 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToMCAT: Theory-of-Mind for Cooperative Agents in Teams via Multiagent Diffusion Policies
Feb 25, 2025In this paper we present ToMCAT (Theory-of-Mind for Cooperative Agents in Teams), a new framework for generating ToM-conditioned trajectories. It combines a meta-learning mechanism, that performs ToM reasoning over teammates' underlying goals and future behavior, with a multiagent denoising-diffusion model, that generates plans for an agent and its teammates conditioned on both the agent's goals and its teammates' characteristics, as computed via ToM. We implemented an online planning system that dynamically samples new trajectories (replans) from the diffusion model whenever it detects a divergence between a previously generated plan and the current state of the world. We conducted several experiments using ToMCAT in a simulated cooking domain. Our results highlight the importance of the dynamic replanning mechanism in reducing the usage of resources without sacrificing team performance. We also show that recent observations about the world and teammates' behavior collected by an agent over the course of an episode combined with ToM inferences are crucial to generate team-aware plans for dynamic adaptation to teammates, especially when no prior information is provided about them.
IxDRL: A Novel Explainable Deep Reinforcement Learning Toolkit based on Analyses of Interestingness
Jul 18, 2023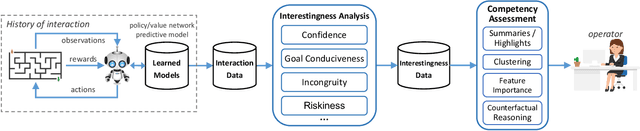
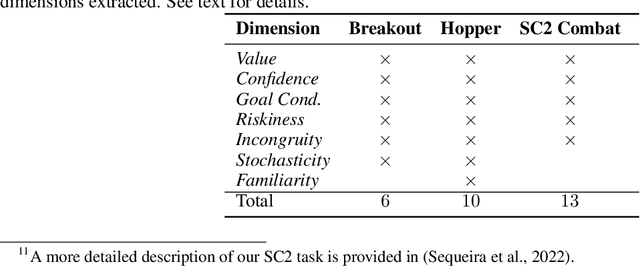
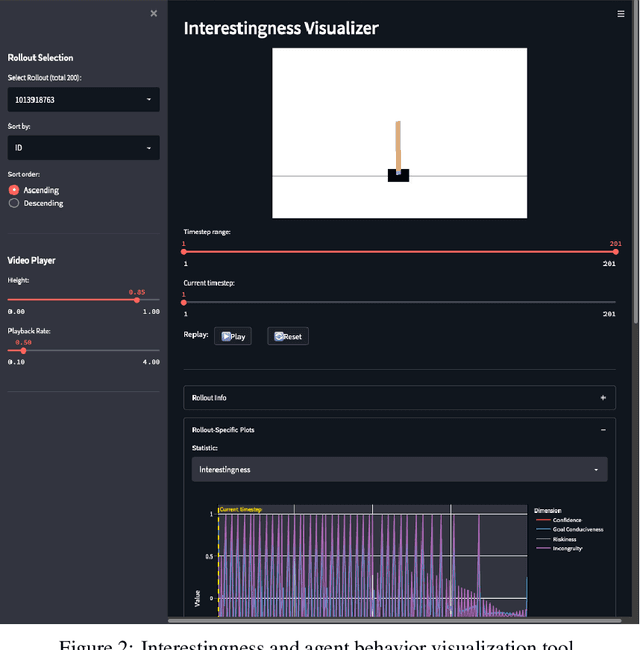
In recent years, advances in deep learning have resulted in a plethora of successes in the use of reinforcement learning (RL) to solve complex sequential decision tasks with high-dimensional inputs. However, existing systems lack the necessary mechanisms to provide humans with a holistic view of their competence, presenting an impediment to their adoption, particularly in critical applications where the decisions an agent makes can have significant consequences. Yet, existing RL-based systems are essentially competency-unaware in that they lack the necessary interpretation mechanisms to allow human operators to have an insightful, holistic view of their competency. Towards more explainable Deep RL (xDRL), we propose a new framework based on analyses of interestingness. Our tool provides various measures of RL agent competence stemming from interestingness analysis and is applicable to a wide range of RL algorithms, natively supporting the popular RLLib toolkit. We showcase the use of our framework by applying the proposed pipeline in a set of scenarios of varying complexity. We empirically assess the capability of the approach in identifying agent behavior patterns and competency-controlling conditions, and the task elements mostly responsible for an agent's competence, based on global and local analyses of interestingness. Overall, we show that our framework can provide agent designers with insights about RL agent competence, both their capabilities and limitations, enabling more informed decisions about interventions, additional training, and other interactions in collaborative human-machine settings.
Multiagent Inverse Reinforcement Learning via Theory of Mind Reasoning
Mar 01, 2023We approach the problem of understanding how people interact with each other in collaborative settings, especially when individuals know little about their teammates, via Multiagent Inverse Reinforcement Learning (MIRL), where the goal is to infer the reward functions guiding the behavior of each individual given trajectories of a team's behavior during some task. Unlike current MIRL approaches, we do not assume that team members know each other's goals a priori; rather, that they collaborate by adapting to the goals of others perceived by observing their behavior, all while jointly performing a task. To address this problem, we propose a novel approach to MIRL via Theory of Mind (MIRL-ToM). For each agent, we first use ToM reasoning to estimate a posterior distribution over baseline reward profiles given their demonstrated behavior. We then perform MIRL via decentralized equilibrium by employing single-agent Maximum Entropy IRL to infer a reward function for each agent, where we simulate the behavior of other teammates according to the time-varying distribution over profiles. We evaluate our approach in a simulated 2-player search-and-rescue operation where the goal of the agents, playing different roles, is to search for and evacuate victims in the environment. Our results show that the choice of baseline profiles is paramount to the recovery of the ground-truth rewards, and that MIRL-ToM is able to recover the rewards used by agents interacting both with known and unknown teammates.
Global and Local Analysis of Interestingness for Competency-Aware Deep Reinforcement Learning
Nov 11, 2022



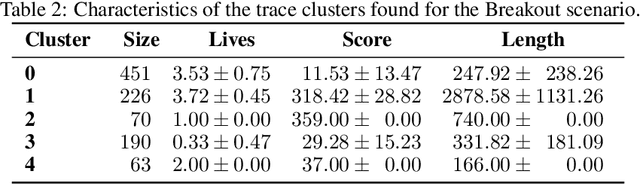
In recent years, advances in deep learning have resulted in a plethora of successes in the use of reinforcement learning (RL) to solve complex sequential decision tasks with high-dimensional inputs. However, existing systems lack the necessary mechanisms to provide humans with a holistic view of their competence, presenting an impediment to their adoption, particularly in critical applications where the decisions an agent makes can have significant consequences. Yet, existing RL-based systems are essentially competency-unaware in that they lack the necessary interpretation mechanisms to allow human operators to have an insightful, holistic view of their competency. In this paper, we extend a recently-proposed framework for explainable RL that is based on analyses of "interestingness." Our new framework provides various measures of RL agent competence stemming from interestingness analysis and is applicable to a wide range of RL algorithms. We also propose novel mechanisms for assessing RL agents' competencies that: 1) identify agent behavior patterns and competency-controlling conditions by clustering agent behavior traces solely using interestingness data; and 2) identify the task elements mostly responsible for an agent's behavior, as measured through interestingness, by performing global and local analyses using SHAP values. Overall, our tools provide insights about RL agent competence, both their capabilities and limitations, enabling users to make more informed decisions about interventions, additional training, and other interactions in collaborative human-machine settings.
Sensor Control for Information Gain in Dynamic, Sparse and Partially Observed Environments
Nov 03, 2022



We present an approach for autonomous sensor control for information gathering under partially observable, dynamic and sparsely sampled environments. We consider the problem of controlling a sensor that makes partial observations in some space of interest such that it maximizes information about entities present in that space. We describe our approach for the task of Radio-Frequency (RF) spectrum monitoring, where the goal is to search for and track unknown, dynamic signals in the environment. To this end, we develop and demonstrate enhancements of the Deep Anticipatory Network (DAN) Reinforcement Learning (RL) framework that uses prediction and information-gain rewards to learn information-maximization policies in reward-sparse environments. We also extend this problem to situations in which taking samples from the actual RF spectrum/field is limited and expensive, and propose a model-based version of the original RL algorithm that fine-tunes the controller using a model of the environment that is iteratively improved from limited samples taken from the RF field. Our approach was thoroughly validated by testing against baseline expert-designed controllers in simulated RF environments of different complexity, using different rewards schemes and evaluation metrics. The results show that our system outperforms the standard DAN architecture and is more flexible and robust than several hand-coded agents. We also show that our approach is adaptable to non-stationary environments where the agent has to learn to adapt to changes from the emitting sources.
A Framework for Understanding and Visualizing Strategies of RL Agents
Aug 17, 2022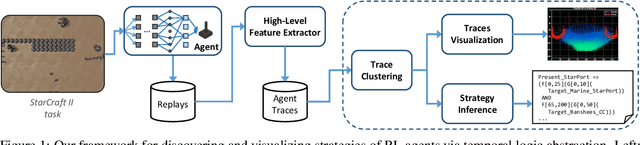
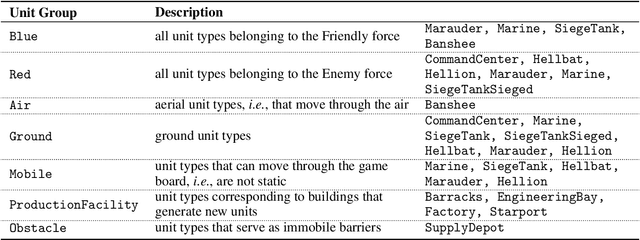
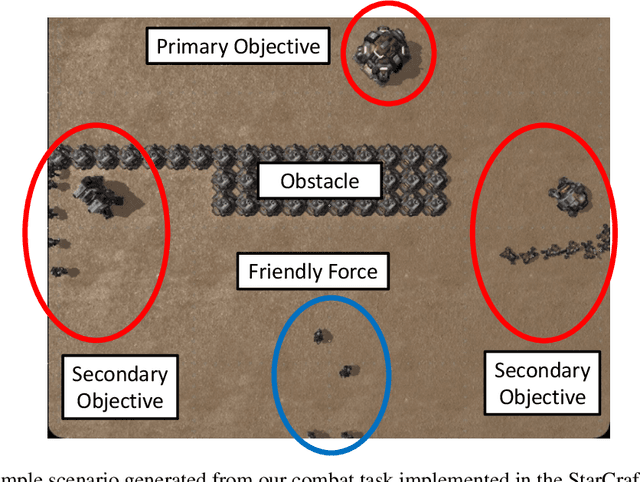
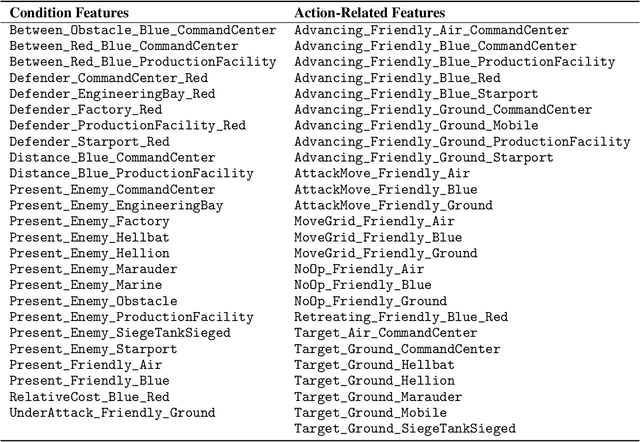
Recent years have seen significant advances in explainable AI as the need to understand deep learning models has gained importance with the increased emphasis on trust and ethics in AI. Comprehensible models for sequential decision tasks are a particular challenge as they require understanding not only individual predictions but a series of predictions that interact with environmental dynamics. We present a framework for learning comprehensible models of sequential decision tasks in which agent strategies are characterized using temporal logic formulas. Given a set of agent traces, we first cluster the traces using a novel embedding method that captures frequent action patterns. We then search for logical formulas that explain the agent strategies in the different clusters. We evaluate our framework on combat scenarios in StarCraft II (SC2), using traces from a handcrafted expert policy and a trained reinforcement learning agent. We implemented a feature extractor for SC2 environments that extracts traces as sequences of high-level features describing both the state of the environment and the agent's local behavior from agent replays. We further designed a visualization tool depicting the movement of units in the environment that helps understand how different task conditions lead to distinct agent behavior patterns in each trace cluster. Experimental results show that our framework is capable of separating agent traces into distinct groups of behaviors for which our approach to strategy inference produces consistent, meaningful, and easily understood strategy descriptions.
Outcome-Guided Counterfactuals for Reinforcement Learning Agents from a Jointly Trained Generative Latent Space
Jul 15, 2022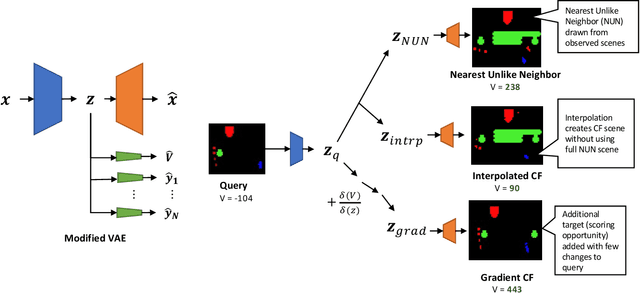
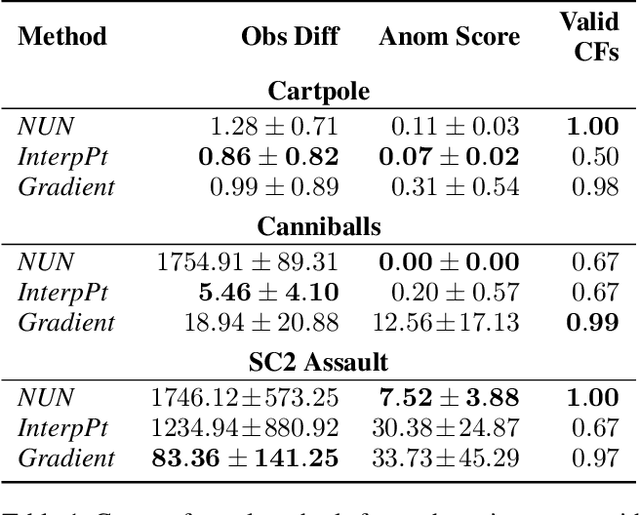
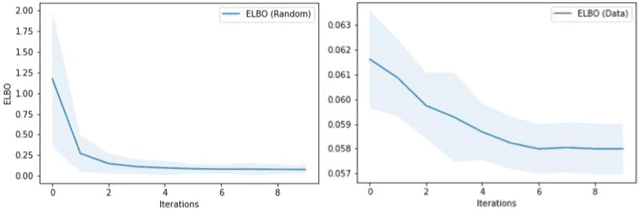
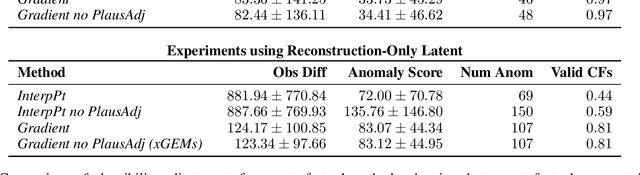
We present a novel generative method for producing unseen and plausible counterfactual examples for reinforcement learning (RL) agents based upon outcome variables that characterize agent behavior. Our approach uses a variational autoencoder to train a latent space that jointly encodes information about the observations and outcome variables pertaining to an agent's behavior. Counterfactuals are generated using traversals in this latent space, via gradient-driven updates as well as latent interpolations against cases drawn from a pool of examples. These include updates to raise the likelihood of generated examples, which improves the plausibility of generated counterfactuals. From experiments in three RL environments, we show that these methods produce counterfactuals that are more plausible and proximal to their queries compared to purely outcome-driven or case-based baselines. Finally, we show that a latent jointly trained to reconstruct both the input observations and behavioral outcome variables produces higher-quality counterfactuals over latents trained solely to reconstruct the observation inputs.
Interestingness Elements for Explainable Reinforcement Learning: Understanding Agents' Capabilities and Limitations
Dec 19, 2019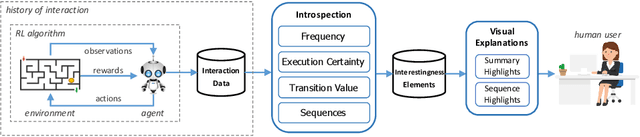

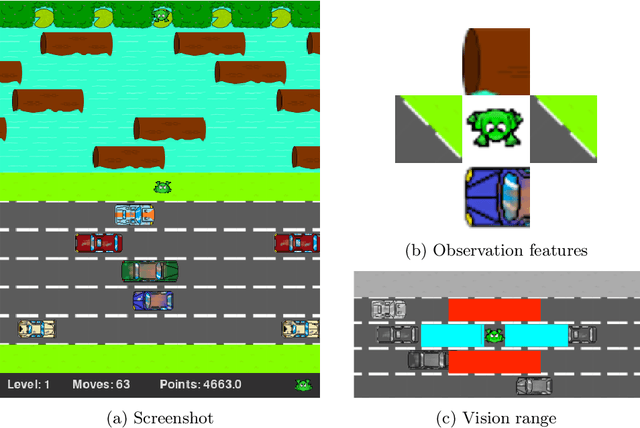

We propose an explainable reinforcement learning (XRL) framework that analyzes an agent's history of interaction with the environment to extract interestingness elements that help explain its behavior. The framework relies on data readily available from standard RL algorithms, augmented with data that can easily be collected by the agent while learning. We describe how to create visual explanations of an agent's behavior in the form of short video-clips highlighting key interaction moments, based on the proposed elements. We also report on a user study where we evaluated the ability of humans in correctly perceiving the aptitude of agents with different characteristics, including their capabilities and limitations, given explanations automatically generated by our framework. The results show that the diversity of aspects captured by the different interestingness elements is crucial to help humans correctly identify the agents' aptitude in the task, and determine when they might need adjustments to improve their performance.