 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteEmbed: Adapting CLIP to Rare Classes
Jan 14, 2026Large-scale vision-language models such as CLIP achieve strong zero-shot recognition but struggle with classes that are rarely seen during pretraining, including newly emerging entities and culturally specific categories. We introduce LiteEmbed, a lightweight framework for few-shot personalization of CLIP that enables new classes to be added without retraining its encoders. LiteEmbed performs subspace-guided optimization of text embeddings within CLIP's vocabulary, leveraging a PCA-based decomposition that disentangles coarse semantic directions from fine-grained variations. Two complementary objectives, coarse alignment and fine separation, jointly preserve global semantic consistency while enhancing discriminability among visually similar classes. Once optimized, the embeddings are plug-and-play, seamlessly substituting CLIP's original text features across classification, retrieval, segmentation, and detection tasks. Extensive experiments demonstrate substantial gains over prior methods, establishing LiteEmbed as an effective approach for adapting CLIP to underrepresented, rare, or unseen classes.
Concept Regions Matter: Benchmarking CLIP with a New Cluster-Importance Approach
Nov 17, 2025Contrastive vision-language models (VLMs) such as CLIP achieve strong zero-shot recognition yet remain vulnerable to spurious correlations, particularly background over-reliance. We introduce Cluster-based Concept Importance (CCI), a novel interpretability method that uses CLIP's own patch embeddings to group spatial patches into semantically coherent clusters, mask them, and evaluate relative changes in model predictions. CCI sets a new state of the art on faithfulness benchmarks, surpassing prior methods by large margins; for example, it yields more than a twofold improvement on the deletion-AUC metric for MS COCO retrieval. We further propose that CCI, when combined with GroundedSAM, automatically categorizes predictions as foreground- or background-driven, providing a crucial diagnostic ability. Existing benchmarks such as CounterAnimals, however, rely solely on accuracy and implicitly attribute all performance degradation to background correlations. Our analysis shows this assumption to be incomplete, since many errors arise from viewpoint variation, scale shifts, and fine-grained object confusions. To disentangle these effects, we introduce COVAR, a benchmark that systematically varies object foregrounds and backgrounds. Leveraging CCI with COVAR, we present a comprehensive evaluation of eighteen CLIP variants, offering methodological advances and empirical evidence that chart a path toward more robust VLMs.
CoCoNO: Attention Contrast-and-Complete for Initial Noise Optimization in Text-to-Image Synthesis
Nov 25, 2024



Despite recent advancements in text-to-image models, achieving semantically accurate images in text-to-image diffusion models is a persistent challenge. While existing initial latent optimization methods have demonstrated impressive performance, we identify two key limitations: (a) attention neglect, where the synthesized image omits certain subjects from the input prompt because they do not have a designated segment in the self-attention map despite despite having a high-response cross-attention, and (b) attention interference, where the generated image has mixed-up properties of multiple subjects because of a conflicting overlap between cross- and self-attention maps of different subjects. To address these limitations, we introduce CoCoNO, a new algorithm that optimizes the initial latent by leveraging the complementary information within self-attention and cross-attention maps. Our method introduces two new loss functions: the attention contrast loss, which minimizes undesirable overlap by ensuring each self-attention segment is exclusively linked to a specific subject's cross attention map, and the attention complete loss, which maximizes the activation within these segments to guarantee that each subject is fully and distinctly represented. Our approach operates within a noise optimization framework, avoiding the need to retrain base models. Through extensive experiments on multiple benchmarks, we demonstrate that CoCoNO significantly improves text-image alignment and outperforms the current state of the art.
TIDE: Training Locally Interpretable Domain Generalization Models Enables Test-time Correction
Nov 25, 2024
We consider the problem of single-source domain generalization. Existing methods typically rely on extensive augmentations to synthetically cover diverse domains during training. However, they struggle with semantic shifts (e.g., background and viewpoint changes), as they often learn global features instead of local concepts that tend to be domain invariant. To address this gap, we propose an approach that compels models to leverage such local concepts during prediction. Given no suitable dataset with per-class concepts and localization maps exists, we first develop a novel pipeline to generate annotations by exploiting the rich features of diffusion and large-language models. Our next innovation is TIDE, a novel training scheme with a concept saliency alignment loss that ensures model focus on the right per-concept regions and a local concept contrastive loss that promotes learning domain-invariant concept representations. This not only gives a robust model but also can be visually interpreted using the predicted concept saliency maps. Given these maps at test time, our final contribution is a new correction algorithm that uses the corresponding local concept representations to iteratively refine the prediction until it aligns with prototypical concept representations that we store at the end of model training. We evaluate our approach extensively on four standard DG benchmark datasets and substantially outperform the current state-ofthe-art (12% improvement on average) while also demonstrating that our predictions can be visually interpreted
Test-time Conditional Text-to-Image Synthesis Using Diffusion Models
Nov 16, 2024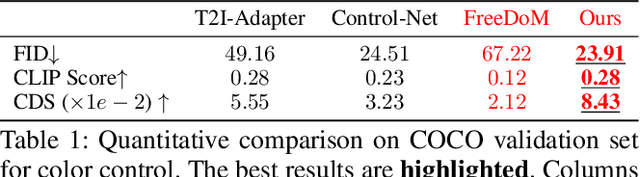
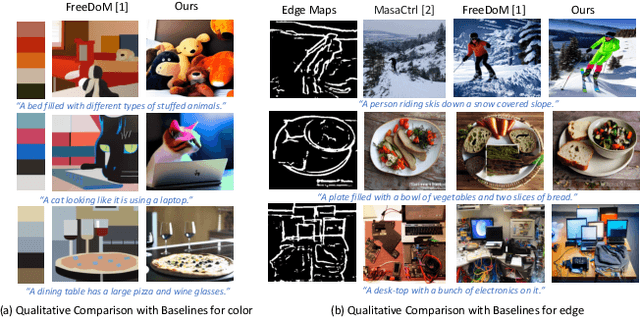
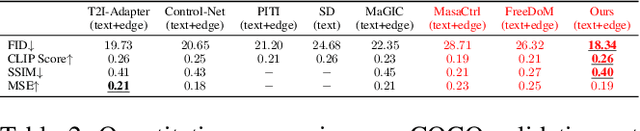
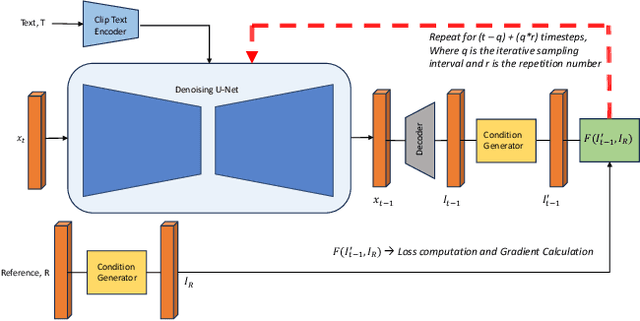
We consider the problem of conditional text-to-image synthesis with diffusion models. Most recent works need to either finetune specific parts of the base diffusion model or introduce new trainable parameters, leading to deployment inflexibility due to the need for training. To address this gap in the current literature, we propose our method called TINTIN: Test-time Conditional Text-to-Image Synthesis using Diffusion Models which is a new training-free test-time only algorithm to condition text-to-image diffusion model outputs on conditioning factors such as color palettes and edge maps. In particular, we propose to interpret noise predictions during denoising as gradients of an energy-based model, leading to a flexible approach to manipulate the noise by matching predictions inferred from them to the ground truth conditioning input. This results in, to the best of our knowledge, the first approach to control model outputs with input color palettes, which we realize using a novel color distribution matching loss. We also show this test-time noise manipulation can be easily extensible to other types of conditioning, e.g., edge maps. We conduct extensive experiments using a variety of text prompts, color palettes, and edge maps and demonstrate significant improvement over the current state-of-the-art, both qualitatively and quantitatively.
Training-free Color-Style Disentanglement for Constrained Text-to-Image Synthesis
Sep 04, 2024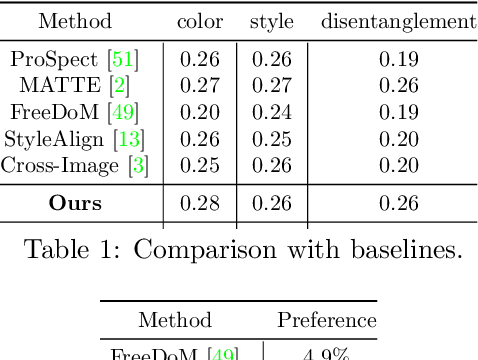

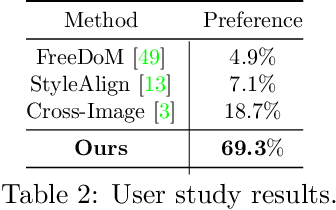

We consider the problem of independently, in a disentangled fashion, controlling the outputs of text-to-image diffusion models with color and style attributes of a user-supplied reference image. We present the first training-free, test-time-only method to disentangle and condition text-to-image models on color and style attributes from reference image. To realize this, we propose two key innovations. Our first contribution is to transform the latent codes at inference time using feature transformations that make the covariance matrix of current generation follow that of the reference image, helping meaningfully transfer color. Next, we observe that there exists a natural disentanglement between color and style in the LAB image space, which we exploit to transform the self-attention feature maps of the image being generated with respect to those of the reference computed from its L channel. Both these operations happen purely at test time and can be done independently or merged. This results in a flexible method where color and style information can come from the same reference image or two different sources, and a new generation can seamlessly fuse them in either scenario.
SafaRi:Adaptive Sequence Transformer for Weakly Supervised Referring Expression Segmentation
Jul 02, 2024
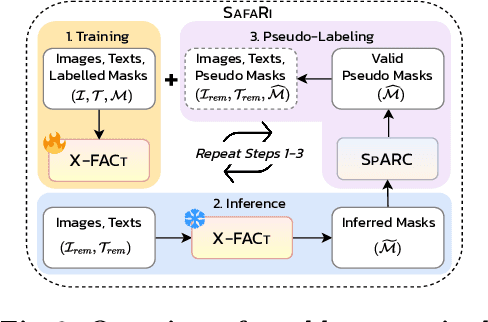
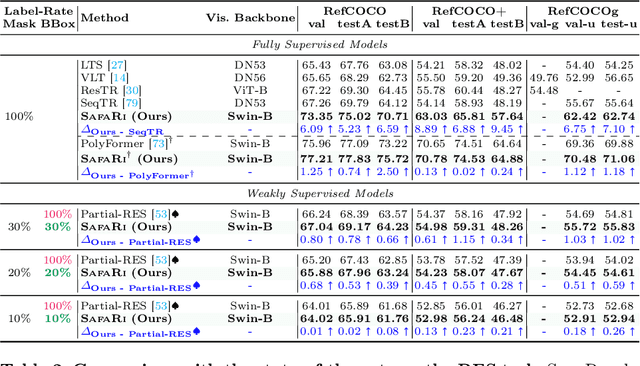
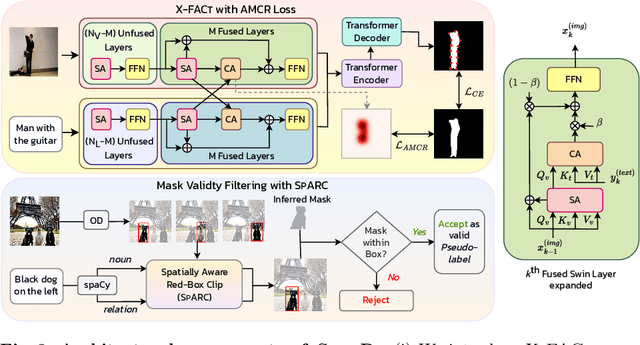
Referring Expression Segmentation (RES) aims to provide a segmentation mask of the target object in an image referred to by the text (i.e., referring expression). Existing methods require large-scale mask annotations. Moreover, such approaches do not generalize well to unseen/zero-shot scenarios. To address the aforementioned issues, we propose a weakly-supervised bootstrapping architecture for RES with several new algorithmic innovations. To the best of our knowledge, ours is the first approach that considers only a fraction of both mask and box annotations (shown in Figure 1 and Table 1) for training. To enable principled training of models in such low-annotation settings, improve image-text region-level alignment, and further enhance spatial localization of the target object in the image, we propose Cross-modal Fusion with Attention Consistency module. For automatic pseudo-labeling of unlabeled samples, we introduce a novel Mask Validity Filtering routine based on a spatially aware zero-shot proposal scoring approach. Extensive experiments show that with just 30% annotations, our model SafaRi achieves 59.31 and 48.26 mIoUs as compared to 58.93 and 48.19 mIoUs obtained by the fully-supervised SOTA method SeqTR respectively on RefCOCO+@testA and RefCOCO+testB datasets. SafaRi also outperforms SeqTR by 11.7% (on RefCOCO+testA) and 19.6% (on RefCOCO+testB) in a fully-supervised setting and demonstrates strong generalization capabilities in unseen/zero-shot tasks.
AlignIT: Enhancing Prompt Alignment in Customization of Text-to-Image Models
Jun 27, 2024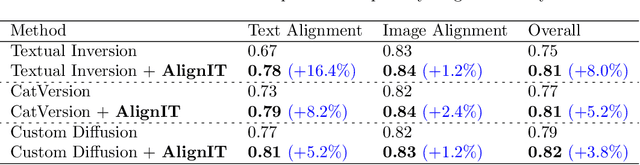



We consider the problem of customizing text-to-image diffusion models with user-supplied reference images. Given new prompts, the existing methods can capture the key concept from the reference images but fail to align the generated image with the prompt. In this work, we seek to address this key issue by proposing new methods that can easily be used in conjunction with existing customization methods that optimize the embeddings/weights at various intermediate stages of the text encoding process. The first contribution of this paper is a dissection of the various stages of the text encoding process leading up to the conditioning vector for text-to-image models. We take a holistic view of existing customization methods and notice that key and value outputs from this process differs substantially from their corresponding baseline (non-customized) models (e.g., baseline stable diffusion). While this difference does not impact the concept being customized, it leads to other parts of the generated image not being aligned with the prompt (see first row in Fig 1). Further, we also observe that these keys and values allow independent control various aspects of the final generation, enabling semantic manipulation of the output. Taken together, the features spanning these keys and values, serve as the basis for our next contribution where we fix the aforementioned issues with existing methods. We propose a new post-processing algorithm, \textbf{AlignIT}, that infuses the keys and values for the concept of interest while ensuring the keys and values for all other tokens in the input prompt are unchanged. Our proposed method can be plugged in directly to existing customization methods, leading to a substantial performance improvement in the alignment of the final result with the input prompt while retaining the customization quality.
Crafting Parts for Expressive Object Composition
Jun 14, 2024Text-to-image generation from large generative models like Stable Diffusion, DALLE-2, etc., have become a common base for various tasks due to their superior quality and extensive knowledge bases. As image composition and generation are creative processes the artists need control over various parts of the images being generated. We find that just adding details about parts in the base text prompt either leads to an entirely different image (e.g., missing/incorrect identity) or the extra part details simply being ignored. To mitigate these issues, we introduce PartCraft, which enables image generation based on fine-grained part-level details specified for objects in the base text prompt. This allows more control for artists and enables novel object compositions by combining distinctive object parts. PartCraft first localizes object parts by denoising the object region from a specific diffusion process. This enables each part token to be localized to the right object region. After obtaining part masks, we run a localized diffusion process in each of the part regions based on fine-grained part descriptions and combine them to produce the final image. All the stages of PartCraft are based on repurposing a pre-trained diffusion model, which enables it to generalize across various domains without training. We demonstrate the effectiveness of part-level control provided by PartCraft qualitatively through visual examples and quantitatively in comparison to the contemporary baselines.
Few Shot Class Incremental Learning using Vision-Language models
May 02, 2024Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.