 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Controlled Decoding from Language Models
Oct 25, 2023



We propose controlled decoding (CD), a novel off-policy reinforcement learning method to control the autoregressive generation from language models towards high reward outcomes. CD solves an off-policy reinforcement learning problem through a value function for the reward, which we call a prefix scorer. The prefix scorer is used at inference time to steer the generation towards higher reward outcomes. We show that the prefix scorer may be trained on (possibly) off-policy data to predict the expected reward when decoding is continued from a partially decoded response. We empirically demonstrate that CD is effective as a control mechanism on Reddit conversations corpus. We also show that the modularity of the design of CD makes it possible to control for multiple rewards, effectively solving a multi-objective reinforcement learning problem with no additional complexity. Finally, we show that CD can be applied in a novel blockwise fashion at inference-time, again without the need for any training-time changes, essentially bridging the gap between the popular best-of-$K$ strategy and token-level reinforcement learning. This makes CD a promising approach for alignment of language models.
Using Machine Translation to Localize Task Oriented NLG Output
Jul 09, 2021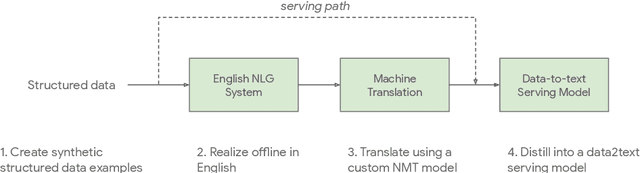
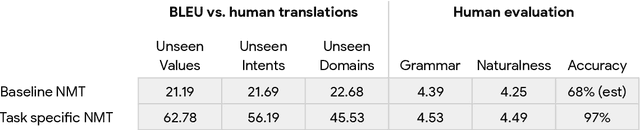
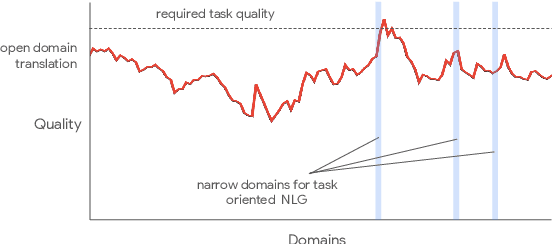
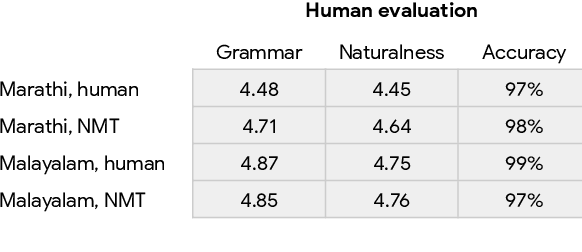
One of the challenges in a task oriented natural language application like the Google Assistant, Siri, or Alexa is to localize the output to many languages. This paper explores doing this by applying machine translation to the English output. Using machine translation is very scalable, as it can work with any English output and can handle dynamic text, but otherwise the problem is a poor fit. The required quality bar is close to perfection, the range of sentences is extremely narrow, and the sentences are often very different than the ones in the machine translation training data. This combination of requirements is novel in the field of domain adaptation for machine translation. We are able to reach the required quality bar by building on existing ideas and adding new ones: finetuning on in-domain translations, adding sentences from the Web, adding semantic annotations, and using automatic error detection. The paper shares our approach and results, together with a distillation model to serve the translation models at scale.
A Scalable Framework for Learning From Implicit User Feedback to Improve Natural Language Understanding in Large-Scale Conversational AI Systems
Oct 23, 2020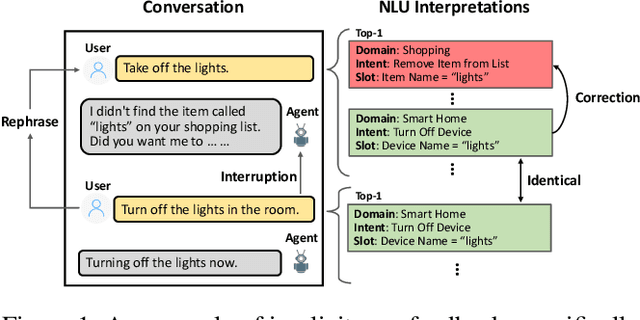
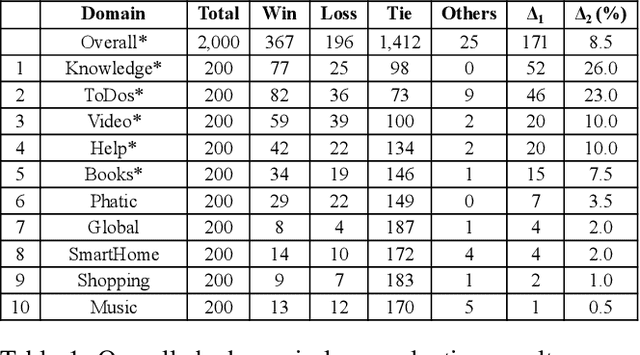
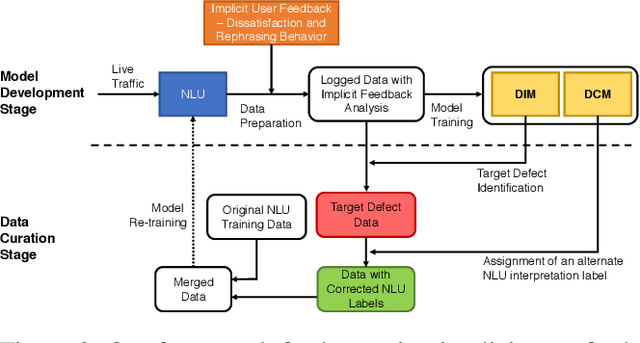
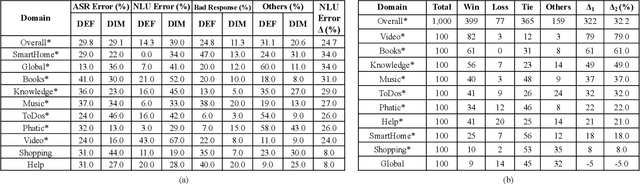
Natural Language Understanding (NLU) is an established component within a conversational AI or digital assistant system, and it is responsible for producing semantic understanding of a user request. We propose a scalable and automatic approach for improving NLU in a large-scale conversational AI system by leveraging implicit user feedback, with an insight that user interaction data and dialog context have rich information embedded from which user satisfaction and intention can be inferred. In particular, we propose a general domain-agnostic framework for curating new supervision data for improving NLU from live production traffic. With an extensive set of experiments, we show the results of applying the framework and improving NLU for a large-scale production system and show its impact across 10 domains.
Continuous Learning for Large-scale Personalized Domain Classification
May 02, 2019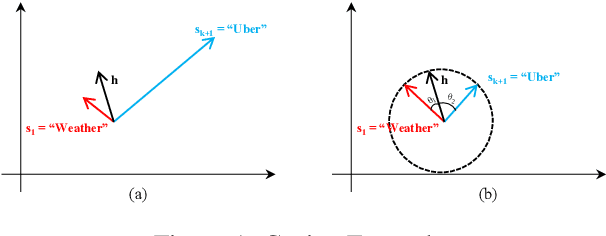

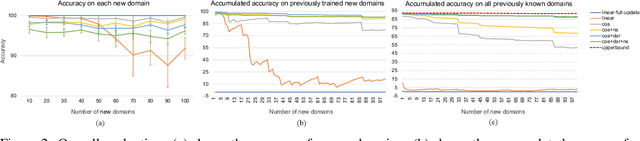

Domain classification is the task of mapping spoken language utterances to one of the natural language understanding domains in intelligent personal digital assistants (IPDAs). This is a major component in mainstream IPDAs in industry. Apart from official domains, thousands of third-party domains are also created by external developers to enhance the capability of IPDAs. As more domains are developed rapidly, the question of how to continuously accommodate the new domains still remains challenging. Moreover, existing continual learning approaches do not address the problem of incorporating personalized information dynamically for better domain classification. In this paper, we propose CoNDA, a neural network based approach for domain classification that supports incremental learning of new classes. Empirical evaluation shows that CoNDA achieves high accuracy and outperforms baselines by a large margin on both incrementally added new domains and existing domains.
Generalizing Word Embeddings using Bag of Subwords
Sep 12, 2018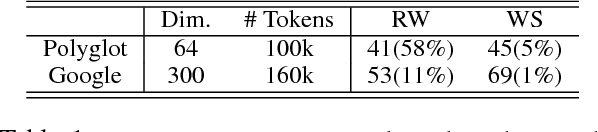
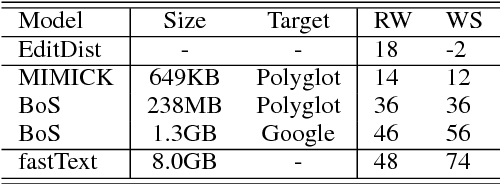
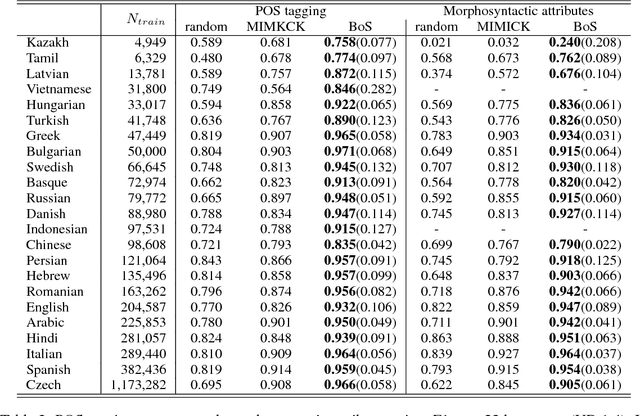
We approach the problem of generalizing pre-trained word embeddings beyond fixed-size vocabularies without using additional contextual information. We propose a subword-level word vector generation model that views words as bags of character $n$-grams. The model is simple, fast to train and provides good vectors for rare or unseen words. Experiments show that our model achieves state-of-the-art performances in English word similarity task and in joint prediction of part-of-speech tag and morphosyntactic attributes in 23 languages, suggesting our model's ability in capturing the relationship between words' textual representations and their embeddings.