 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Preferences Are Created Equal: Stability-Aware and Gradient-Efficient Alignment for Reasoning Models
Feb 01, 2026Preference-based alignment is pivotal for training large reasoning models; however, standard methods like Direct Preference Optimization (DPO) typically treat all preference pairs uniformly, overlooking the evolving utility of training instances. This static approach often leads to inefficient or unstable optimization, as it wastes computation on trivial pairs with negligible gradients and suffers from noise induced by samples near uncertain decision boundaries. Facing these challenges, we propose SAGE (Stability-Aware Gradient Efficiency), a dynamic framework designed to enhance alignment reliability by maximizing the Signal-to-Noise Ratio of policy updates. Concretely, SAGE integrates a coarse-grained curriculum mechanism that refreshes candidate pools based on model competence with a fine-grained, stability-aware scoring function that prioritizes informative, confident errors while filtering out unstable samples. Experiments on multiple mathematical reasoning benchmarks demonstrate that SAGE significantly accelerates convergence and outperforms static baselines, highlighting the critical role of policy-aware, stability-conscious data selection in reasoning alignment.
Mitigating Hallucinations in Video Large Language Models via Spatiotemporal-Semantic Contrastive Decoding
Jan 30, 2026Although Video Large Language Models perform remarkably well across tasks such as video understanding, question answering, and reasoning, they still suffer from the problem of hallucination, which refers to generating outputs that are inconsistent with explicit video content or factual evidence. However, existing decoding methods for mitigating video hallucinations, while considering the spatiotemporal characteristics of videos, mostly rely on heuristic designs. As a result, they fail to precisely capture the root causes of hallucinations and their fine-grained temporal and semantic correlations, leading to limited robustness and generalization in complex scenarios. To more effectively mitigate video hallucinations, we propose a novel decoding strategy termed Spatiotemporal-Semantic Contrastive Decoding. This strategy constructs negative features by deliberately disrupting the spatiotemporal consistency and semantic associations of video features, and suppresses video hallucinations through contrastive decoding against the original video features during inference. Extensive experiments demonstrate that our method not only effectively mitigates the occurrence of hallucinations, but also preserves the general video understanding and reasoning capabilities of the model.
$λ$-GRPO: Unifying the GRPO Frameworks with Learnable Token Preferences
Oct 08, 2025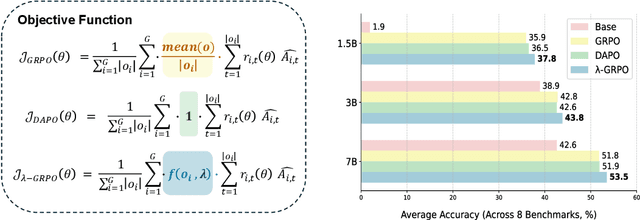
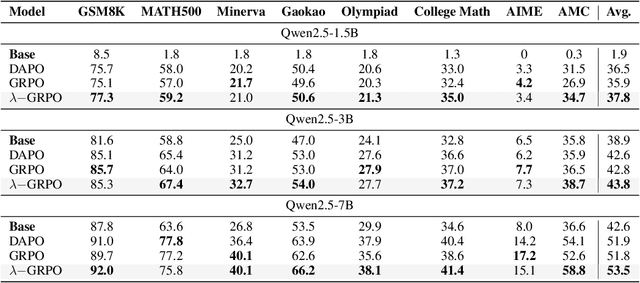
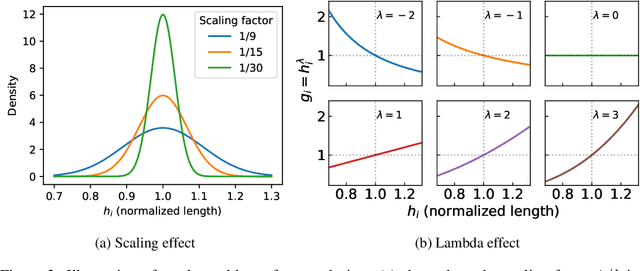

Reinforcement Learning with Human Feedback (RLHF) has been the dominant approach for improving the reasoning capabilities of Large Language Models (LLMs). Recently, Reinforcement Learning with Verifiable Rewards (RLVR) has simplified this paradigm by replacing the reward and value models with rule-based verifiers. A prominent example is Group Relative Policy Optimization (GRPO). However, GRPO inherently suffers from a length bias, since the same advantage is uniformly assigned to all tokens of a response. As a result, longer responses distribute the reward over more tokens and thus contribute disproportionately to gradient updates. Several variants, such as DAPO and Dr. GRPO, modify the token-level aggregation of the loss, yet these methods remain heuristic and offer limited interpretability regarding their implicit token preferences. In this work, we explore the possibility of allowing the model to learn its own token preference during optimization. We unify existing frameworks under a single formulation and introduce a learnable parameter $\lambda$ that adaptively controls token-level weighting. We use $\lambda$-GRPO to denote our method, and we find that $\lambda$-GRPO achieves consistent improvements over vanilla GRPO and DAPO on multiple mathematical reasoning benchmarks. On Qwen2.5 models with 1.5B, 3B, and 7B parameters, $\lambda$-GRPO improves average accuracy by $+1.9\%$, $+1.0\%$, and $+1.7\%$ compared to GRPO, respectively. Importantly, these gains come without any modifications to the training data or additional computational cost, highlighting the effectiveness and practicality of learning token preferences.
Staying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding
Sep 08, 2025Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in enhancing the reasoning capabilities of large language models (LLMs). However, existing RLVR methods often suffer from exploration inefficiency due to mismatches between the training data's difficulty and the model's capability. LLMs fail to discover viable reasoning paths when problems are overly difficult, while learning little new capability when problems are too simple. In this work, we formalize the impact of problem difficulty by quantifying the relationship between loss descent speed and rollout accuracy. Building on this analysis, we propose SEELE, a novel supervision-aided RLVR framework that dynamically adjusts problem difficulty to stay within the high-efficiency region. SEELE augments each training sample by appending a hint (part of a full solution) after the original problem. Unlike previous hint-based approaches, SEELE deliberately and adaptively adjusts the hint length for each problem to achieve an optimal difficulty. To determine the optimal hint length, SEELE employs a multi-round rollout sampling strategy. In each round, it fits an item response theory model to the accuracy-hint pairs collected in preceding rounds to predict the required hint length for the next round. This instance-level, real-time difficulty adjustment aligns problem difficulty with the evolving model capability, thereby improving exploration efficiency. Experimental results show that SEELE outperforms Group Relative Policy Optimization (GRPO) and Supervised Fine-tuning (SFT) by +11.8 and +10.5 points, respectively, and surpasses the best previous supervision-aided approach by +3.6 points on average across six math reasoning benchmarks.
Pretraining on the Test Set Is No Longer All You Need: A Debate-Driven Approach to QA Benchmarks
Jul 23, 2025As frontier language models increasingly saturate standard QA benchmarks, concerns about data contamination, memorization, and escalating dataset creation costs persist. We propose a debate-driven evaluation paradigm that transforms any existing QA dataset into structured adversarial debates--where one model is given the official answer to defend, and another constructs and defends an alternative answer--adjudicated by a judge model blind to the correct solution. By forcing multi-round argumentation, this approach substantially increases difficulty while penalizing shallow memorization, yet reuses QA items to reduce curation overhead. We make two main contributions: (1) an evaluation pipeline to systematically convert QA tasks into debate-based assessments, and (2) a public benchmark that demonstrates our paradigm's effectiveness on a subset of MMLU-Pro questions, complete with standardized protocols and reference models. Empirical results validate the robustness of the method and its effectiveness against data contamination--a Llama 3.1 model fine-tuned on test questions showed dramatic accuracy improvements (50% -> 82%) but performed worse in debates. Results also show that even weaker judges can reliably differentiate stronger debaters, highlighting how debate-based evaluation can scale to future, more capable systems while maintaining a fraction of the cost of creating new benchmarks. Overall, our framework underscores that "pretraining on the test set is no longer all you need," offering a sustainable path for measuring the genuine reasoning ability of advanced language models.
Multi-Preference Lambda-weighted Listwise DPO for Dynamic Preference Alignment
Jun 24, 2025While large-scale unsupervised language models (LMs) capture broad world knowledge and reasoning capabilities, steering their behavior toward desired objectives remains challenging due to the lack of explicit supervision. Existing alignment techniques, such as reinforcement learning from human feedback (RLHF), rely on training a reward model and performing reinforcement learning to align with human preferences. However, RLHF is often computationally intensive, unstable, and sensitive to hyperparameters. To address these limitations, Direct Preference Optimization (DPO) was introduced as a lightweight and stable alternative, enabling direct alignment of language models with pairwise preference data via classification loss. However, DPO and its extensions generally assume a single static preference distribution, limiting flexibility in multi-objective or dynamic alignment settings. In this paper, we propose a novel framework: Multi-Preference Lambda-weighted Listwise DPO, which extends DPO to incorporate multiple human preference dimensions (e.g., helpfulness, harmlessness, informativeness) and enables dynamic interpolation through a controllable simplex-weighted formulation. Our method supports both listwise preference feedback and flexible alignment across varying user intents without re-training. Empirical and theoretical analysis demonstrates that our method is as effective as traditional DPO on static objectives while offering greater generality and adaptability for real-world deployment.
PreP-OCR: A Complete Pipeline for Document Image Restoration and Enhanced OCR Accuracy
May 28, 2025This paper introduces PreP-OCR, a two-stage pipeline that combines document image restoration with semantic-aware post-OCR correction to enhance both visual clarity and textual consistency, thereby improving text extraction from degraded historical documents. First, we synthesize document-image pairs from plaintext, rendering them with diverse fonts and layouts and then applying a randomly ordered set of degradation operations. An image restoration model is trained on this synthetic data, using multi-directional patch extraction and fusion to process large images. Second, a ByT5 post-OCR model, fine-tuned on synthetic historical text pairs, addresses remaining OCR errors. Detailed experiments on 13,831 pages of real historical documents in English, French, and Spanish show that the PreP-OCR pipeline reduces character error rates by 63.9-70.3% compared to OCR on raw images. Our pipeline demonstrates the potential of integrating image restoration with linguistic error correction for digitizing historical archives.
UORA: Uniform Orthogonal Reinitialization Adaptation in Parameter-Efficient Fine-Tuning of Large Models
May 26, 2025This paper introduces Uniform Orthogonal Reinitialization Adaptation (UORA), a novel parameter-efficient fine-tuning (PEFT) approach for Large Language Models (LLMs). UORA achieves state-of-the-art performance and parameter efficiency by leveraging a low-rank approximation method to reduce the number of trainable parameters. Unlike existing methods such as LoRA and VeRA, UORA employs an interpolation-based reparametrization mechanism that selectively reinitializes rows and columns in frozen projection matrices, guided by the vector magnitude heuristic. This results in substantially fewer trainable parameters compared to LoRA and outperforms VeRA in computation and storage efficiency. Comprehensive experiments across various benchmarks demonstrate UORA's superiority in achieving competitive fine-tuning performance with negligible computational overhead. We demonstrate its performance on GLUE and E2E benchmarks and its effectiveness in instruction-tuning large language models and image classification models. Our contributions establish a new paradigm for scalable and resource-efficient fine-tuning of LLMs.
* 20 pages, 2 figures, 15 tables
Sequence-level Large Language Model Training with Contrastive Preference Optimization
Feb 23, 2025



The next token prediction loss is the dominant self-supervised training objective for large language models and has achieved promising results in a variety of downstream tasks. However, upon closer investigation of this objective, we find that it lacks an understanding of sequence-level signals, leading to a mismatch between training and inference processes. To bridge this gap, we introduce a contrastive preference optimization (CPO) procedure that can inject sequence-level information into the language model at any training stage without expensive human labeled data. Our experiments show that the proposed objective surpasses the next token prediction in terms of win rate in the instruction-following and text generation tasks.
False Discovery Rate Control via Frequentist-assisted Horseshoe
Feb 08, 2025The horseshoe prior, a widely used handy alternative to the spike-and-slab prior, has proven to be an exceptional default global-local shrinkage prior in Bayesian inference and machine learning. However, designing tests with frequentist false discovery rate (FDR) control using the horseshoe prior or the general class of global-local shrinkage priors remains an open problem. In this paper, we propose a frequentist-assisted horseshoe procedure that not only resolves this long-standing FDR control issue for the high dimensional normal means testing problem but also exhibits satisfactory finite-sample FDR control under any desired nominal level for both large-scale multiple independent and correlated tests. We carry out the frequentist-assisted horseshoe procedure in an easy and intuitive way by using the minimax estimator of the global parameter of the horseshoe prior while maintaining the remaining full Bayes vanilla horseshoe structure. The results of both intensive simulations under different sparsity levels, and real-world data demonstrate that the frequentist-assisted horseshoe procedure consistently achieves robust finite-sample FDR control. Existing frequentist or Bayesian FDR control procedures can lose finite-sample FDR control in a variety of common sparse cases. Based on the intimate relationship between the minimax estimation and the level of FDR control discovered in this work, we point out potential generalizations to achieve FDR control for both more complicated models and the general global-local shrinkage prior family.