 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Test-Time Adaptation with Bayesian Conditional Priors
Jun 11, 2026Multi-label recognition with frozen Vision-Language Models (VLMs) is brittle under distribution shift: standard zero-shot inference scores labels independently, ignoring co-occurrence structure and producing incoherent label sets where dominant concepts suppress weaker but compatible labels. We introduce Bayesian Conditional Priors (BCP) Estimation, a gradient-free test-time adaptation method that injects label dependency without tuning the backbone. BCP views zero-shot logits as a proxy for marginal posteriors under a fixed image-text likelihood and attributes shift-induced errors mainly to a mismatched label prior. For each test image, it selects a high-confidence anchor label and applies an anchor-conditioned Bayesian refinement. This update is closed-form in logit space and admits a pointwise mutual information (PMI) interpretation, explicitly promoting compatible labels and suppressing incompatible ones. BCP operates without target annotations by estimating anchor-conditioned priors online from the unlabeled test stream via lightweight second-order co-occurrence statistics, adding negligible overhead beyond a single forward pass. Across standard multi-label benchmarks and multiple CLIP backbones, BCP consistently outperforms strong TTA baselines, e.g., improving RN50 average mAP from 57.31 to 69.22 and ViT-B/16 from 62.61 to 71.79.
Towards Fine-grained Temporal Perception: Post-Training Large Audio-Language Models with Audio-Side Time Prompt
Apr 15, 2026Large Audio-Language Models (LALMs) enable general audio understanding and demonstrate remarkable performance across various audio tasks. However, these models still face challenges in temporal perception (e.g., inferring event onset and offset), leading to limited utility in fine-grained scenarios. To address this issue, we propose Audio-Side Time Prompt and leverage Reinforcement Learning (RL) to develop the TimePro-RL framework for fine-grained temporal perception. Specifically, we encode timestamps as embeddings and interleave them within the audio feature sequence as temporal coordinates to prompt the model. Furthermore, we introduce RL following Supervised Fine-Tuning (SFT) to directly optimize temporal alignment performance. Experiments demonstrate that TimePro-RL achieves significant performance gains across a range of audio temporal tasks, such as audio grounding, sound event detection, and dense audio captioning, validating its robust effectiveness.
Spectrogram features for audio and speech analysis
Mar 16, 2026Spectrogram-based representations have grown to dominate the feature space for deep learning audio analysis systems, and are often adopted for speech analysis also. Initially, the primary motivator for spectrogram-based representations was their ability to present sound as a two dimensional signal in the time-frequency plane, which not only provides an interpretable physical basis for analysing sound, but also unlocks the use of a wide range of machine learning techniques such as convolutional neural networks, that had been developed for image processing. A spectrogram is a matrix characterised by the resolution and span of its two dimensions, as well as by the representation and scaling of each element. Many possibilities for these three characteristics have been explored by researchers across numerous application areas, with different settings showing affinity for various tasks. This paper reviews the use of spectrogram-based representations and surveys the state-of-the-art to question how front-end feature representation choice allies with back-end classifier architecture for different tasks.
* 30 pages
Online unsupervised Hebbian learning in deep photonic neuromorphic networks
Jan 29, 2026While software implementations of neural networks have driven significant advances in computation, the von Neumann architecture imposes fundamental limitations on speed and energy efficiency. Neuromorphic networks, with structures inspired by the brain's architecture, offer a compelling solution with the potential to approach the extreme energy efficiency of neurobiological systems. Photonic neuromorphic networks (PNNs) are particularly attractive because they leverage the inherent advantages of light, namely high parallelism, low latency, and exceptional energy efficiency. Previous PNN demonstrations have largely focused on device-level functionalities or system-level implementations reliant on supervised learning and inefficient optical-electrical-optical (OEO) conversions. Here, we introduce a purely photonic deep PNN architecture that enables online, unsupervised learning. We propose a local feedback mechanism operating entirely in the optical domain that implements a Hebbian learning rule using non-volatile phase-change material synapses. We experimentally demonstrate this approach on a non-trivial letter recognition task using a commercially available fiber-optic platform and achieve a 100 percent recognition rate, showcasing an all-optical solution for efficient, real-time information processing. This work unlocks the potential of photonic computing for complex artificial intelligence applications by enabling direct, high-throughput processing of optical information without intermediate OEO signal conversions.
RegionMarker: A Region-Triggered Semantic Watermarking Framework for Embedding-as-a-Service Copyright Protection
Nov 17, 2025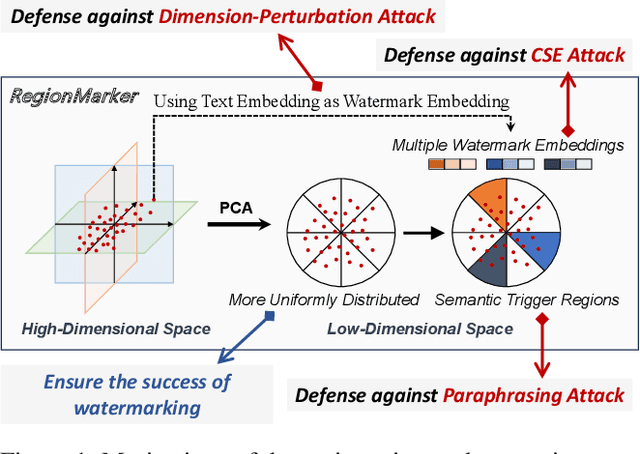

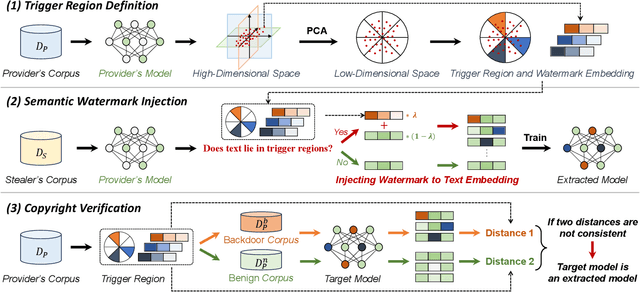
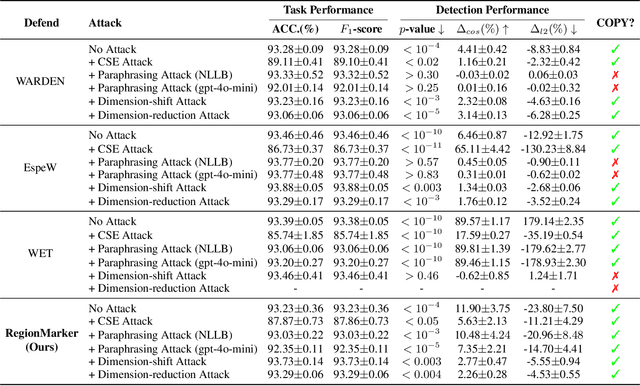
Embedding-as-a-Service (EaaS) is an effective and convenient deployment solution for addressing various NLP tasks. Nevertheless, recent research has shown that EaaS is vulnerable to model extraction attacks, which could lead to significant economic losses for model providers. For copyright protection, existing methods inject watermark embeddings into text embeddings and use them to detect copyright infringement. However, current watermarking methods often resist only a subset of attacks and fail to provide \textit{comprehensive} protection. To this end, we present the region-triggered semantic watermarking framework called RegionMarker, which defines trigger regions within a low-dimensional space and injects watermarks into text embeddings associated with these regions. By utilizing a secret dimensionality reduction matrix to project onto this subspace and randomly selecting trigger regions, RegionMarker makes it difficult for watermark removal attacks to evade detection. Furthermore, by embedding watermarks across the entire trigger region and using the text embedding as the watermark, RegionMarker is resilient to both paraphrasing and dimension-perturbation attacks. Extensive experiments on various datasets show that RegionMarker is effective in resisting different attack methods, thereby protecting the copyright of EaaS.
Steering When Necessary: Flexible Steering Large Language Models with Backtracking
Aug 25, 2025Large language models (LLMs) have achieved remarkable performance across many generation tasks. Nevertheless, effectively aligning them with desired behaviors remains a significant challenge. Activation steering is an effective and cost-efficient approach that directly modifies the activations of LLMs during the inference stage, aligning their responses with the desired behaviors and avoiding the high cost of fine-tuning. Existing methods typically indiscriminately intervene to all generations or rely solely on the question to determine intervention, which limits the accurate assessment of the intervention strength. To this end, we propose the Flexible Activation Steering with Backtracking (FASB) framework, which dynamically determines both the necessity and strength of intervention by tracking the internal states of the LLMs during generation, considering both the question and the generated content. Since intervening after detecting a deviation from the desired behavior is often too late, we further propose the backtracking mechanism to correct the deviated tokens and steer the LLMs toward the desired behavior. Extensive experiments on the TruthfulQA dataset and six multiple-choice datasets demonstrate that our method outperforms baselines. Our code will be released at https://github.com/gjw185/FASB.
Contrastive Prompting Enhances Sentence Embeddings in LLMs through Inference-Time Steering
May 19, 2025Extracting sentence embeddings from large language models (LLMs) is a practical direction, as it requires neither additional data nor fine-tuning. Previous studies usually focus on prompt engineering to guide LLMs to encode the core semantic information of the sentence into the embedding of the last token. However, the last token in these methods still encodes an excess of non-essential information, such as stop words, limiting its encoding capacity. To this end, we propose a Contrastive Prompting (CP) method that introduces an extra auxiliary prompt to elicit better sentence embedding. By contrasting with the auxiliary prompt, CP can steer existing prompts to encode the core semantics of the sentence, rather than non-essential information. CP is a plug-and-play inference-time intervention method that can be combined with various prompt-based methods. Extensive experiments on Semantic Textual Similarity (STS) tasks and downstream classification tasks demonstrate that our method can improve the performance of existing prompt-based methods across different LLMs. Our code will be released at https://github.com/zifengcheng/CP.
Implicit Location-Caption Alignment via Complementary Masking for Weakly-Supervised Dense Video Captioning
Dec 17, 2024



Weakly-Supervised Dense Video Captioning (WSDVC) aims to localize and describe all events of interest in a video without requiring annotations of event boundaries. This setting poses a great challenge in accurately locating the temporal location of event, as the relevant supervision is unavailable. Existing methods rely on explicit alignment constraints between event locations and captions, which involve complex event proposal procedures during both training and inference. To tackle this problem, we propose a novel implicit location-caption alignment paradigm by complementary masking, which simplifies the complex event proposal and localization process while maintaining effectiveness. Specifically, our model comprises two components: a dual-mode video captioning module and a mask generation module. The dual-mode video captioning module captures global event information and generates descriptive captions, while the mask generation module generates differentiable positive and negative masks for localizing the events. These masks enable the implicit alignment of event locations and captions by ensuring that captions generated from positively and negatively masked videos are complementary, thereby forming a complete video description. In this way, even under weak supervision, the event location and event caption can be aligned implicitly. Extensive experiments on the public datasets demonstrate that our method outperforms existing weakly-supervised methods and achieves competitive results compared to fully-supervised methods.
Token Prepending: A Training-Free Approach for Eliciting Better Sentence Embeddings from LLMs
Dec 16, 2024Extracting sentence embeddings from large language models (LLMs) is a promising direction, as LLMs have demonstrated stronger semantic understanding capabilities. Previous studies typically focus on prompt engineering to elicit sentence embeddings from LLMs by prompting the model to encode sentence information into the embedding of the last token. However, LLMs are mostly decoder-only models with causal attention and the earlier tokens in the sentence cannot attend to the latter tokens, resulting in biased encoding of sentence information and cascading effects on the final decoded token. To this end, we propose a novel Token Prepending (TP) technique that prepends each layer's decoded sentence embedding to the beginning of the sentence in the next layer's input, allowing earlier tokens to attend to the complete sentence information under the causal attention mechanism. The proposed TP technique is a plug-and-play and training-free technique, which means it can be seamlessly integrated with various prompt-based sentence embedding methods and autoregressive LLMs. Extensive experiments on various Semantic Textual Similarity (STS) tasks and downstream classification tasks demonstrate that our proposed TP technique can significantly improve the performance of existing prompt-based sentence embedding methods across different LLMs, while incurring negligible additional inference cost.
Prototype based Masked Audio Model for Self-Supervised Learning of Sound Event Detection
Sep 26, 2024



A significant challenge in sound event detection (SED) is the effective utilization of unlabeled data, given the limited availability of labeled data due to high annotation costs. Semi-supervised algorithms rely on labeled data to learn from unlabeled data, and the performance is constrained by the quality and size of the former. In this paper, we introduce the Prototype based Masked Audio Model~(PMAM) algorithm for self-supervised representation learning in SED, to better exploit unlabeled data. Specifically, semantically rich frame-level pseudo labels are constructed from a Gaussian mixture model (GMM) based prototypical distribution modeling. These pseudo labels supervise the learning of a Transformer-based masked audio model, in which binary cross-entropy loss is employed instead of the widely used InfoNCE loss, to provide independent loss contributions from different prototypes, which is important in real scenarios in which multiple labels may apply to unsupervised data frames. A final stage of fine-tuning with just a small amount of labeled data yields a very high performing SED model. On like-for-like tests using the DESED task, our method achieves a PSDS1 score of 62.5\%, surpassing current state-of-the-art models and demonstrating the superiority of the proposed technique.