 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization-Guided Training for Compact TinyML Models
Mar 10, 2021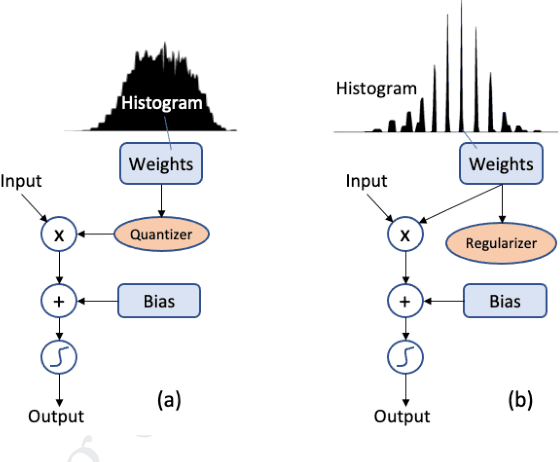
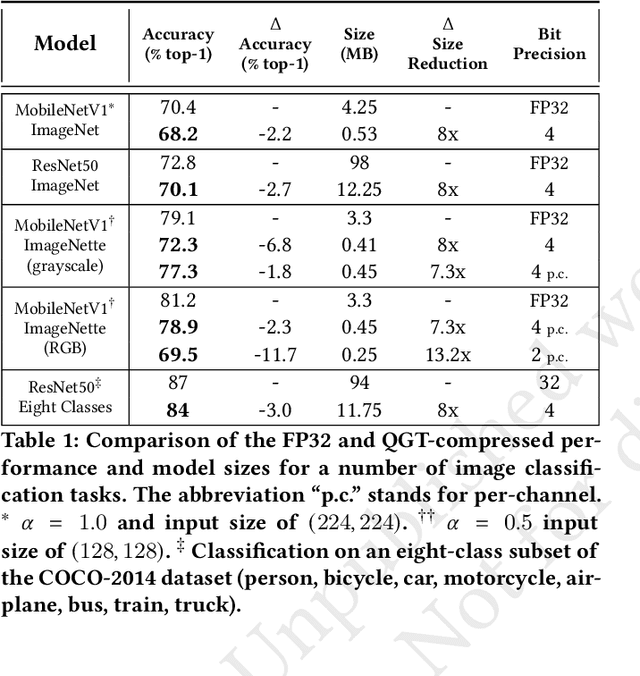
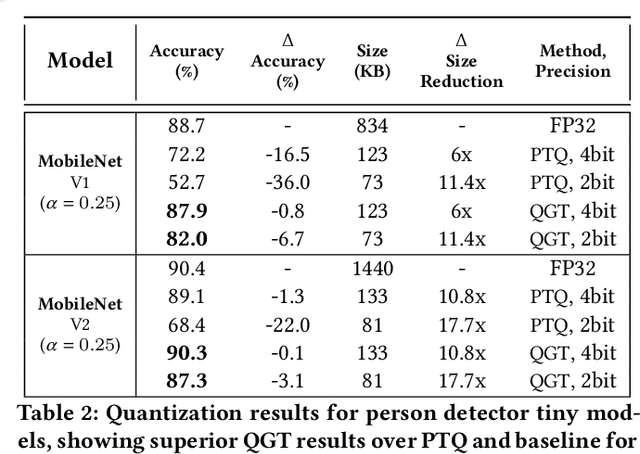
We propose a Quantization Guided Training (QGT) method to guide DNN training towards optimized low-bit-precision targets and reach extreme compression levels below 8-bit precision. Unlike standard quantization-aware training (QAT) approaches, QGT uses customized regularization to encourage weight values towards a distribution that maximizes accuracy while reducing quantization errors. One of the main benefits of this approach is the ability to identify compression bottlenecks. We validate QGT using state-of-the-art model architectures on vision datasets. We also demonstrate the effectiveness of QGT with an 81KB tiny model for person detection down to 2-bit precision (representing 17.7x size reduction), while maintaining an accuracy drop of only 3% compared to a floating-point baseline.
Subtensor Quantization for Mobilenets
Nov 04, 2020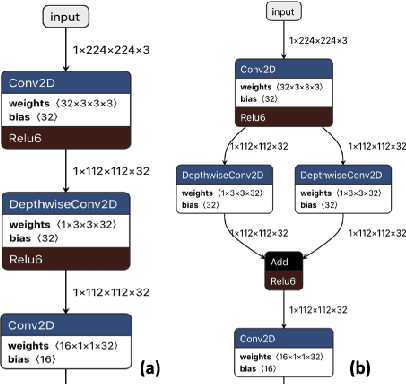
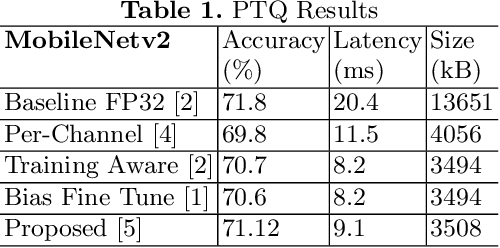
Quantization for deep neural networks (DNN) have enabled developers to deploy models with less memory and more efficient low-power inference. However, not all DNN designs are friendly to quantization. For example, the popular Mobilenet architecture has been tuned to reduce parameter size and computational latency with separable depth-wise convolutions, but not all quantization algorithms work well and the accuracy can suffer against its float point versions. In this paper, we analyzed several root causes of quantization loss and proposed alternatives that do not rely on per-channel or training-aware approaches. We evaluate the image classification task on ImageNet dataset, and our post-training quantized 8-bit inference top-1 accuracy in within 0.7% of the floating point version.