 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization-Guided Training for Compact TinyML Models
Mar 10, 2021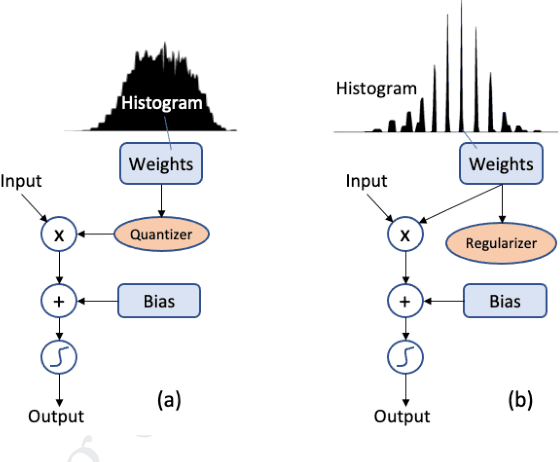
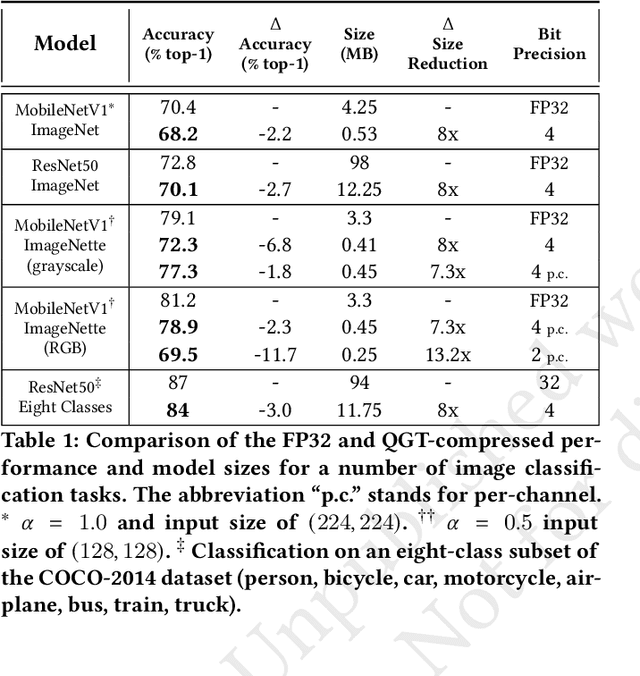
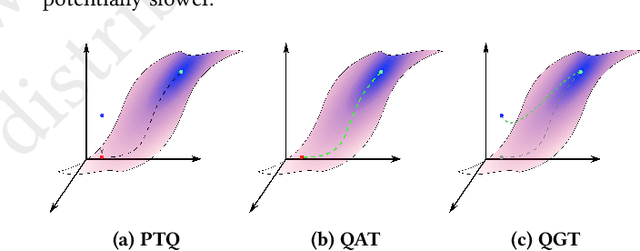
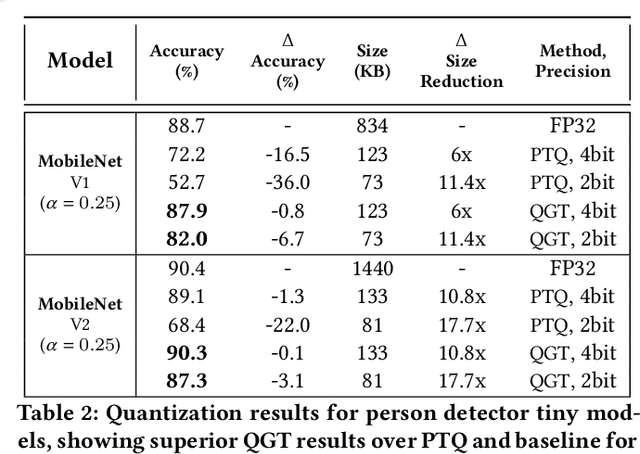
We propose a Quantization Guided Training (QGT) method to guide DNN training towards optimized low-bit-precision targets and reach extreme compression levels below 8-bit precision. Unlike standard quantization-aware training (QAT) approaches, QGT uses customized regularization to encourage weight values towards a distribution that maximizes accuracy while reducing quantization errors. One of the main benefits of this approach is the ability to identify compression bottlenecks. We validate QGT using state-of-the-art model architectures on vision datasets. We also demonstrate the effectiveness of QGT with an 81KB tiny model for person detection down to 2-bit precision (representing 17.7x size reduction), while maintaining an accuracy drop of only 3% compared to a floating-point baseline.
Counterfactual Visual Explanations
Apr 16, 2019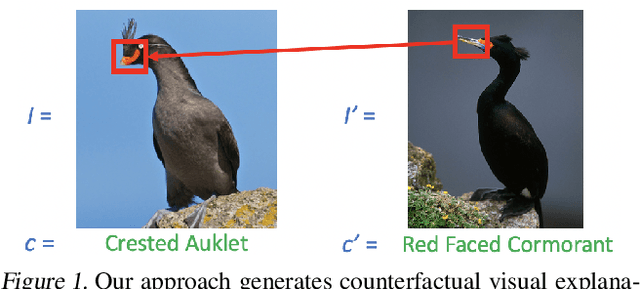
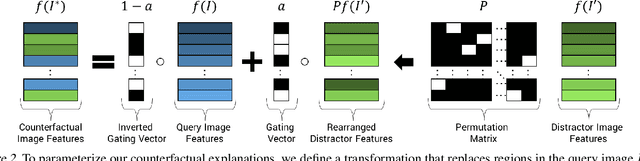
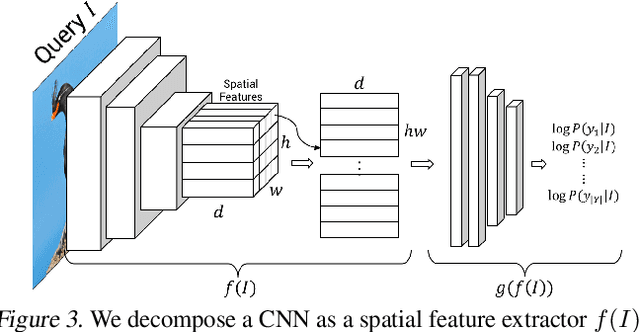
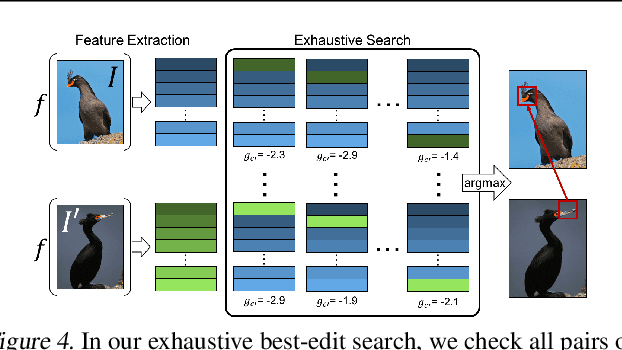
A counterfactual query is typically of the form 'For situation X, why was the outcome Y and not Z?'. A counterfactual explanation (or response to such a query) is of the form "If X was X*, then the outcome would have been Z rather than Y." In this work, we develop a technique to produce counterfactual visual explanations. Given a 'query' image $I$ for which a vision system predicts class $c$, a counterfactual visual explanation identifies how $I$ could change such that the system would output a different specified class $c'$. To do this, we select a 'distractor' image $I'$ that the system predicts as class $c'$ and identify spatial regions in $I$ and $I'$ such that replacing the identified region in $I$ with the identified region in $I'$ would push the system towards classifying $I$ as $c'$. We apply our approach to multiple image classification datasets generating qualitative results showcasing the interpretability and discriminativeness of our counterfactual explanations. To explore the effectiveness of our explanations in teaching humans, we present machine teaching experiments for the task of fine-grained bird classification. We find that users trained to distinguish bird species fare better when given access to counterfactual explanations in addition to training examples.
Incremental Scene Synthesis
Dec 11, 2018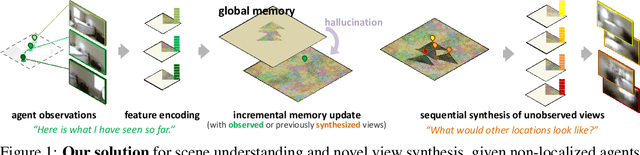
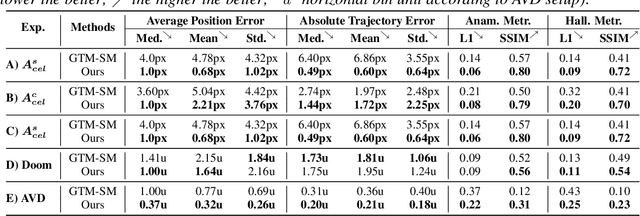
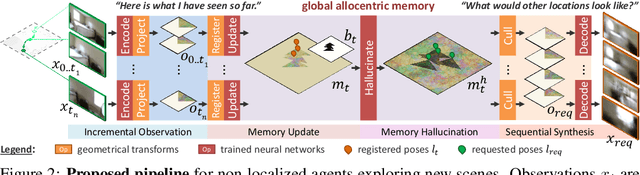
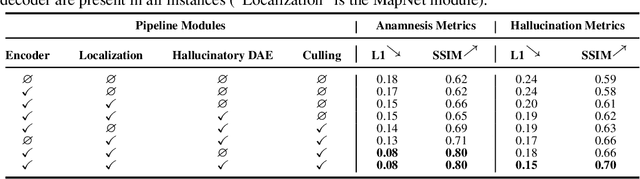
We present a method to incrementally generate complete 2D or 3D scenes with the following properties: (a) it is globally consistent at each step according to a learned scene prior, (b) real observations of an actual scene can be incorporated while observing global consistency, (c) unobserved parts of the scene can be hallucinated locally in consistence with previous observations, hallucinations and global priors, and (d) the hallucinations are statistical in nature, i.e., different consistent scenes can be generated from the same observations. To achieve this, we model the motion of an active agent through a virtual scene, where the agent at each step can either perceive a true (i.e. observed) part of the scene or generate a local hallucination. The latter can be interpreted as the expectation of the agent at this step through the scene and can already be useful, e.g., in autonomous navigation. In the limit of observing real data at each point, our method converges to solving the SLAM problem. In the limit of never observing real data, it samples entirely imagined scenes from the prior distribution. Besides autonomous agents, applications include problems where large data is required for training and testing robust real-world applications, but few data is available, necessitating data generation. We demonstrate efficacy on various 2D as well as preliminary 3D data.
Zero-Shot Deep Domain Adaptation
Jul 24, 2018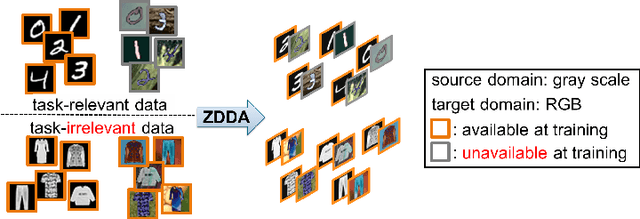


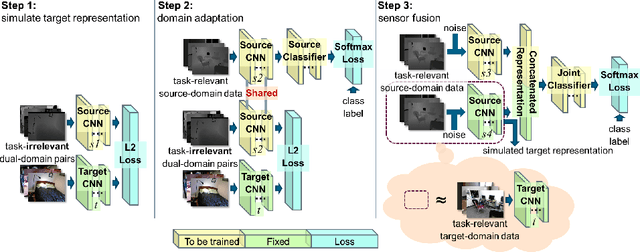
Domain adaptation is an important tool to transfer knowledge about a task (e.g. classification) learned in a source domain to a second, or target domain. Current approaches assume that task-relevant target-domain data is available during training. We demonstrate how to perform domain adaptation when no such task-relevant target-domain data is available. To tackle this issue, we propose zero-shot deep domain adaptation (ZDDA), which uses privileged information from task-irrelevant dual-domain pairs. ZDDA learns a source-domain representation which is not only tailored for the task of interest but also close to the target-domain representation. Therefore, the source-domain task of interest solution (e.g. a classifier for classification tasks) which is jointly trained with the source-domain representation can be applicable to both the source and target representations. Using the MNIST, Fashion-MNIST, NIST, EMNIST, and SUN RGB-D datasets, we show that ZDDA can perform domain adaptation in classification tasks without access to task-relevant target-domain training data. We also extend ZDDA to perform sensor fusion in the SUN RGB-D scene classification task by simulating task-relevant target-domain representations with task-relevant source-domain data. To the best of our knowledge, ZDDA is the first domain adaptation and sensor fusion method which requires no task-relevant target-domain data. The underlying principle is not particular to computer vision data, but should be extensible to other domains.
End-to-end learning of keypoint detector and descriptor for pose invariant 3D matching
May 09, 2018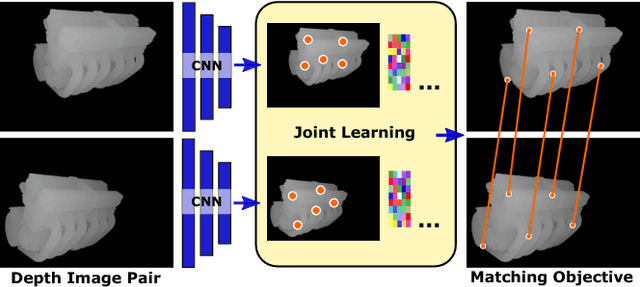
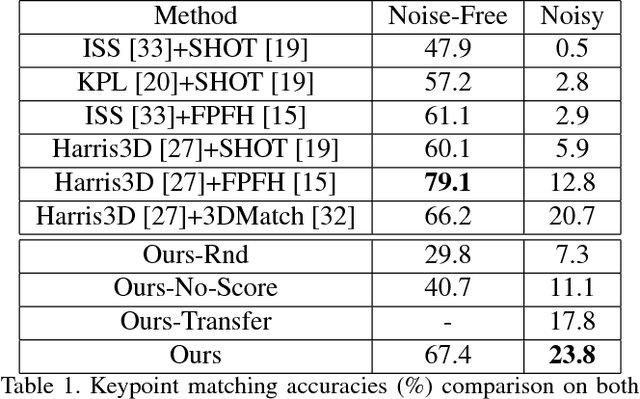
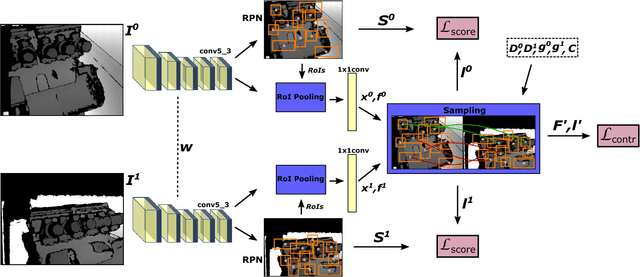
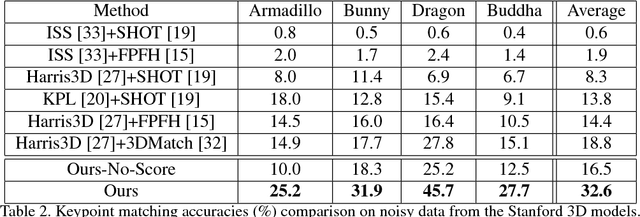
Finding correspondences between images or 3D scans is at the heart of many computer vision and image retrieval applications and is often enabled by matching local keypoint descriptors. Various learning approaches have been applied in the past to different stages of the matching pipeline, considering detector, descriptor, or metric learning objectives. These objectives were typically addressed separately and most previous work has focused on image data. This paper proposes an end-to-end learning framework for keypoint detection and its representation (descriptor) for 3D depth maps or 3D scans, where the two can be jointly optimized towards task-specific objectives without a need for separate annotations. We employ a Siamese architecture augmented by a sampling layer and a novel score loss function which in turn affects the selection of region proposals. The positive and negative examples are obtained automatically by sampling corresponding region proposals based on their consistency with known 3D pose labels. Matching experiments with depth data on multiple benchmark datasets demonstrate the efficacy of the proposed approach, showing significant improvements over state-of-the-art methods.
Learning Compositional Visual Concepts with Mutual Consistency
Mar 28, 2018
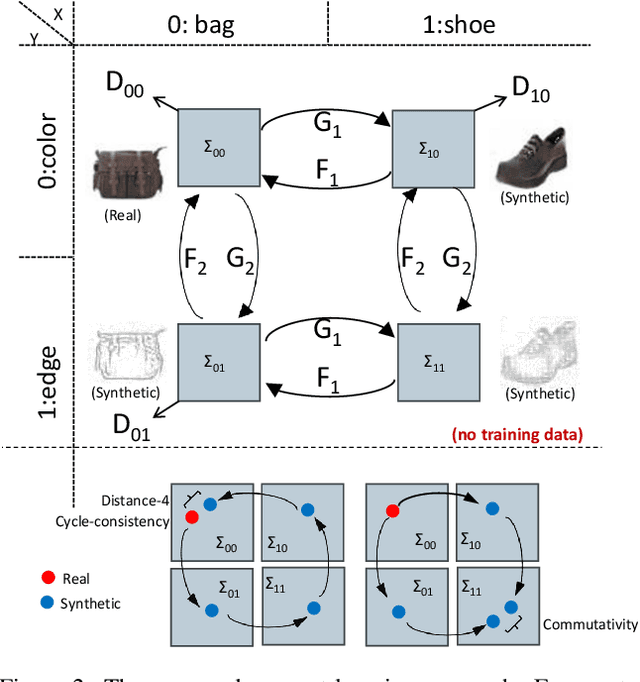


Compositionality of semantic concepts in image synthesis and analysis is appealing as it can help in decomposing known and generatively recomposing unknown data. For instance, we may learn concepts of changing illumination, geometry or albedo of a scene, and try to recombine them to generate physically meaningful, but unseen data for training and testing. In practice however we often do not have samples from the joint concept space available: We may have data on illumination change in one data set and on geometric change in another one without complete overlap. We pose the following question: How can we learn two or more concepts jointly from different data sets with mutual consistency where we do not have samples from the full joint space? We present a novel answer in this paper based on cyclic consistency over multiple concepts, represented individually by generative adversarial networks (GANs). Our method, ConceptGAN, can be understood as a drop in for data augmentation to improve resilience for real world applications. Qualitative and quantitative evaluations demonstrate its efficacy in generating semantically meaningful images, as well as one shot face verification as an example application.
Tell Me Where to Look: Guided Attention Inference Network
Feb 27, 2018
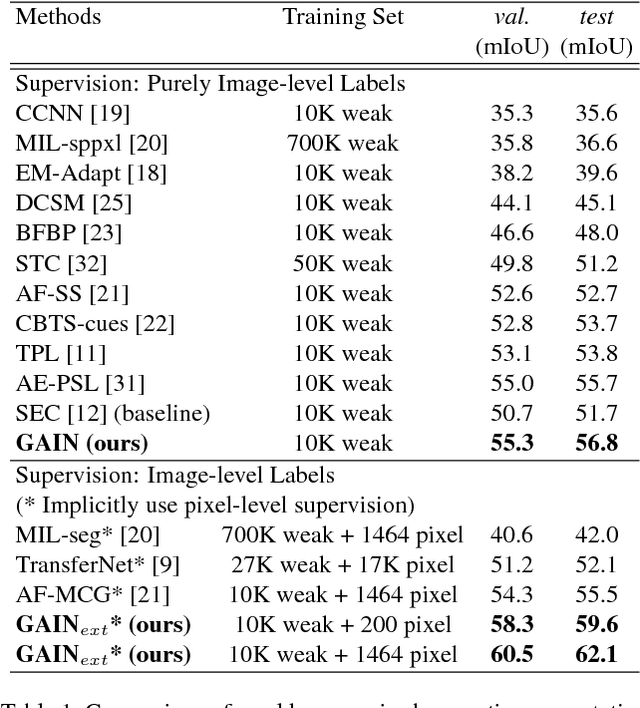
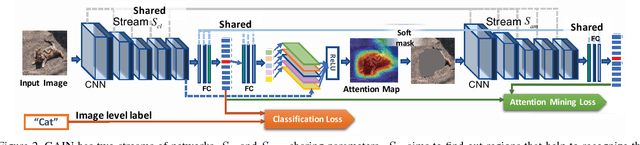
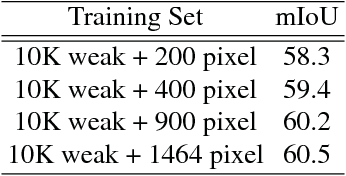
Weakly supervised learning with only coarse labels can obtain visual explanations of deep neural network such as attention maps by back-propagating gradients. These attention maps are then available as priors for tasks such as object localization and semantic segmentation. In one common framework we address three shortcomings of previous approaches in modeling such attention maps: We (1) first time make attention maps an explicit and natural component of the end-to-end training, (2) provide self-guidance directly on these maps by exploring supervision form the network itself to improve them, and (3) seamlessly bridge the gap between using weak and extra supervision if available. Despite its simplicity, experiments on the semantic segmentation task demonstrate the effectiveness of our methods. We clearly surpass the state-of-the-art on Pascal VOC 2012 val. and test set. Besides, the proposed framework provides a way not only explaining the focus of the learner but also feeding back with direct guidance towards specific tasks. Under mild assumptions our method can also be understood as a plug-in to existing weakly supervised learners to improve their generalization performance.
DepthSynth: Real-Time Realistic Synthetic Data Generation from CAD Models for 2.5D Recognition
Nov 28, 2017
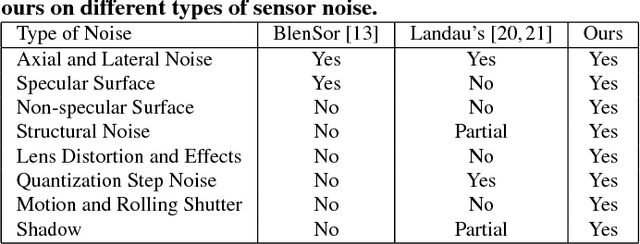
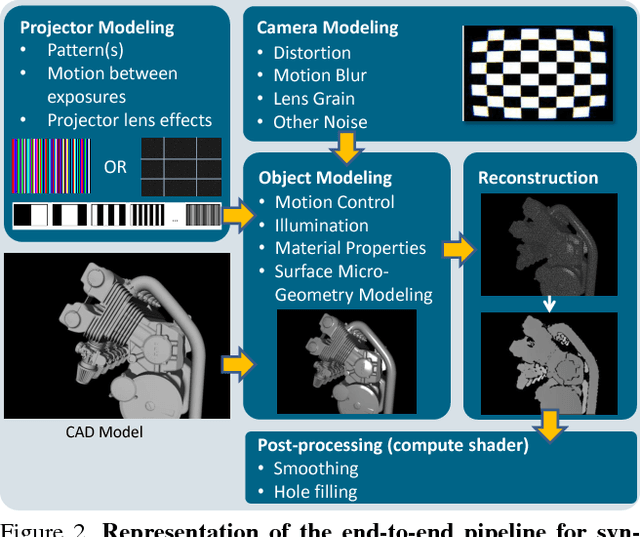

Recent progress in computer vision has been dominated by deep neural networks trained over large amounts of labeled data. Collecting such datasets is however a tedious, often impossible task; hence a surge in approaches relying solely on synthetic data for their training. For depth images however, discrepancies with real scans still noticeably affect the end performance. We thus propose an end-to-end framework which simulates the whole mechanism of these devices, generating realistic depth data from 3D models by comprehensively modeling vital factors e.g. sensor noise, material reflectance, surface geometry. Not only does our solution cover a wider range of sensors and achieve more realistic results than previous methods, assessed through extended evaluation, but we go further by measuring the impact on the training of neural networks for various recognition tasks; demonstrating how our pipeline seamlessly integrates such architectures and consistently enhances their performance.