corpus. We also show that the modularity of the design of CD makes it possible to control for multiple rewards, effectively solving a multi-objective reinforcement learning problem with no additional complexity. Finally, we show that CD can be applied in a novel blockwise fashion at inference-time, again without the need for any training-time changes, essentially bridging the gap between the popular best-of-$K$ strategy and token-level reinforcement learning. This makes CD a promising approach for alignment of language models.
Three-dimensional echo-shifted EPI with simultaneous blip-up and blip-down acquisitions for correcting geometric distortion
Aug 12, 2023Purpose: Echo-planar imaging (EPI) with blip-up/down acquisition (BUDA) can provide high-quality images with minimal distortions by using two readout trains with opposing phase-encoding gradients. Because of the need for two separate acquisitions, BUDA doubles the scan time and degrades the temporal resolution when compared to single-shot EPI, presenting a major challenge for many applications, particularly functional MRI (fMRI). This study aims at overcoming this challenge by developing an echo-shifted EPI BUDA (esEPI-BUDA) technique to acquire both blip-up and blip-down datasets in a single shot. Methods: A three-dimensional (3D) esEPI-BUDA pulse sequence was designed by using an echo-shifting strategy to produce two EPI readout trains. These readout trains produced a pair of k-space datasets whose k-space trajectories were interleaved with opposite phase-encoding gradient directions. The two k-space datasets were separately reconstructed using a 3D SENSE algorithm, from which time-resolved B0-field maps were derived using TOPUP in FSL and then input into a forward model of joint parallel imaging reconstruction to correct for geometric distortion. In addition, Hankel structured low-rank constraint was incorporated into the reconstruction framework to improve image quality by mitigating the phase errors between the two interleaved k-space datasets. Results: The 3D esEPI-BUDA technique was demonstrated in a phantom and an fMRI study on healthy human subjects. Geometric distortions were effectively corrected in both phantom and human brain images. In the fMRI study, the visual activation volumes and their BOLD responses were comparable to those from conventional 3D echo-planar images. Conclusion: The improved imaging efficiency and dynamic distortion correction capability afforded by 3D esEPI-BUDA are expected to benefit many EPI applications.
Contrastive Learning MRI Reconstruction
Jun 01, 2023

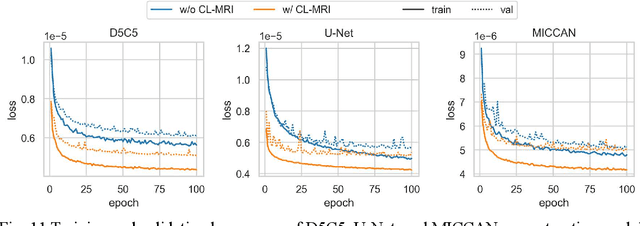

Purpose: We propose a novel contrastive learning latent space representation for MRI datasets with partially acquired scans. We show that this latent space can be utilized for accelerated MR image reconstruction. Theory and Methods: Our novel framework, referred to as COLADA (stands for Contrastive Learning for highly accelerated MR image reconstruction), maximizes the mutual information between differently accelerated images of an MRI scan by using self-supervised contrastive learning. In other words, it attempts to "pull" the latent representations of the same scan together and "push" the latent representations of other scans away. The generated MRI latent space is subsequently utilized for MR image reconstruction and the performance was assessed in comparison to several baseline deep learning reconstruction methods. Furthermore, the quality of the proposed latent space representation was analyzed using Alignment and Uniformity. Results: COLADA comprehensively outperformed other reconstruction methods with robustness to variations in undersampling patterns, pathological abnormalities, and noise in k-space during inference. COLADA proved the high quality of reconstruction on unseen data with minimal fine-tuning. The analysis of representation quality suggests that the contrastive features produced by COLADA are optimally distributed in latent space. Conclusion: To the best of our knowledge, this is the first attempt to utilize contrastive learning on differently accelerated images for MR image reconstruction. The proposed latent space representation has practical usage due to a large number of existing partially sampled datasets. This implies the possibility of exploring self-supervised contrastive learning further to enhance the latent space of MRI for image reconstruction.
Brainformers: Trading Simplicity for Efficiency
May 29, 2023



Transformers are central to recent successes in natural language processing and computer vision. Transformers have a mostly uniform backbone where layers alternate between feed-forward and self-attention in order to build a deep network. Here we investigate this design choice and find that more complex blocks that have different permutations of layer primitives can be more efficient. Using this insight, we develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms of layer normalization and activation functions. Brainformer consistently outperforms the state-of-the-art dense and sparse Transformers, in terms of both quality and efficiency. A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. In downstream task evaluation, Brainformer also demonstrates a 3% higher SuperGLUE score with fine-tuning compared to GLaM with a similar number of activated parameters. Finally, Brainformer largely outperforms a Primer dense model derived with NAS with similar computation per token on fewshot evaluations.