 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning from Delayed Marketplace Feedback for Objective-Weight Adaptation in Three-Sided Dispatch
Jun 11, 2026Dispatch in three-sided marketplaces provides a natural setting for reinforcement learning from world feedback: decisions are evaluated by delayed operational outcomes such as delivery speed, courier utilization, and merchant congestion. We present a deployed reinforcement learning system at DoorDash that adapts dispatch objective weights in a large-scale food-delivery marketplace using delayed signals. Rather than replacing the combinatorial assignment optimizer, a store-level policy learned from logged marketplace data selects a discrete multiplier that shifts the dispatch optimizer's tradeoff between delivery quality and batching efficiency. This interface enables offline policy learning under noisy, delayed, and coupled feedback while preserving production feasibility constraints and operational safeguards. We train a shared value function using centralized offline data and decentralized store-level execution, with Double Q-learning targets and a conservative regularizer to reduce out-of-distribution value overestimation. In a production switchback experiment, the offline-trained policy increases batching and reduces courier-side time costs without degrading customer-facing delivery quality. Results illustrate how world feedback from a live economic and logistics system can be used to safely adapt decision policies online.
Operator learning on domain boundary through combining fundamental solution-based artificial data and boundary integral techniques
Jan 16, 2026For linear partial differential equations with known fundamental solutions, this work introduces a novel operator learning framework that relies exclusively on domain boundary data, including solution values and normal derivatives, rather than full-domain sampling. By integrating the previously developed Mathematical Artificial Data (MAD) method, which enforces physical consistency, all training data are synthesized directly from the fundamental solutions of the target problems, resulting in a fully data-driven pipeline without the need for external measurements or numerical simulations. We refer to this approach as the Mathematical Artificial Data Boundary Neural Operator (MAD-BNO), which learns boundary-to-boundary mappings using MAD-generated Dirichlet-Neumann data pairs. Once trained, the interior solution at arbitrary locations can be efficiently recovered through boundary integral formulations, supporting Dirichlet, Neumann, and mixed boundary conditions as well as general source terms. The proposed method is validated on benchmark operator learning tasks for two-dimensional Laplace, Poisson, and Helmholtz equations, where it achieves accuracy comparable to or better than existing neural operator approaches while significantly reducing training time. The framework is naturally extensible to three-dimensional problems and complex geometries.
Hierarchically Block-Sparse Recovery With Prior Support Information
Nov 09, 2025We provide new recovery bounds for hierarchical compressed sensing (HCS) based on prior support information (PSI). A detailed PSI-enabled reconstruction model is formulated using various forms of PSI. The hierarchical block orthogonal matching pursuit with PSI (HiBOMP-P) algorithm is designed in a recursive form to reliably recover hierarchically block-sparse signals. We derive exact recovery conditions (ERCs) measured by the mutual incoherence property (MIP), wherein hierarchical MIP concepts are proposed, and further develop reconstructible sparsity levels to reveal sufficient conditions for ERCs. Leveraging these MIP analyses, we present several extended insights, including reliable recovery conditions in noisy scenarios and the optimal hierarchical structure for cases where sparsity is not equal to zero. Our results further confirm that HCS offers improved recovery performance even when the prior information does not overlap with the true support set, whereas existing methods heavily rely on this overlap, thereby compromising performance if it is absent.
Two-timescale Beamforming Optimization for Downlink Multi-user Holographic MIMO Surfaces
Nov 07, 2025Benefiting from the rapid development of metamaterials and metasurfaces, the holographic multiple-input and multiple-output surface (HMIMOS) has been regarded as a promising solution for future wireless networks recently. By densely packing numerous radiation elements together, HMIMOS is capable of realizing accurate beamforming with low hardware complexity. However, enormous radiation elements on the HMIMOS lead to high computational complexity and signaling overhead when applying traditional beamforming schemes relying on instantaneous channel state information (CSI). To tackle this problem, we propose a two-timescale optimization scheme to minimize the required transmission power under the constraint of all users' quality-of-service (QoS). Specifically, the beampatterns at the base station (BS) and the user equippment (UE) are optimized over the slowly changing statistical CSI based on the constrained stochastic successive convex approximation (CSSCA) algorithm. Then, the instantaneous CSI is utilized to design the precoding matrix in order to ensure the system performance without significant increase in computational cost, due to the small number of feeds on the HMIMOS. Simulation results demonstrate the effectiveness of our proposed method compared to other baselines.
* This manuscript has been accepted by IEEE Transactions on Vehicular Technology (IEEE TVT)
New Paradigm for Unified Near-Field and Far-Field Wireless Communications
Jan 06, 2025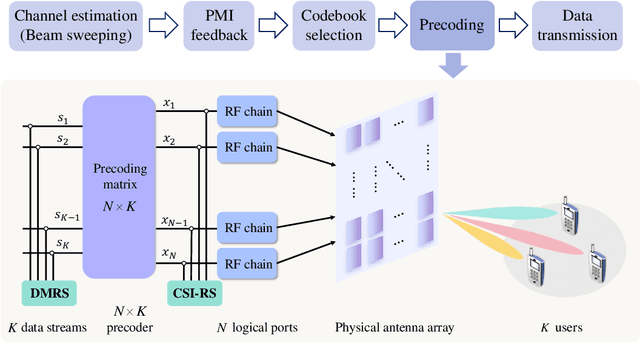

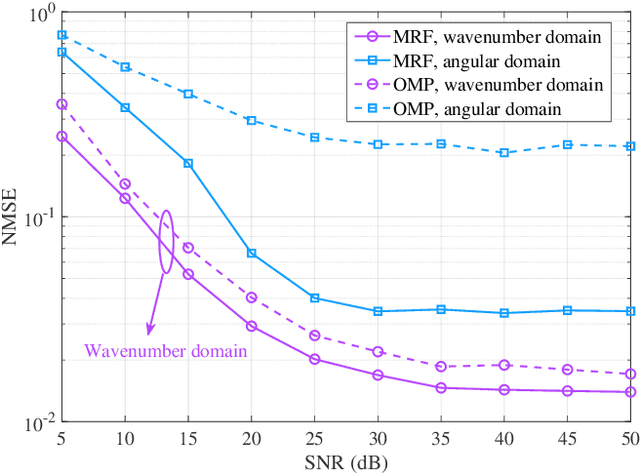

Current Type I and Type II codebooks in fifth generation (5G) wireless communications are limited in supporting the coexistence of far-field and near-field user equipments, as they are exclusively designed for far-field scenarios. To fill this knowledge gap and encourage relevant proposals by the 3rd Generation Partnership Project (3GPP), this article provides a novel codebook to facilitate a unified paradigm for the coexistence of far-field and near-field contexts. It ensures efficient precoding for all user equipments (UEs), while removing the need for the base station to identify whether one specific UE stays in either near-field or far-field regions. Additionally, our proposed codebook ensures compliance with current 3GPP standards for working flow and reference signals. Simulation results demonstrate the superior performance and versatility of our proposed codebook, validating its effectiveness in unifying near-field and far-field precoding for sixth-generation (6G) multiple-input multiple-output (MIMO) systems.
ConDSeg: A General Medical Image Segmentation Framework via Contrast-Driven Feature Enhancement
Dec 11, 2024



Medical image segmentation plays an important role in clinical decision making, treatment planning, and disease tracking. However, it still faces two major challenges. On the one hand, there is often a ``soft boundary'' between foreground and background in medical images, with poor illumination and low contrast further reducing the distinguishability of foreground and background within the image. On the other hand, co-occurrence phenomena are widespread in medical images, and learning these features is misleading to the model's judgment. To address these challenges, we propose a general framework called Contrast-Driven Medical Image Segmentation (ConDSeg). First, we develop a contrastive training strategy called Consistency Reinforcement. It is designed to improve the encoder's robustness in various illumination and contrast scenarios, enabling the model to extract high-quality features even in adverse environments. Second, we introduce a Semantic Information Decoupling module, which is able to decouple features from the encoder into foreground, background, and uncertainty regions, gradually acquiring the ability to reduce uncertainty during training. The Contrast-Driven Feature Aggregation module then contrasts the foreground and background features to guide multi-level feature fusion and key feature enhancement, further distinguishing the entities to be segmented. We also propose a Size-Aware Decoder to solve the scale singularity of the decoder. It accurately locate entities of different sizes in the image, thus avoiding erroneous learning of co-occurrence features. Extensive experiments on five medical image datasets across three scenarios demonstrate the state-of-the-art performance of our method, proving its advanced nature and general applicability to various medical image segmentation scenarios. Our released code is available at \url{https://github.com/Mengqi-Lei/ConDSeg}.
USTC-KXDIGIT System Description for ASVspoof5 Challenge
Sep 03, 2024
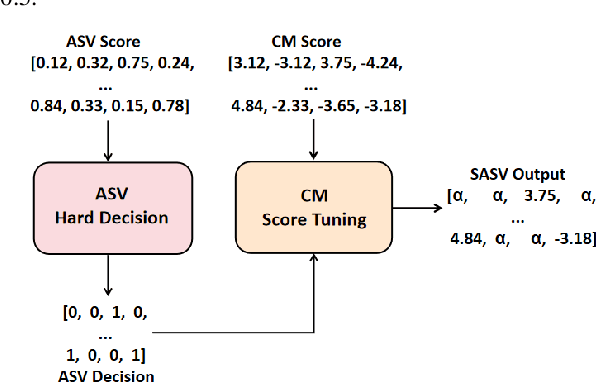
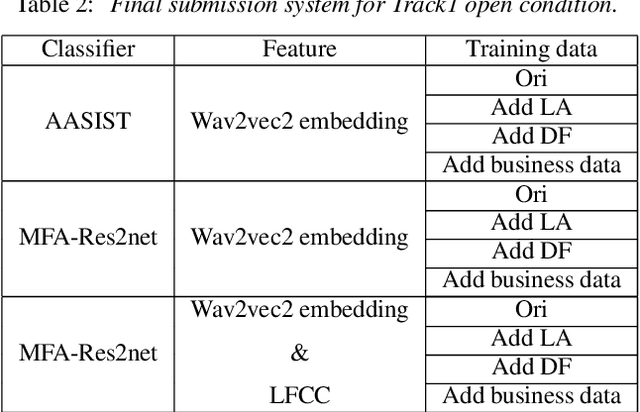
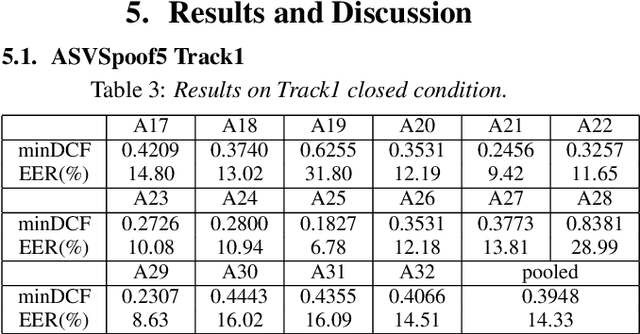
This paper describes the USTC-KXDIGIT system submitted to the ASVspoof5 Challenge for Track 1 (speech deepfake detection) and Track 2 (spoofing-robust automatic speaker verification, SASV). Track 1 showcases a diverse range of technical qualities from potential processing algorithms and includes both open and closed conditions. For these conditions, our system consists of a cascade of a frontend feature extractor and a back-end classifier. We focus on extensive embedding engineering and enhancing the generalization of the back-end classifier model. Specifically, the embedding engineering is based on hand-crafted features and speech representations from a self-supervised model, used for closed and open conditions, respectively. To detect spoof attacks under various adversarial conditions, we trained multiple systems on an augmented training set. Additionally, we used voice conversion technology to synthesize fake audio from genuine audio in the training set to enrich the synthesis algorithms. To leverage the complementary information learned by different model architectures, we employed activation ensemble and fused scores from different systems to obtain the final decision score for spoof detection. During the evaluation phase, the proposed methods achieved 0.3948 minDCF and 14.33% EER in the close condition, and 0.0750 minDCF and 2.59% EER in the open condition, demonstrating the robustness of our submitted systems under adversarial conditions. In Track 2, we continued using the CM system from Track 1 and fused it with a CNN-based ASV system. This approach achieved 0.2814 min-aDCF in the closed condition and 0.0756 min-aDCF in the open condition, showcasing superior performance in the SASV system.
Near-Field Channel Estimation in Dual-Band XL-MIMO with Side Information-Assisted Compressed Sensing
Mar 19, 2024
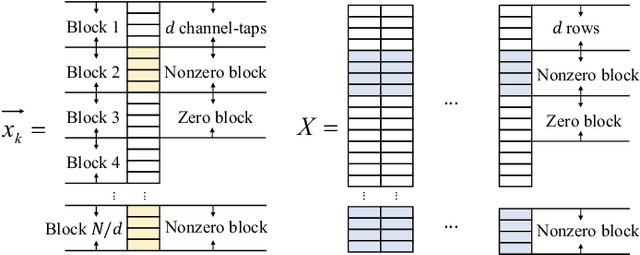


Near-field communication comes to be an indispensable part of the future sixth generation (6G) communications at the arrival of the forth-coming deployment of extremely large-scale multiple-input-multiple-output (XL-MIMO) systems. Due to the substantial number of antennas, the electromagnetic radiation field is modeled by the spherical waves instead of the conventional planar waves, leading to severe weak sparsity to angular-domain near-field channel. Therefore, the channel estimation reminiscent of the conventional compression sensing (CS) approaches in the angular domain, judiciously utilized for low pilot overhead, may result in unprecedented challenges. To this end, this paper proposes a brand-new near-field channel estimation scheme by exploiting the naturally occurring useful side information. Specifically, we formulate the dual-band near-field communication model based on the fact that high-frequency systems are likely to be deployed with lower-frequency systems. Representative side information, i.e., the structural characteristic information derived by the sparsity ambiguity and the out-of-band spatial information stemming from the lower-frequency channel, is explored and tailored to materialize exceptional near-field channel estimation. Furthermore, in-depth theoretical analyses are developed to guarantee the minimum estimation error, based on which a suite of algorithms leveraging the elaborating side information are proposed. Numerical simulations demonstrate that the designed algorithms provide more assured results than the off-the-shelf approaches in the context of the dual-band near-field communications in both on- and off-grid scenarios, where the angle of departures/arrivals are discretely or continuously distributed, respectively.
SafeAR: Towards Safer Algorithmic Recourse by Risk-Aware Policies
Aug 23, 2023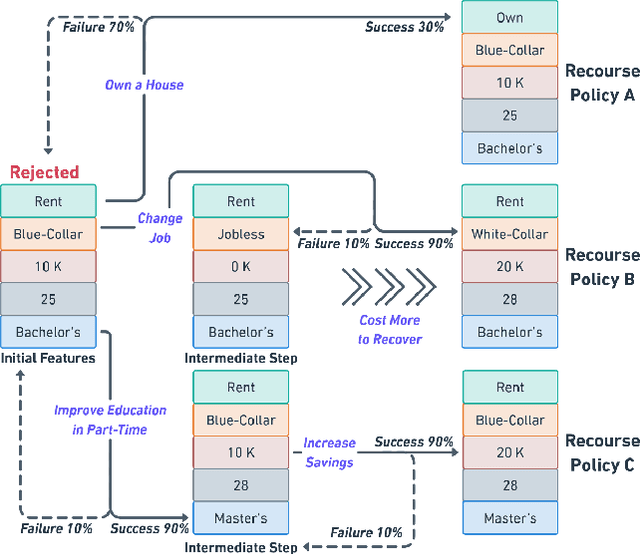
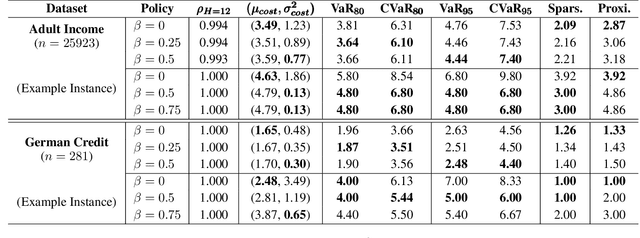
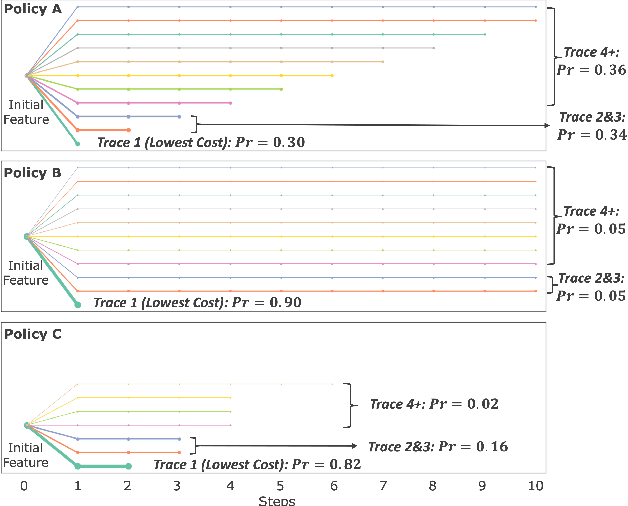

With the growing use of machine learning (ML) models in critical domains such as finance and healthcare, the need to offer recourse for those adversely affected by the decisions of ML models has become more important; individuals ought to be provided with recommendations on actions to take for improving their situation and thus receive a favorable decision. Prior work on sequential algorithmic recourse -- which recommends a series of changes -- focuses on action feasibility and uses the proximity of feature changes to determine action costs. However, the uncertainties of feature changes and the risk of higher than average costs in recourse have not been considered. It is undesirable if a recourse could (with some probability) result in a worse situation from which recovery requires an extremely high cost. It is essential to incorporate risks when computing and evaluating recourse. We call the recourse computed with such risk considerations as Safer Algorithmic Recourse (SafeAR). The objective is to empower people to choose a recourse based on their risk tolerance. In this work, we discuss and show how existing recourse desiderata can fail to capture the risk of higher costs. We present a method to compute recourse policies that consider variability in cost and connect algorithmic recourse literature with risk-sensitive reinforcement learning. We also adopt measures ``Value at Risk'' and ``Conditional Value at Risk'' from the financial literature to summarize risk concisely. We apply our method to two real-world datasets and compare policies with different levels of risk-aversion using risk measures and recourse desiderata (sparsity and proximity).
Multiagent Inverse Reinforcement Learning via Theory of Mind Reasoning
Mar 01, 2023We approach the problem of understanding how people interact with each other in collaborative settings, especially when individuals know little about their teammates, via Multiagent Inverse Reinforcement Learning (MIRL), where the goal is to infer the reward functions guiding the behavior of each individual given trajectories of a team's behavior during some task. Unlike current MIRL approaches, we do not assume that team members know each other's goals a priori; rather, that they collaborate by adapting to the goals of others perceived by observing their behavior, all while jointly performing a task. To address this problem, we propose a novel approach to MIRL via Theory of Mind (MIRL-ToM). For each agent, we first use ToM reasoning to estimate a posterior distribution over baseline reward profiles given their demonstrated behavior. We then perform MIRL via decentralized equilibrium by employing single-agent Maximum Entropy IRL to infer a reward function for each agent, where we simulate the behavior of other teammates according to the time-varying distribution over profiles. We evaluate our approach in a simulated 2-player search-and-rescue operation where the goal of the agents, playing different roles, is to search for and evacuate victims in the environment. Our results show that the choice of baseline profiles is paramount to the recovery of the ground-truth rewards, and that MIRL-ToM is able to recover the rewards used by agents interacting both with known and unknown teammates.