 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Understanding, Measurement, and Manipulation Using Category Theory
Oct 24, 2025We apply category theory to extract multimodal document structure which leads us to develop information theoretic measures, content summarization and extension, and self-supervised improvement of large pretrained models. We first develop a mathematical representation of a document as a category of question-answer pairs. Second, we develop an orthogonalization procedure to divide the information contained in one or more documents into non-overlapping pieces. The structures extracted in the first and second steps lead us to develop methods to measure and enumerate the information contained in a document. We also build on those steps to develop new summarization techniques, as well as to develop a solution to a new problem viz. exegesis resulting in an extension of the original document. Our question-answer pair methodology enables a novel rate distortion analysis of summarization techniques. We implement our techniques using large pretrained models, and we propose a multimodal extension of our overall mathematical framework. Finally, we develop a novel self-supervised method using RLVR to improve large pretrained models using consistency constraints such as composability and closure under certain operations that stem naturally from our category theoretic framework.
BloomVQA: Assessing Hierarchical Multi-modal Comprehension
Dec 20, 2023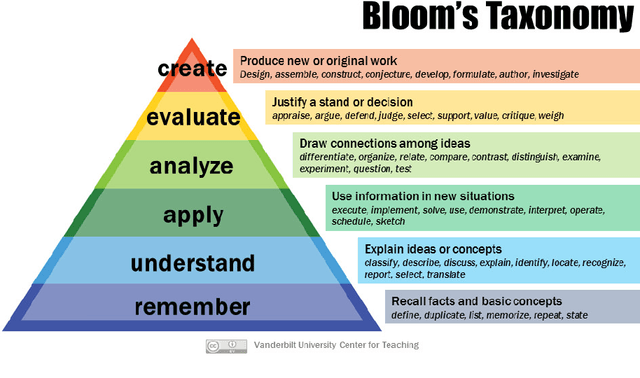
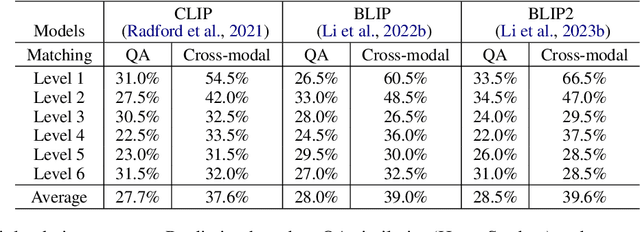

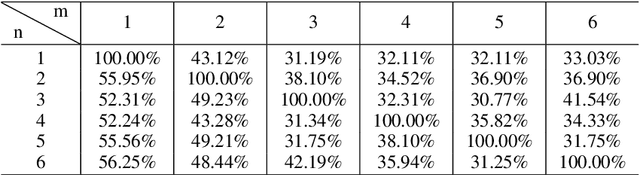
We propose a novel VQA dataset, based on picture stories designed for educating young children, that aims to facilitate comprehensive evaluation and characterization of vision-language models on comprehension tasks. Unlike current VQA datasets that often focus on fact-based memorization and simple reasoning tasks without principled scientific grounding, we collect data containing tasks reflecting different levels of comprehension and underlying cognitive processes, as laid out in Bloom's Taxonomy, a classic framework widely adopted in education research. The proposed BloomVQA dataset can be mapped to a hierarchical graph-based representation of visual stories, enabling automatic data augmentation and novel measures characterizing model consistency across the underlying taxonomy. We demonstrate graded evaluation and reliability analysis based on our proposed consistency metrics on state-of-the-art vision-language models. Our results suggest that, while current models achieve the most gain on low-level comprehension tasks, they generally fall short on high-level tasks requiring more advanced comprehension and cognitive skills, as 38.0% drop in VQA accuracy is observed comparing lowest and highest level tasks. Furthermore, current models show consistency patterns misaligned with human comprehension in various scenarios, suggesting emergent structures of model behaviors.
Uncertainty Propagation through Trained Deep Neural Networks Using Factor Graphs
Dec 10, 2023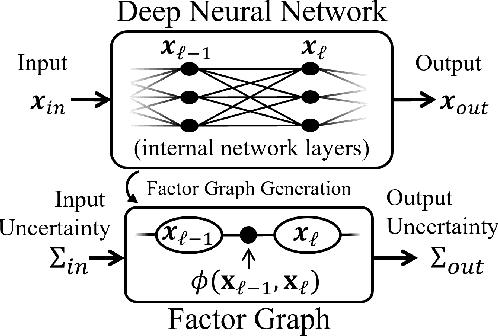
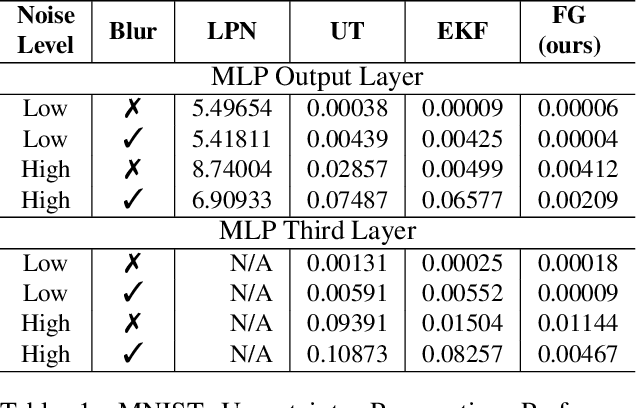
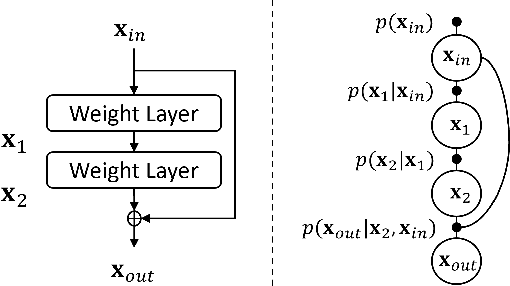
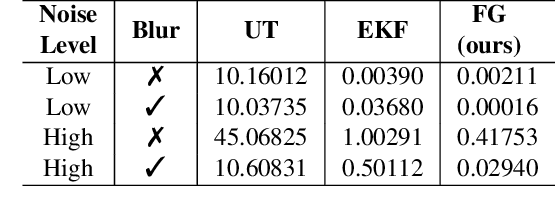
Predictive uncertainty estimation remains a challenging problem precluding the use of deep neural networks as subsystems within safety-critical applications. Aleatoric uncertainty is a component of predictive uncertainty that cannot be reduced through model improvements. Uncertainty propagation seeks to estimate aleatoric uncertainty by propagating input uncertainties to network predictions. Existing uncertainty propagation techniques use one-way information flows, propagating uncertainties layer-by-layer or across the entire neural network while relying either on sampling or analytical techniques for propagation. Motivated by the complex information flows within deep neural networks (e.g. skip connections), we developed and evaluated a novel approach by posing uncertainty propagation as a non-linear optimization problem using factor graphs. We observed statistically significant improvements in performance over prior work when using factor graphs across most of our experiments that included three datasets and two neural network architectures. Our implementation balances the benefits of sampling and analytical propagation techniques, which we believe, is a key factor in achieving performance improvements.
Confidence Calibration for Systems with Cascaded Predictive Modules
Sep 21, 2023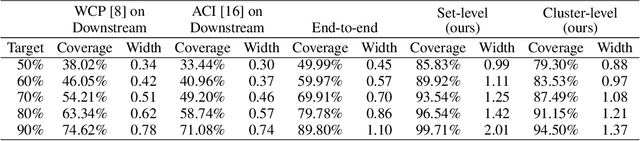
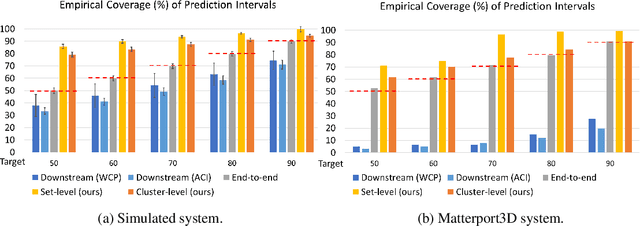
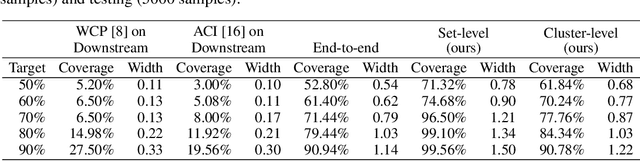
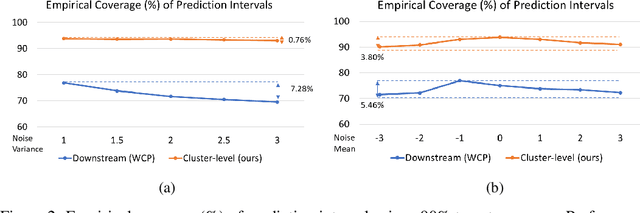
Existing conformal prediction algorithms estimate prediction intervals at target confidence levels to characterize the performance of a regression model on new test samples. However, considering an autonomous system consisting of multiple modules, prediction intervals constructed for individual modules fall short of accommodating uncertainty propagation over different modules and thus cannot provide reliable predictions on system behavior. We address this limitation and present novel solutions based on conformal prediction to provide prediction intervals calibrated for a predictive system consisting of cascaded modules (e.g., an upstream feature extraction module and a downstream regression module). Our key idea is to leverage module-level validation data to characterize the system-level error distribution without direct access to end-to-end validation data. We provide theoretical justification and empirical experimental results to demonstrate the effectiveness of proposed solutions. In comparison to prediction intervals calibrated for individual modules, our solutions generate improved intervals with more accurate performance guarantees for system predictions, which are demonstrated on both synthetic systems and real-world systems performing overlap prediction for indoor navigation using the Matterport3D dataset.
Unpacking Large Language Models with Conceptual Consistency
Sep 29, 2022

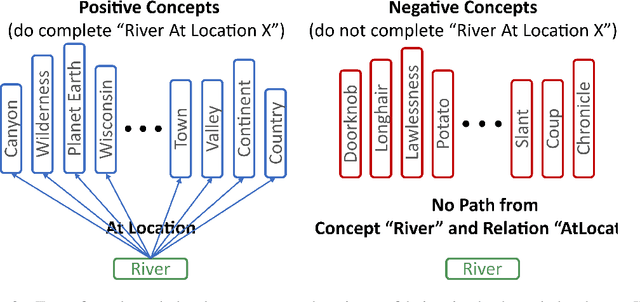

If a Large Language Model (LLM) answers "yes" to the question "Are mountains tall?" then does it know what a mountain is? Can you rely on it responding correctly or incorrectly to other questions about mountains? The success of Large Language Models (LLMs) indicates they are increasingly able to answer queries like these accurately, but that ability does not necessarily imply a general understanding of concepts relevant to the anchor query. We propose conceptual consistency to measure a LLM's understanding of relevant concepts. This novel metric measures how well a model can be characterized by finding out how consistent its responses to queries about conceptually relevant background knowledge are. To compute it we extract background knowledge by traversing paths between concepts in a knowledge base and then try to predict the model's response to the anchor query from the background knowledge. We investigate the performance of current LLMs in a commonsense reasoning setting using the CSQA dataset and the ConceptNet knowledge base. While conceptual consistency, like other metrics, does increase with the scale of the LLM used, we find that popular models do not necessarily have high conceptual consistency. Our analysis also shows significant variation in conceptual consistency across different kinds of relations, concepts, and prompts. This serves as a step toward building models that humans can apply a theory of mind to, and thus interact with intuitively.
Confidence Calibration for Domain Generalization under Covariate Shift
Apr 01, 2021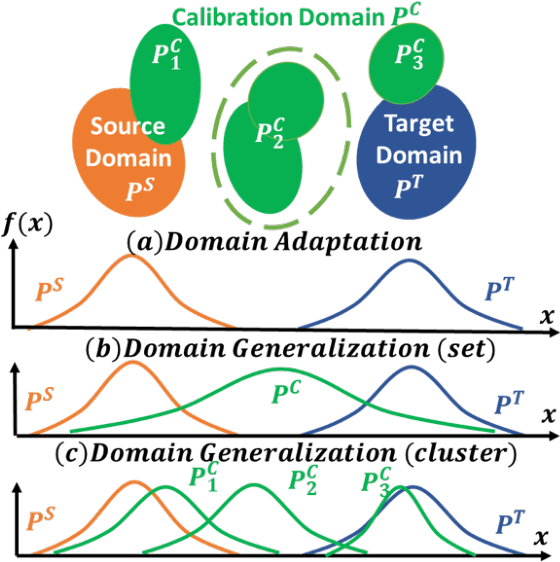
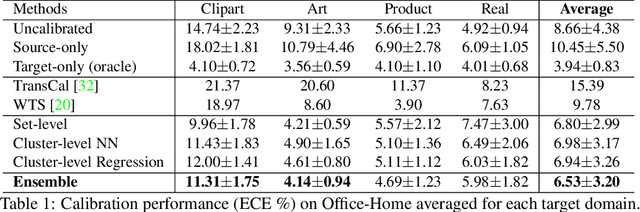
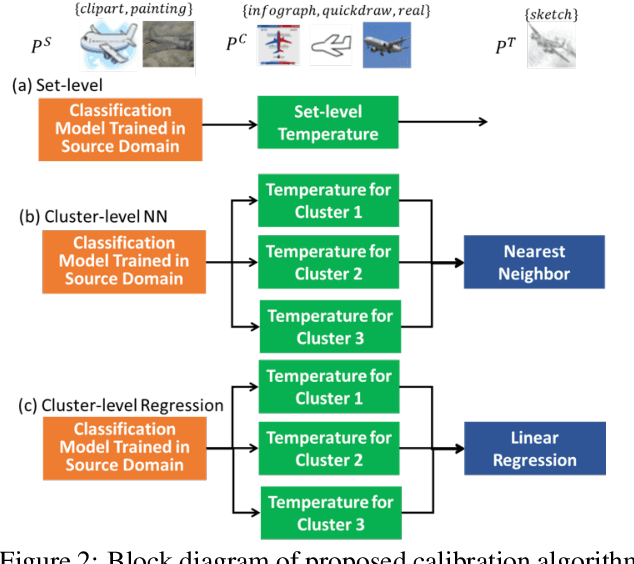
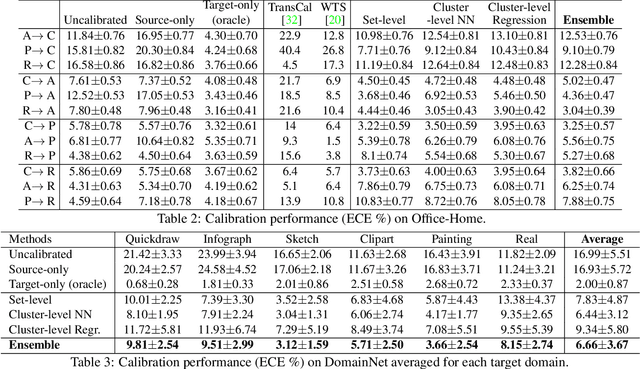
Existing calibration algorithms address the problem of covariate shift via unsupervised domain adaptation. However, these methods suffer from the following limitations: 1) they require unlabeled data from the target domain, which may not be available at the stage of calibration in real-world applications and 2) their performances heavily depend on the disparity between the distributions of the source and target domains. To address these two limitations, we present novel calibration solutions via domain generalization which, to the best of our knowledge, are the first of their kind. Our core idea is to leverage multiple calibration domains to reduce the effective distribution disparity between the target and calibration domains for improved calibration transfer without needing any data from the target domain. We provide theoretical justification and empirical experimental results to demonstrate the effectiveness of our proposed algorithms. Compared against the state-of-the-art calibration methods designed for domain adaptation, we observe a decrease of 8.86 percentage points in expected calibration error, equivalently an increase of 35 percentage points in improvement ratio, for multi-class classification on the Office-Home dataset.
Modular Adaptation for Cross-Domain Few-Shot Learning
Apr 01, 2021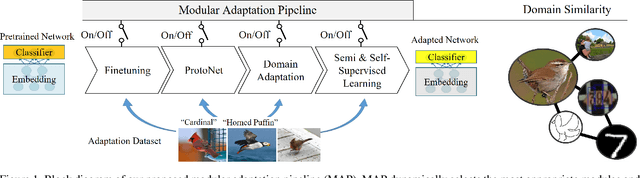
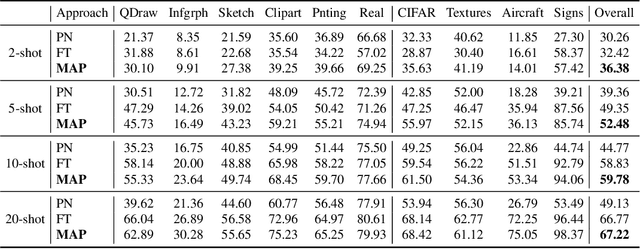
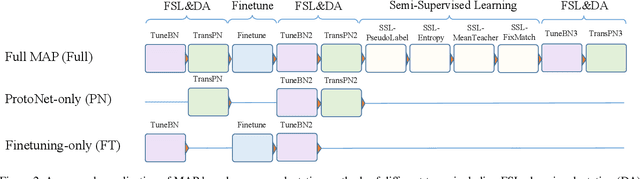
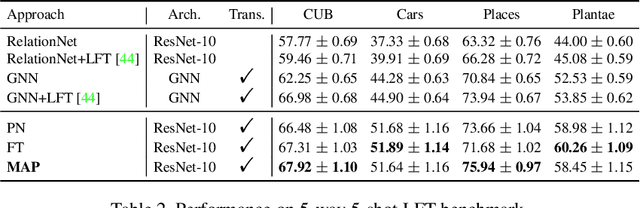
Adapting pre-trained representations has become the go-to recipe for learning new downstream tasks with limited examples. While literature has demonstrated great successes via representation learning, in this work, we show that substantial performance improvement of downstream tasks can also be achieved by appropriate designs of the adaptation process. Specifically, we propose a modular adaptation method that selectively performs multiple state-of-the-art (SOTA) adaptation methods in sequence. As different downstream tasks may require different types of adaptation, our modular adaptation enables the dynamic configuration of the most suitable modules based on the downstream task. Moreover, as an extension to existing cross-domain 5-way k-shot benchmarks (e.g., miniImageNet -> CUB), we create a new high-way (~100) k-shot benchmark with data from 10 different datasets. This benchmark provides a diverse set of domains and allows the use of stronger representations learned from ImageNet. Experimental results show that by customizing adaptation process towards downstream tasks, our modular adaptation pipeline (MAP) improves 3.1% in 5-shot classification accuracy over baselines of finetuning and Prototypical Networks.
Learning Compositional Visual Concepts with Mutual Consistency
Mar 28, 2018
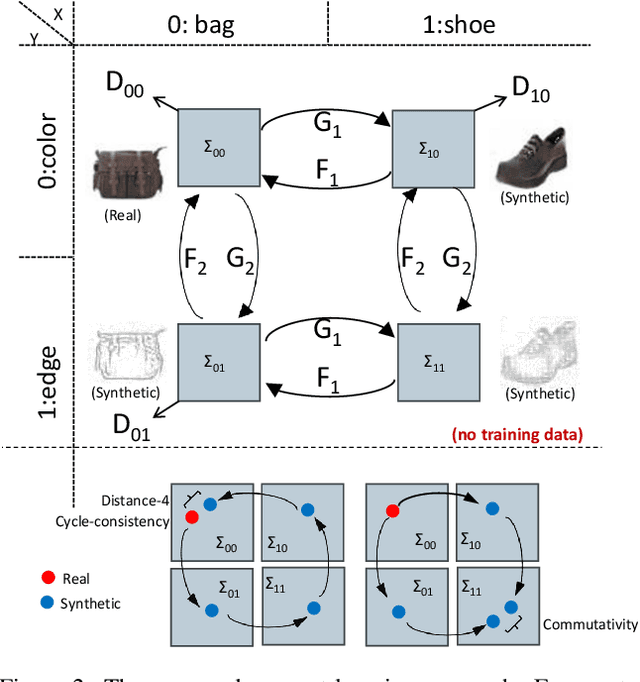


Compositionality of semantic concepts in image synthesis and analysis is appealing as it can help in decomposing known and generatively recomposing unknown data. For instance, we may learn concepts of changing illumination, geometry or albedo of a scene, and try to recombine them to generate physically meaningful, but unseen data for training and testing. In practice however we often do not have samples from the joint concept space available: We may have data on illumination change in one data set and on geometric change in another one without complete overlap. We pose the following question: How can we learn two or more concepts jointly from different data sets with mutual consistency where we do not have samples from the full joint space? We present a novel answer in this paper based on cyclic consistency over multiple concepts, represented individually by generative adversarial networks (GANs). Our method, ConceptGAN, can be understood as a drop in for data augmentation to improve resilience for real world applications. Qualitative and quantitative evaluations demonstrate its efficacy in generating semantically meaningful images, as well as one shot face verification as an example application.