 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization-Guided Training for Compact TinyML Models
Mar 10, 2021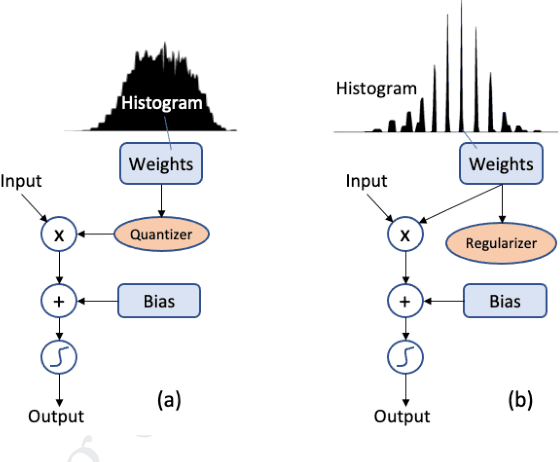
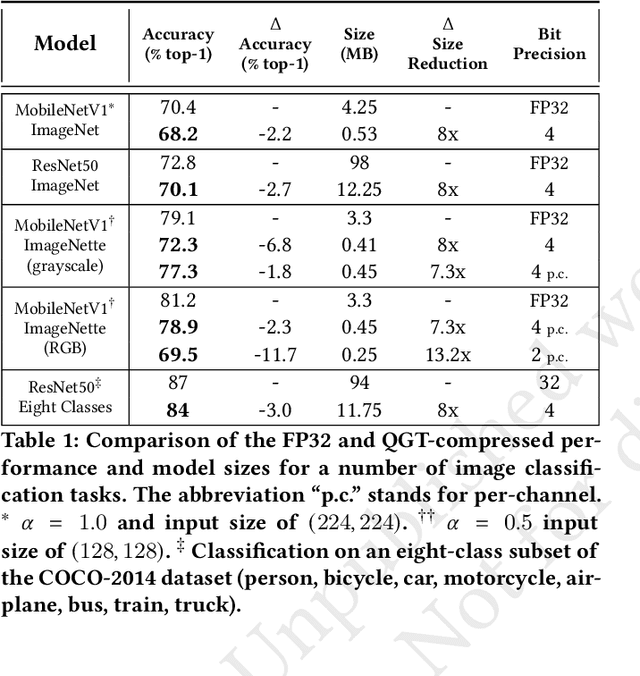
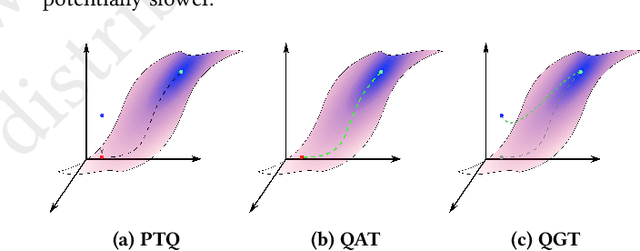
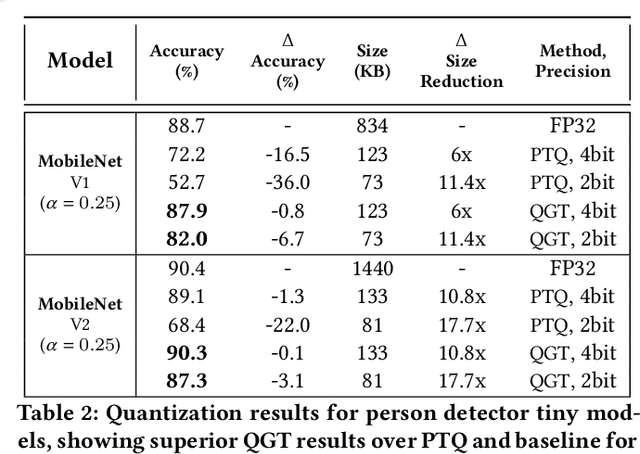
We propose a Quantization Guided Training (QGT) method to guide DNN training towards optimized low-bit-precision targets and reach extreme compression levels below 8-bit precision. Unlike standard quantization-aware training (QAT) approaches, QGT uses customized regularization to encourage weight values towards a distribution that maximizes accuracy while reducing quantization errors. One of the main benefits of this approach is the ability to identify compression bottlenecks. We validate QGT using state-of-the-art model architectures on vision datasets. We also demonstrate the effectiveness of QGT with an 81KB tiny model for person detection down to 2-bit precision (representing 17.7x size reduction), while maintaining an accuracy drop of only 3% compared to a floating-point baseline.
Subtensor Quantization for Mobilenets
Nov 04, 2020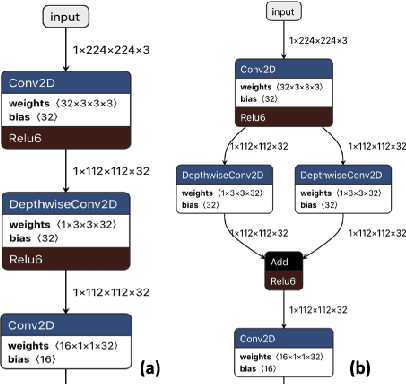
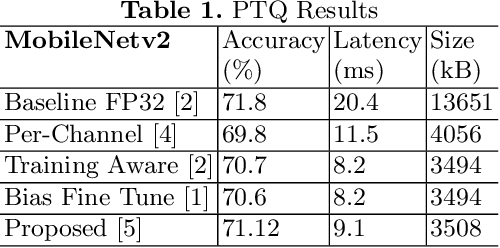
Quantization for deep neural networks (DNN) have enabled developers to deploy models with less memory and more efficient low-power inference. However, not all DNN designs are friendly to quantization. For example, the popular Mobilenet architecture has been tuned to reduce parameter size and computational latency with separable depth-wise convolutions, but not all quantization algorithms work well and the accuracy can suffer against its float point versions. In this paper, we analyzed several root causes of quantization loss and proposed alternatives that do not rely on per-channel or training-aware approaches. We evaluate the image classification task on ImageNet dataset, and our post-training quantized 8-bit inference top-1 accuracy in within 0.7% of the floating point version.
Dynamically Throttleable Neural Networks (TNN)
Nov 01, 2020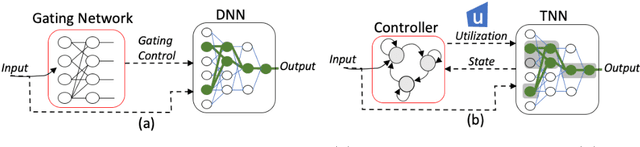

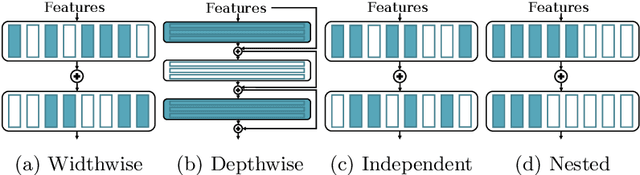

Conditional computation for Deep Neural Networks (DNNs) reduce overall computational load and improve model accuracy by running a subset of the network. In this work, we present a runtime throttleable neural network (TNN) that can adaptively self-regulate its own performance target and computing resources. We designed TNN with several properties that enable more flexibility for dynamic execution based on runtime context. TNNs are defined as throttleable modules gated with a separately trained controller that generates a single utilization control parameter. We validate our proposal on a number of experiments, including Convolution Neural Networks (CNNs such as VGG, ResNet, ResNeXt, DenseNet) using CiFAR-10 and ImageNet dataset, for object classification and recognition tasks. We also demonstrate the effectiveness of dynamic TNN execution on a 3D Convolustion Network (C3D) for a hand gesture task. Results show that TNN can maintain peak accuracy performance compared to vanilla solutions, while providing a graceful reduction in computational requirement, down to 74% reduction in latency and 52% energy savings.
Bit Efficient Quantization for Deep Neural Networks
Oct 07, 2019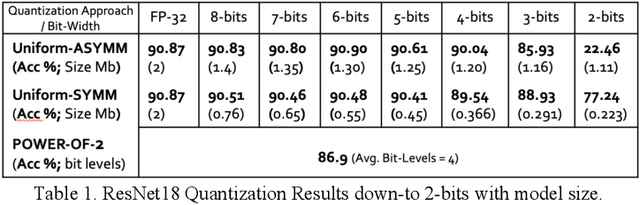
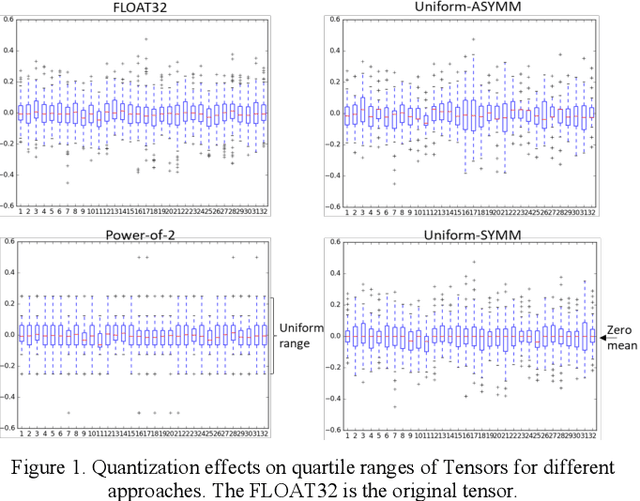
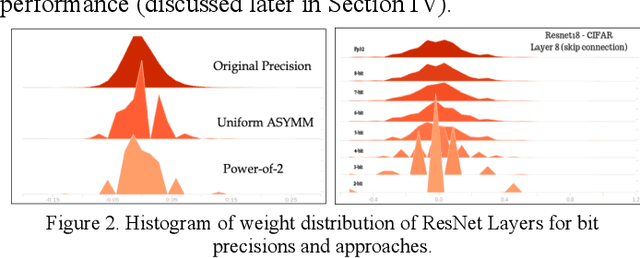

Quantization for deep neural networks have afforded models for edge devices that use less on-board memory and enable efficient low-power inference. In this paper, we present a comparison of model-parameter driven quantization approaches that can achieve as low as 3-bit precision without affecting accuracy. The post-training quantization approaches are data-free, and the resulting weight values are closely tied to the dataset distribution on which the model has converged to optimality. We show quantization results for a number of state-of-art deep neural networks (DNN) using large dataset like ImageNet. To better analyze quantization results, we describe the overall range and local sparsity of values afforded through various quantization schemes. We show the methods to lower bit-precision beyond quantization limits with object class clustering.
Generative Memory for Lifelong Reinforcement Learning
Feb 22, 2019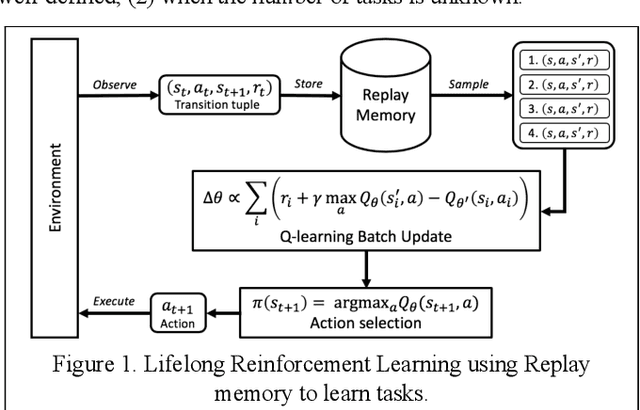
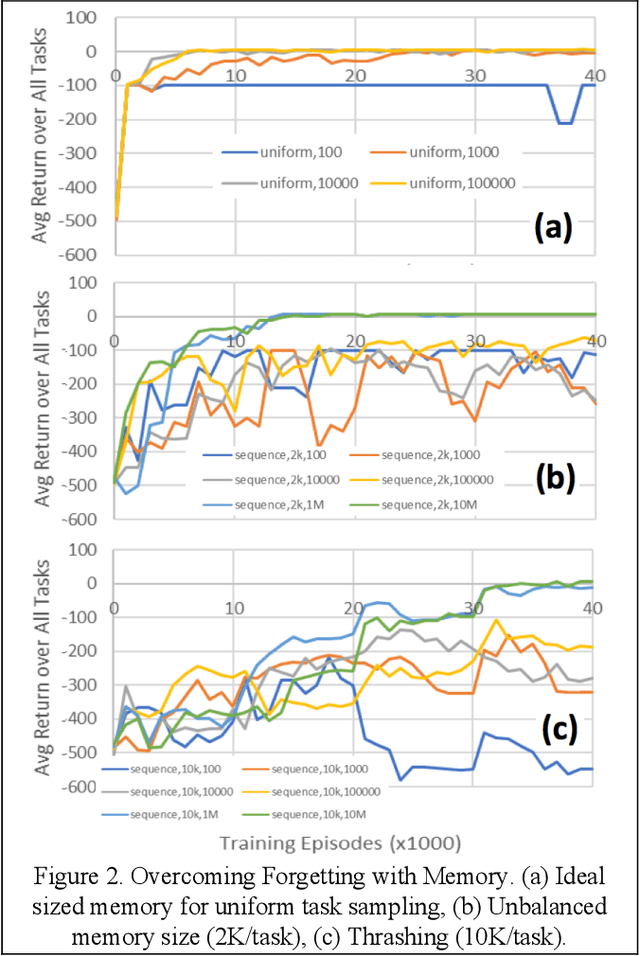
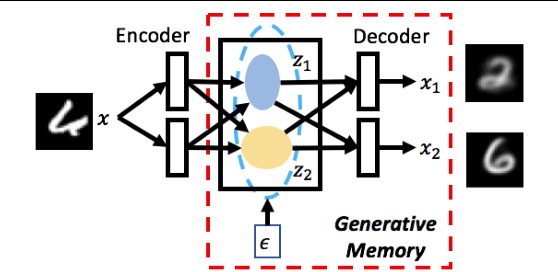
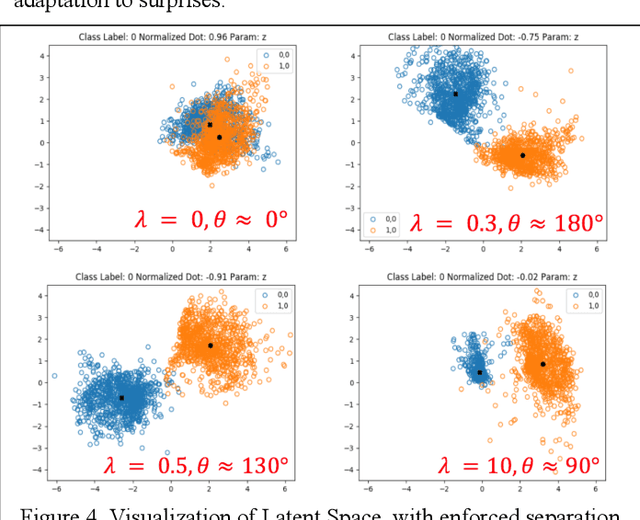
Our research is focused on understanding and applying biological memory transfers to new AI systems that can fundamentally improve their performance, throughout their fielded lifetime experience. We leverage current understanding of biological memory transfer to arrive at AI algorithms for memory consolidation and replay. In this paper, we propose the use of generative memory that can be recalled in batch samples to train a multi-task agent in a pseudo-rehearsal manner. We show results motivating the need for task-agnostic separation of latent space for the generative memory to address issues of catastrophic forgetting in lifelong learning.
Bootstrapping Deep Neural Networks from Image Processing and Computer Vision Pipelines
Nov 29, 2018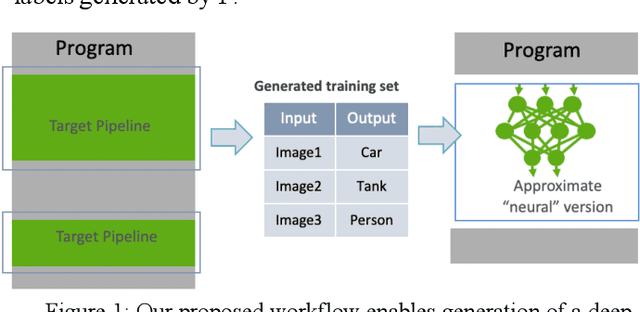
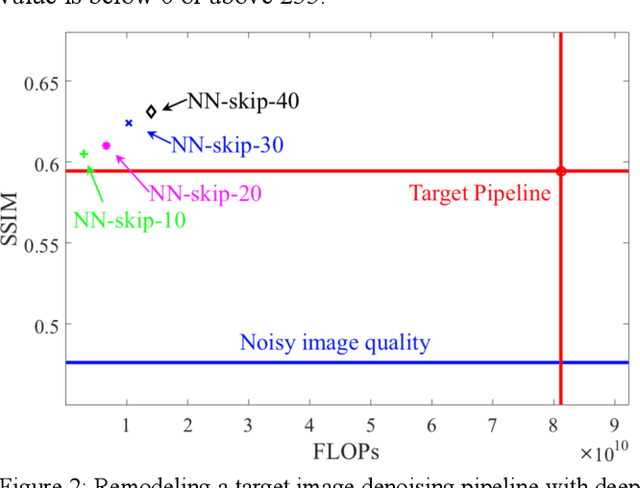
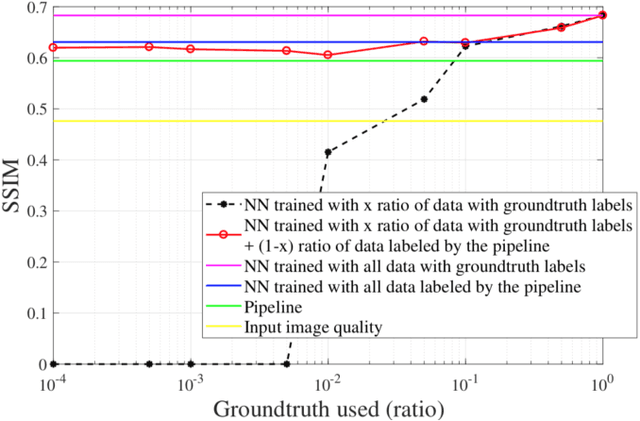
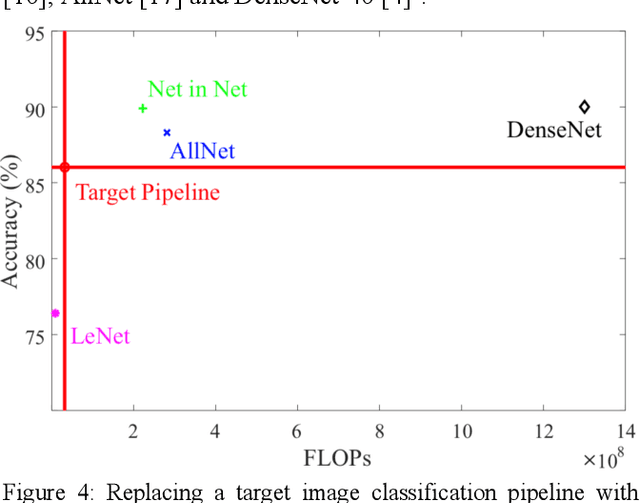
Complex image processing and computer vision systems often consist of a "pipeline" of "black boxes" that each solve part of the problem. We intend to replace parts or all of a target pipeline with deep neural networks to achieve benefits such as increased accuracy or reduced computational requirement. To acquire a large amounts of labeled data necessary to train the deep neural network, we propose a workflow that leverages the target pipeline to create a significantly larger labeled training set automatically, without prior domain knowledge of the target pipeline. We show experimentally that despite the noise introduced by automated labeling and only using a very small initially labeled data set, the trained deep neural networks can achieve similar or even better performance than the components they replace, while in some cases also reducing computational requirements.
Generalized Ternary Connect: End-to-End Learning and Compression of Multiplication-Free Deep Neural Networks
Nov 12, 2018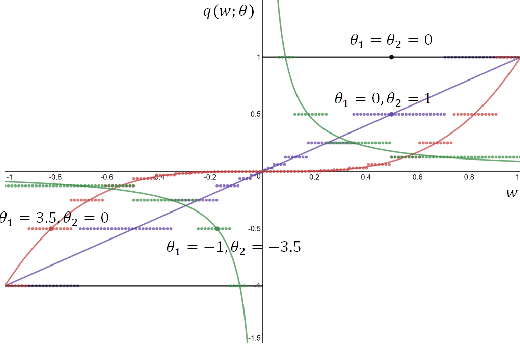
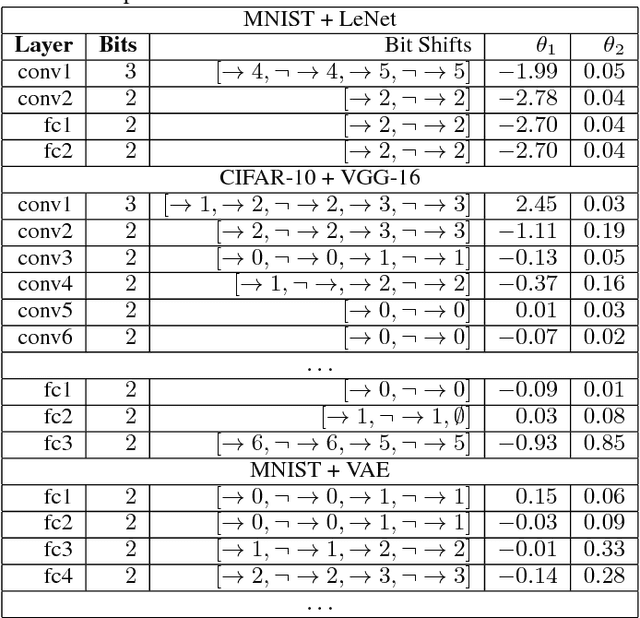
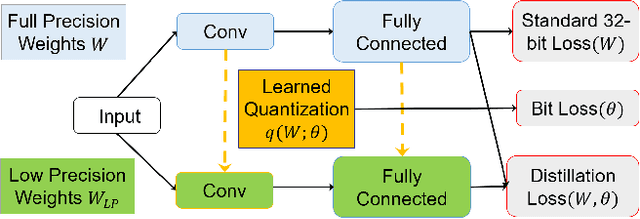
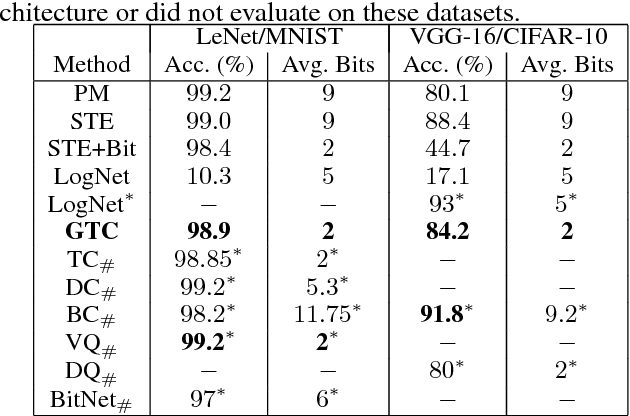
The use of deep neural networks in edge computing devices hinges on the balance between accuracy and complexity of computations. Ternary Connect (TC) \cite{lin2015neural} addresses this issue by restricting the parameters to three levels $-1, 0$, and $+1$, thus eliminating multiplications in the forward pass of the network during prediction. We propose Generalized Ternary Connect (GTC), which allows an arbitrary number of levels while at the same time eliminating multiplications by restricting the parameters to integer powers of two. The primary contribution is that GTC learns the number of levels and their values for each layer, jointly with the weights of the network in an end-to-end fashion. Experiments on MNIST and CIFAR-10 show that GTC naturally converges to an `almost binary' network for deep classification networks (e.g. VGG-16) and deep variational auto-encoders, with negligible loss of classification accuracy and comparable visual quality of generated samples respectively. We demonstrate superior compression and similar accuracy of GTC in comparison to several state-of-the-art methods for neural network compression. We conclude with simulations showing the potential benefits of GTC in hardware.
Detecting Zero-day Controller Hijacking Attacks on the Power-Grid with Enhanced Deep Learning
Sep 21, 2018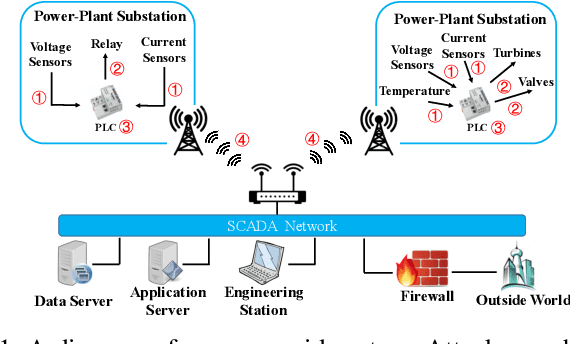
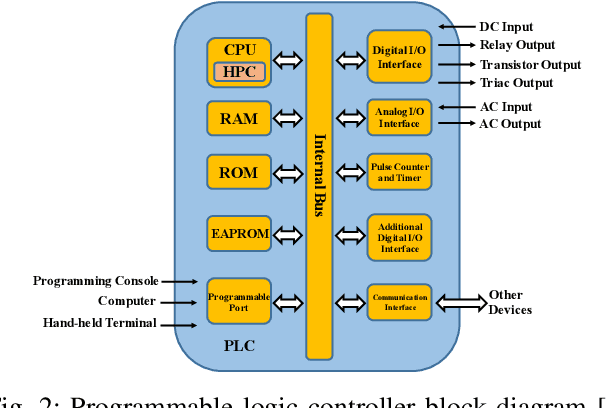
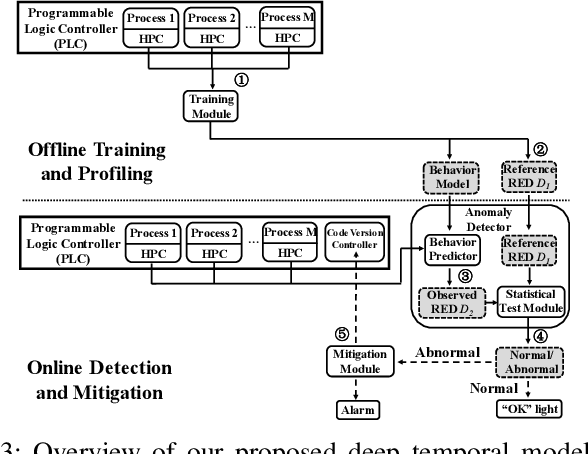
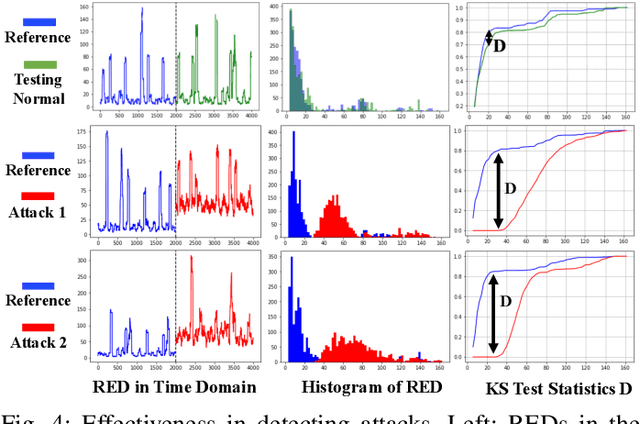
Attacks against the control processor of a power-grid system, especially zero-day attacks, can be catastrophic. Earlier detection of the attacks can prevent further damage. However, detecting zero-day attacks can be challenging because they have no known code and have unknown behavior. In order to address the zero-day attack problem, we propose a data-driven defense by training a temporal deep learning model, using only normal data from legitimate processes that run daily in these power-grid systems, to model the normal behavior of the power-grid controller. Then, we can quickly find malicious codes running on the processor, by estimating deviations from the normal behavior with a statistical test. Experimental results on a real power-grid controller show that we can detect anomalous behavior with over 99.9% accuracy and nearly zero false positives.
BitNet: Bit-Regularized Deep Neural Networks
Jun 26, 2018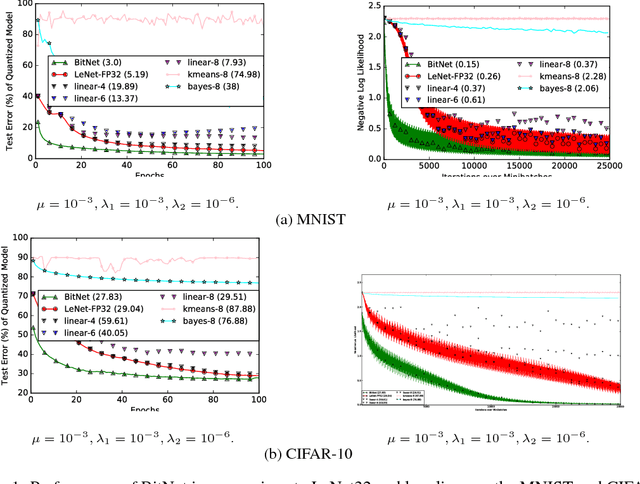
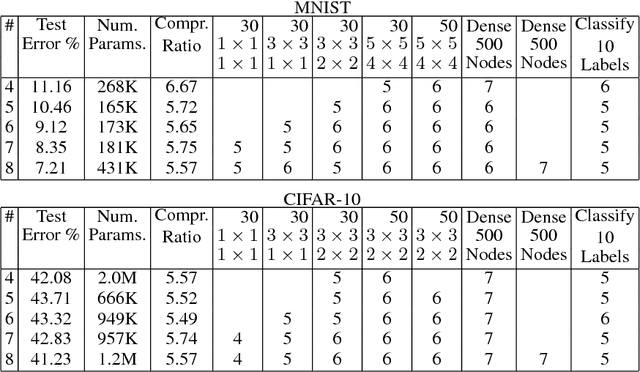
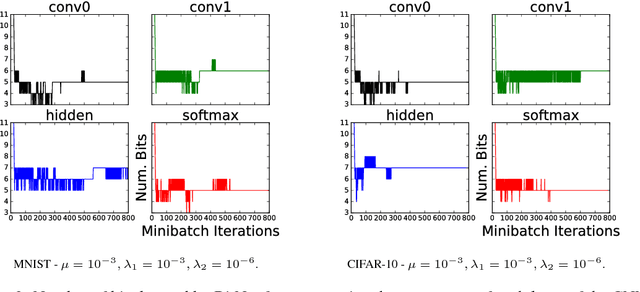
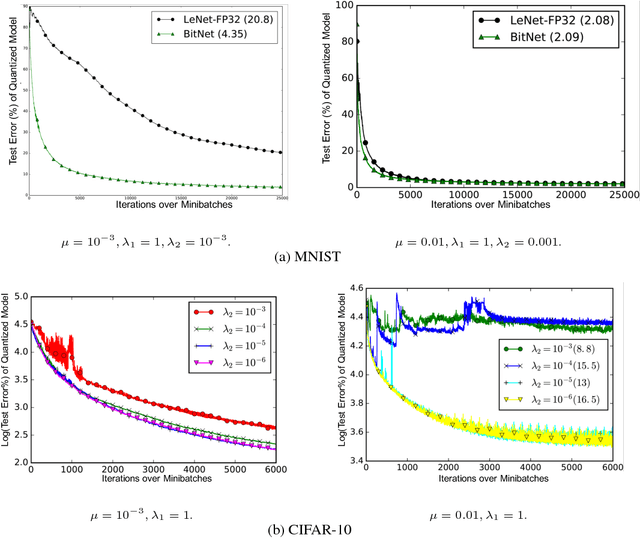
We present a novel optimization strategy for training neural networks which we call "BitNet". The parameters of neural networks are usually unconstrained and have a dynamic range dispersed over all real values. Our key idea is to limit the expressive power of the network by dynamically controlling the range and set of values that the parameters can take. We formulate this idea using a novel end-to-end approach that circumvents the discrete parameter space by optimizing a relaxed continuous and differentiable upper bound of the typical classification loss function. The approach can be interpreted as a regularization inspired by the Minimum Description Length (MDL) principle. For each layer of the network, our approach optimizes real-valued translation and scaling factors and arbitrary precision integer-valued parameters (weights). We empirically compare BitNet to an equivalent unregularized model on the MNIST and CIFAR-10 datasets. We show that BitNet converges faster to a superior quality solution. Additionally, the resulting model has significant savings in memory due to the use of integer-valued parameters.
GPU Activity Prediction using Representation Learning
Mar 27, 2017
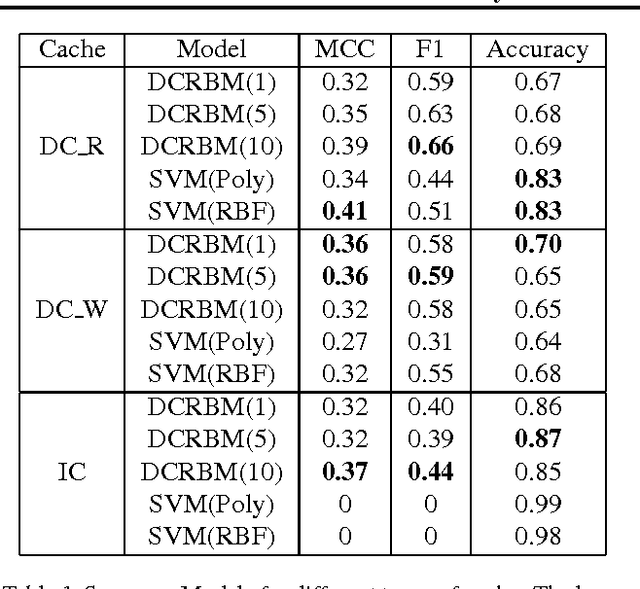

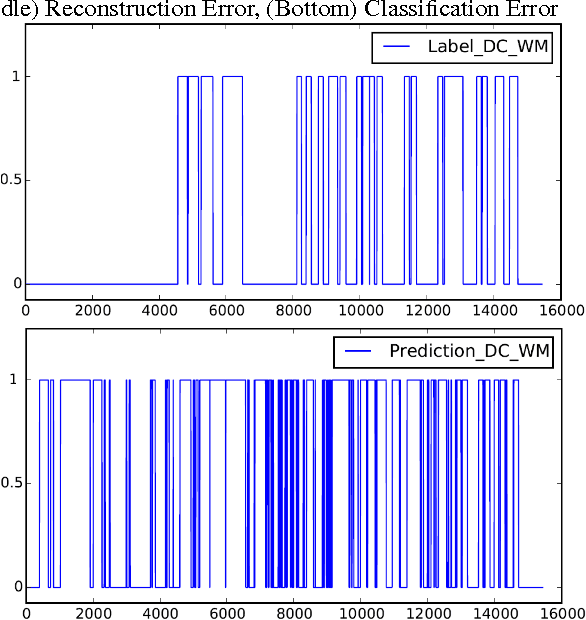
GPU activity prediction is an important and complex problem. This is due to the high level of contention among thousands of parallel threads. This problem was mostly addressed using heuristics. We propose a representation learning approach to address this problem. We model any performance metric as a temporal function of the executed instructions with the intuition that the flow of instructions can be identified as distinct activities of the code. Our experiments show high accuracy and non-trivial predictive power of representation learning on a benchmark.