 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric Governance
Feb 14, 2023



Artificial intelligence (AI) governance is the body of standards and practices used to ensure that AI systems are deployed responsibly. Current AI governance approaches consist mainly of manual review and documentation processes. While such reviews are necessary for many systems, they are not sufficient to systematically address all potential harms, as they do not operationalize governance requirements for system engineering, behavior, and outcomes in a way that facilitates rigorous and reproducible evaluation. Modern AI systems are data-centric: they act on data, produce data, and are built through data engineering. The assurance of governance requirements must also be carried out in terms of data. This work explores the systematization of governance requirements via datasets and algorithmic evaluations. When applied throughout the product lifecycle, data-centric governance decreases time to deployment, increases solution quality, decreases deployment risks, and places the system in a continuous state of assured compliance with governance requirements.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023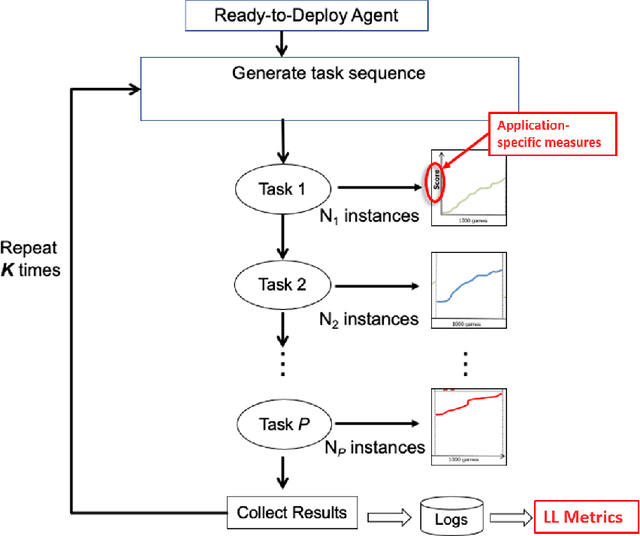


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
System Design for an Integrated Lifelong Reinforcement Learning Agent for Real-Time Strategy Games
Dec 08, 2022

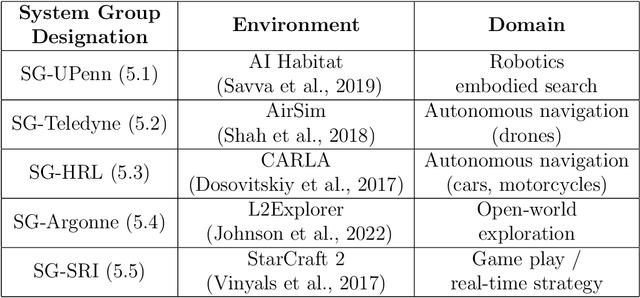
As Artificial and Robotic Systems are increasingly deployed and relied upon for real-world applications, it is important that they exhibit the ability to continually learn and adapt in dynamically-changing environments, becoming Lifelong Learning Machines. Continual/lifelong learning (LL) involves minimizing catastrophic forgetting of old tasks while maximizing a model's capability to learn new tasks. This paper addresses the challenging lifelong reinforcement learning (L2RL) setting. Pushing the state-of-the-art forward in L2RL and making L2RL useful for practical applications requires more than developing individual L2RL algorithms; it requires making progress at the systems-level, especially research into the non-trivial problem of how to integrate multiple L2RL algorithms into a common framework. In this paper, we introduce the Lifelong Reinforcement Learning Components Framework (L2RLCF), which standardizes L2RL systems and assimilates different continual learning components (each addressing different aspects of the lifelong learning problem) into a unified system. As an instantiation of L2RLCF, we develop a standard API allowing easy integration of novel lifelong learning components. We describe a case study that demonstrates how multiple independently-developed LL components can be integrated into a single realized system. We also introduce an evaluation environment in order to measure the effect of combining various system components. Our evaluation environment employs different LL scenarios (sequences of tasks) consisting of Starcraft-2 minigames and allows for the fair, comprehensive, and quantitative comparison of different combinations of components within a challenging common evaluation environment.
Global and Local Analysis of Interestingness for Competency-Aware Deep Reinforcement Learning
Nov 11, 2022



In recent years, advances in deep learning have resulted in a plethora of successes in the use of reinforcement learning (RL) to solve complex sequential decision tasks with high-dimensional inputs. However, existing systems lack the necessary mechanisms to provide humans with a holistic view of their competence, presenting an impediment to their adoption, particularly in critical applications where the decisions an agent makes can have significant consequences. Yet, existing RL-based systems are essentially competency-unaware in that they lack the necessary interpretation mechanisms to allow human operators to have an insightful, holistic view of their competency. In this paper, we extend a recently-proposed framework for explainable RL that is based on analyses of "interestingness." Our new framework provides various measures of RL agent competence stemming from interestingness analysis and is applicable to a wide range of RL algorithms. We also propose novel mechanisms for assessing RL agents' competencies that: 1) identify agent behavior patterns and competency-controlling conditions by clustering agent behavior traces solely using interestingness data; and 2) identify the task elements mostly responsible for an agent's behavior, as measured through interestingness, by performing global and local analyses using SHAP values. Overall, our tools provide insights about RL agent competence, both their capabilities and limitations, enabling users to make more informed decisions about interventions, additional training, and other interactions in collaborative human-machine settings.
A Framework for Understanding and Visualizing Strategies of RL Agents
Aug 17, 2022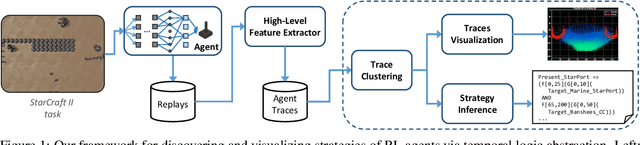
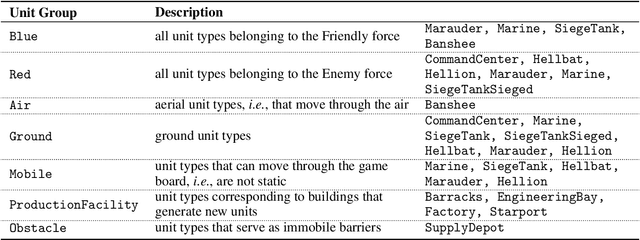
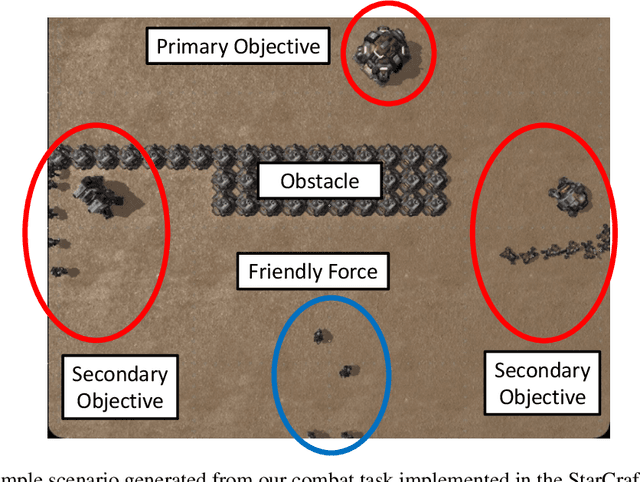
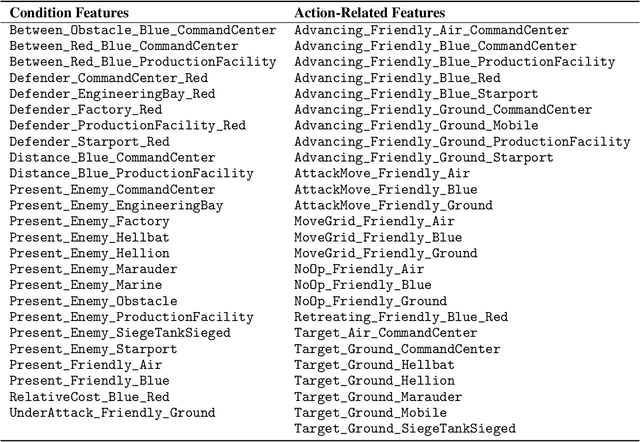
Recent years have seen significant advances in explainable AI as the need to understand deep learning models has gained importance with the increased emphasis on trust and ethics in AI. Comprehensible models for sequential decision tasks are a particular challenge as they require understanding not only individual predictions but a series of predictions that interact with environmental dynamics. We present a framework for learning comprehensible models of sequential decision tasks in which agent strategies are characterized using temporal logic formulas. Given a set of agent traces, we first cluster the traces using a novel embedding method that captures frequent action patterns. We then search for logical formulas that explain the agent strategies in the different clusters. We evaluate our framework on combat scenarios in StarCraft II (SC2), using traces from a handcrafted expert policy and a trained reinforcement learning agent. We implemented a feature extractor for SC2 environments that extracts traces as sequences of high-level features describing both the state of the environment and the agent's local behavior from agent replays. We further designed a visualization tool depicting the movement of units in the environment that helps understand how different task conditions lead to distinct agent behavior patterns in each trace cluster. Experimental results show that our framework is capable of separating agent traces into distinct groups of behaviors for which our approach to strategy inference produces consistent, meaningful, and easily understood strategy descriptions.
Model-Free Generative Replay for Lifelong Reinforcement Learning: Application to Starcraft-2
Aug 16, 2022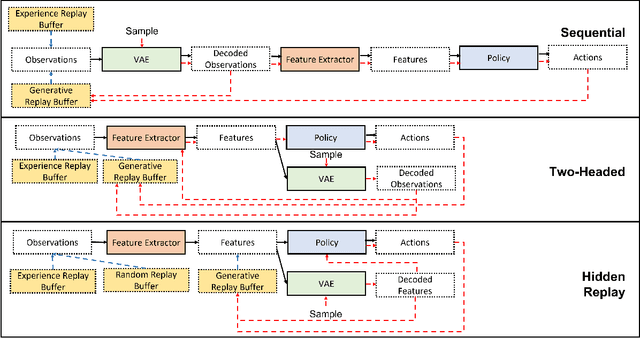

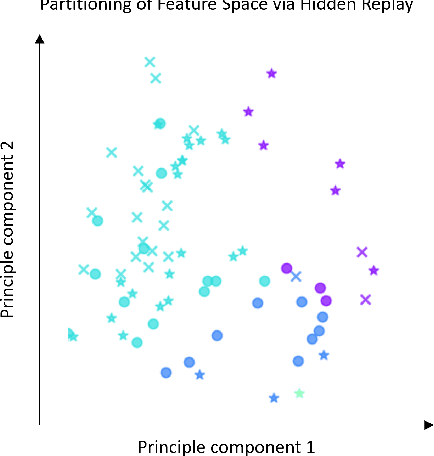

One approach to meet the challenges of deep lifelong reinforcement learning (LRL) is careful management of the agent's learning experiences, to learn (without forgetting) and build internal meta-models (of the tasks, environments, agents, and world). Generative replay (GR) is a biologically inspired replay mechanism that augments learning experiences with self-labelled examples drawn from an internal generative model that is updated over time. We present a version of GR for LRL that satisfies two desiderata: (a) Introspective density modelling of the latent representations of policies learned using deep RL, and (b) Model-free end-to-end learning. In this paper, we study three deep learning architectures for model-free GR, starting from a na\"ive GR and adding ingredients to achieve (a) and (b). We evaluate our proposed algorithms on three different scenarios comprising tasks from the Starcraft-2 and Minigrid domains. We report several key findings showing the impact of the design choices on quantitative metrics that include transfer learning, generalization to unseen tasks, fast adaptation after task change, performance wrt task expert, and catastrophic forgetting. We observe that our GR prevents drift in the features-to-action mapping from the latent vector space of a deep RL agent. We also show improvements in established lifelong learning metrics. We find that a small random replay buffer significantly increases the stability of training. Overall, we find that "hidden replay" (a well-known architecture for class-incremental classification) is the most promising approach that pushes the state-of-the-art in GR for LRL and observe that the architecture of the sleep model might be more important for improving performance than the types of replay used. Our experiments required only 6% of training samples to achieve 80-90% of expert performance in most Starcraft-2 scenarios.
Outcome-Guided Counterfactuals for Reinforcement Learning Agents from a Jointly Trained Generative Latent Space
Jul 15, 2022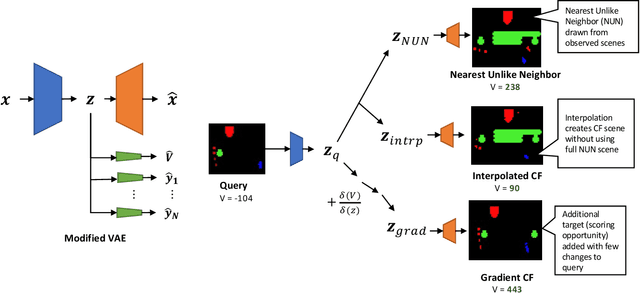
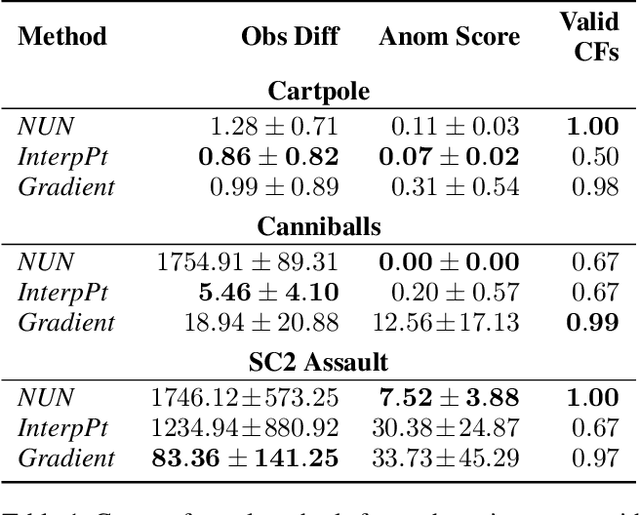
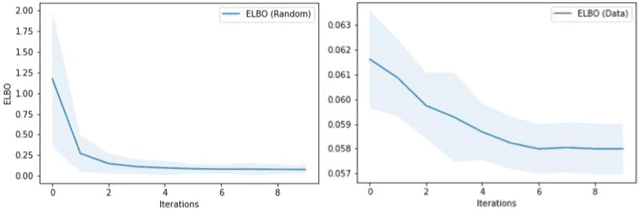
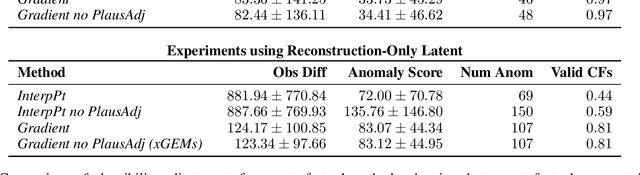
We present a novel generative method for producing unseen and plausible counterfactual examples for reinforcement learning (RL) agents based upon outcome variables that characterize agent behavior. Our approach uses a variational autoencoder to train a latent space that jointly encodes information about the observations and outcome variables pertaining to an agent's behavior. Counterfactuals are generated using traversals in this latent space, via gradient-driven updates as well as latent interpolations against cases drawn from a pool of examples. These include updates to raise the likelihood of generated examples, which improves the plausibility of generated counterfactuals. From experiments in three RL environments, we show that these methods produce counterfactuals that are more plausible and proximal to their queries compared to purely outcome-driven or case-based baselines. Finally, we show that a latent jointly trained to reconstruct both the input observations and behavioral outcome variables produces higher-quality counterfactuals over latents trained solely to reconstruct the observation inputs.
Conformal Prediction Intervals for Markov Decision Process Trajectories
Jun 21, 2022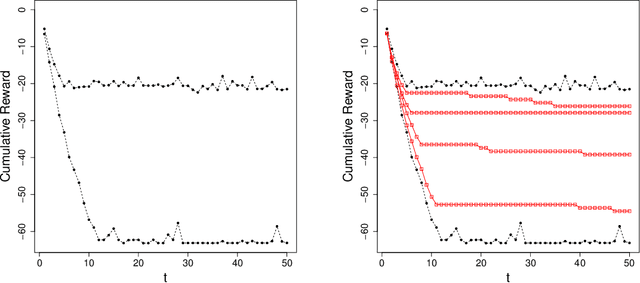
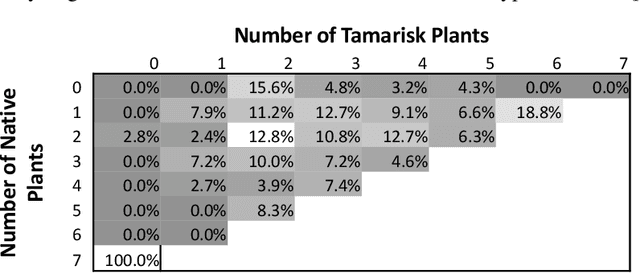
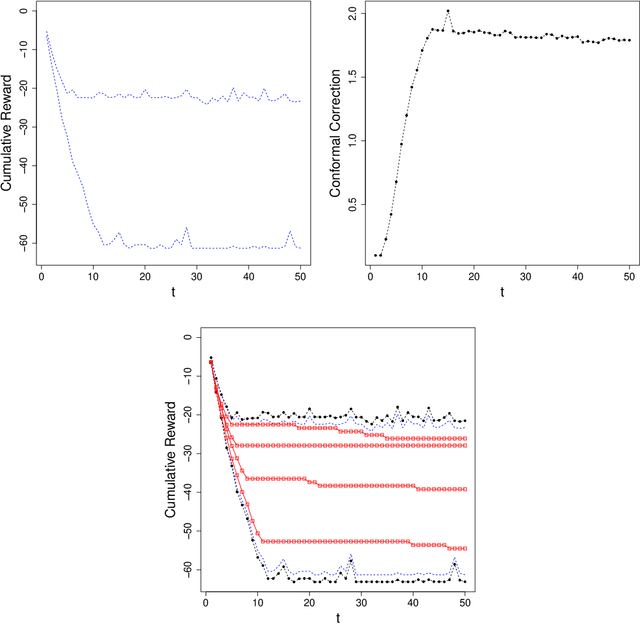
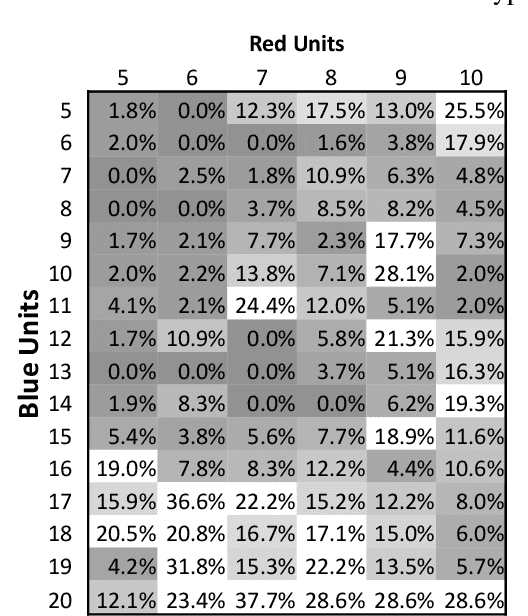
Before delegating a task to an autonomous system, a human operator may want a guarantee about the behavior of the system. This paper extends previous work on conformal prediction for functional data and conformalized quantile regression to provide conformal prediction intervals over the future behavior of an autonomous system executing a fixed control policy on a Markov Decision Process (MDP). The prediction intervals are constructed by applying conformal corrections to prediction intervals computed by quantile regression. The resulting intervals guarantee that with probability $1-\delta$ the observed trajectory will lie inside the prediction interval, where the probability is computed with respect to the starting state distribution and the stochasticity of the MDP. The method is illustrated on MDPs for invasive species management and StarCraft2 battles.
Dynamically Throttleable Neural Networks (TNN)
Nov 01, 2020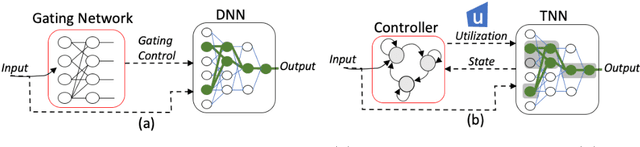


Conditional computation for Deep Neural Networks (DNNs) reduce overall computational load and improve model accuracy by running a subset of the network. In this work, we present a runtime throttleable neural network (TNN) that can adaptively self-regulate its own performance target and computing resources. We designed TNN with several properties that enable more flexibility for dynamic execution based on runtime context. TNNs are defined as throttleable modules gated with a separately trained controller that generates a single utilization control parameter. We validate our proposal on a number of experiments, including Convolution Neural Networks (CNNs such as VGG, ResNet, ResNeXt, DenseNet) using CiFAR-10 and ImageNet dataset, for object classification and recognition tasks. We also demonstrate the effectiveness of dynamic TNN execution on a 3D Convolustion Network (C3D) for a hand gesture task. Results show that TNN can maintain peak accuracy performance compared to vanilla solutions, while providing a graceful reduction in computational requirement, down to 74% reduction in latency and 52% energy savings.
Lifelong Learning using Eigentasks: Task Separation, Skill Acquisition, and Selective Transfer
Jul 14, 2020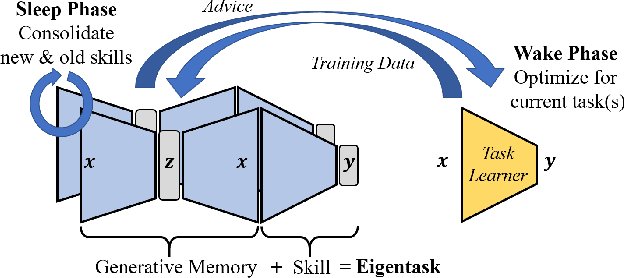
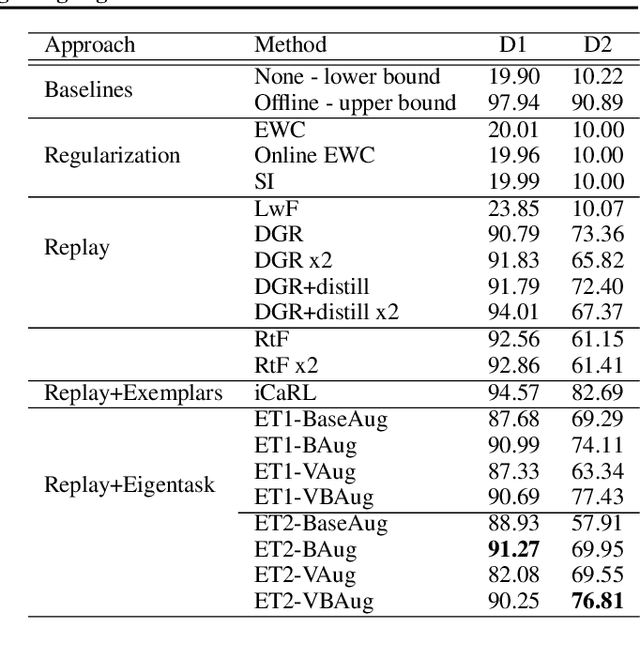
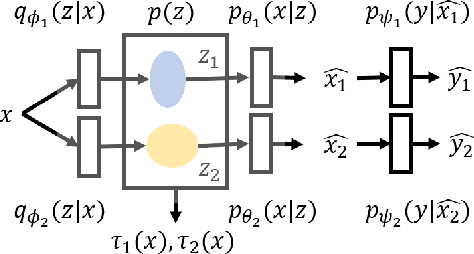

We introduce the eigentask framework for lifelong learning. An eigentask is a pairing of a skill that solves a set of related tasks, paired with a generative model that can sample from the skill's input space. The framework extends generative replay approaches, which have mainly been used to avoid catastrophic forgetting, to also address other lifelong learning goals such as forward knowledge transfer. We propose a wake-sleep cycle of alternating task learning and knowledge consolidation for learning in our framework, and instantiate it for lifelong supervised learning and lifelong RL. We achieve improved performance over the state-of-the-art in supervised continual learning, and show evidence of forward knowledge transfer in a lifelong RL application in the game Starcraft2.