 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Color-Style Disentanglement for Constrained Text-to-Image Synthesis
Paper and Code
Sep 04, 2024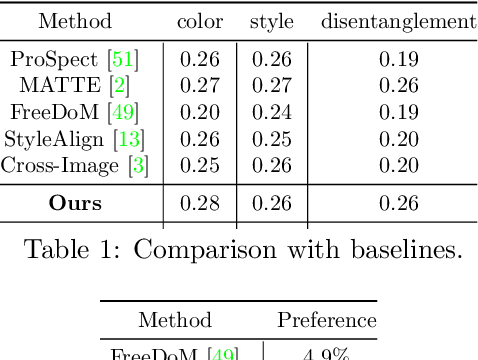

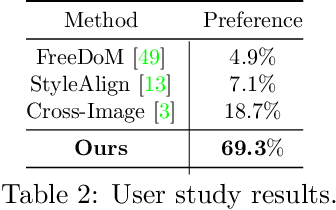

We consider the problem of independently, in a disentangled fashion, controlling the outputs of text-to-image diffusion models with color and style attributes of a user-supplied reference image. We present the first training-free, test-time-only method to disentangle and condition text-to-image models on color and style attributes from reference image. To realize this, we propose two key innovations. Our first contribution is to transform the latent codes at inference time using feature transformations that make the covariance matrix of current generation follow that of the reference image, helping meaningfully transfer color. Next, we observe that there exists a natural disentanglement between color and style in the LAB image space, which we exploit to transform the self-attention feature maps of the image being generated with respect to those of the reference computed from its L channel. Both these operations happen purely at test time and can be done independently or merged. This results in a flexible method where color and style information can come from the same reference image or two different sources, and a new generation can seamlessly fuse them in either scenario.