 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteEmbed: Adapting CLIP to Rare Classes
Jan 14, 2026Large-scale vision-language models such as CLIP achieve strong zero-shot recognition but struggle with classes that are rarely seen during pretraining, including newly emerging entities and culturally specific categories. We introduce LiteEmbed, a lightweight framework for few-shot personalization of CLIP that enables new classes to be added without retraining its encoders. LiteEmbed performs subspace-guided optimization of text embeddings within CLIP's vocabulary, leveraging a PCA-based decomposition that disentangles coarse semantic directions from fine-grained variations. Two complementary objectives, coarse alignment and fine separation, jointly preserve global semantic consistency while enhancing discriminability among visually similar classes. Once optimized, the embeddings are plug-and-play, seamlessly substituting CLIP's original text features across classification, retrieval, segmentation, and detection tasks. Extensive experiments demonstrate substantial gains over prior methods, establishing LiteEmbed as an effective approach for adapting CLIP to underrepresented, rare, or unseen classes.
Concept Regions Matter: Benchmarking CLIP with a New Cluster-Importance Approach
Nov 17, 2025Contrastive vision-language models (VLMs) such as CLIP achieve strong zero-shot recognition yet remain vulnerable to spurious correlations, particularly background over-reliance. We introduce Cluster-based Concept Importance (CCI), a novel interpretability method that uses CLIP's own patch embeddings to group spatial patches into semantically coherent clusters, mask them, and evaluate relative changes in model predictions. CCI sets a new state of the art on faithfulness benchmarks, surpassing prior methods by large margins; for example, it yields more than a twofold improvement on the deletion-AUC metric for MS COCO retrieval. We further propose that CCI, when combined with GroundedSAM, automatically categorizes predictions as foreground- or background-driven, providing a crucial diagnostic ability. Existing benchmarks such as CounterAnimals, however, rely solely on accuracy and implicitly attribute all performance degradation to background correlations. Our analysis shows this assumption to be incomplete, since many errors arise from viewpoint variation, scale shifts, and fine-grained object confusions. To disentangle these effects, we introduce COVAR, a benchmark that systematically varies object foregrounds and backgrounds. Leveraging CCI with COVAR, we present a comprehensive evaluation of eighteen CLIP variants, offering methodological advances and empirical evidence that chart a path toward more robust VLMs.
CoCoNO: Attention Contrast-and-Complete for Initial Noise Optimization in Text-to-Image Synthesis
Nov 25, 2024



Despite recent advancements in text-to-image models, achieving semantically accurate images in text-to-image diffusion models is a persistent challenge. While existing initial latent optimization methods have demonstrated impressive performance, we identify two key limitations: (a) attention neglect, where the synthesized image omits certain subjects from the input prompt because they do not have a designated segment in the self-attention map despite despite having a high-response cross-attention, and (b) attention interference, where the generated image has mixed-up properties of multiple subjects because of a conflicting overlap between cross- and self-attention maps of different subjects. To address these limitations, we introduce CoCoNO, a new algorithm that optimizes the initial latent by leveraging the complementary information within self-attention and cross-attention maps. Our method introduces two new loss functions: the attention contrast loss, which minimizes undesirable overlap by ensuring each self-attention segment is exclusively linked to a specific subject's cross attention map, and the attention complete loss, which maximizes the activation within these segments to guarantee that each subject is fully and distinctly represented. Our approach operates within a noise optimization framework, avoiding the need to retrain base models. Through extensive experiments on multiple benchmarks, we demonstrate that CoCoNO significantly improves text-image alignment and outperforms the current state of the art.
TIDE: Training Locally Interpretable Domain Generalization Models Enables Test-time Correction
Nov 25, 2024
We consider the problem of single-source domain generalization. Existing methods typically rely on extensive augmentations to synthetically cover diverse domains during training. However, they struggle with semantic shifts (e.g., background and viewpoint changes), as they often learn global features instead of local concepts that tend to be domain invariant. To address this gap, we propose an approach that compels models to leverage such local concepts during prediction. Given no suitable dataset with per-class concepts and localization maps exists, we first develop a novel pipeline to generate annotations by exploiting the rich features of diffusion and large-language models. Our next innovation is TIDE, a novel training scheme with a concept saliency alignment loss that ensures model focus on the right per-concept regions and a local concept contrastive loss that promotes learning domain-invariant concept representations. This not only gives a robust model but also can be visually interpreted using the predicted concept saliency maps. Given these maps at test time, our final contribution is a new correction algorithm that uses the corresponding local concept representations to iteratively refine the prediction until it aligns with prototypical concept representations that we store at the end of model training. We evaluate our approach extensively on four standard DG benchmark datasets and substantially outperform the current state-ofthe-art (12% improvement on average) while also demonstrating that our predictions can be visually interpreted
Training-free Color-Style Disentanglement for Constrained Text-to-Image Synthesis
Sep 04, 2024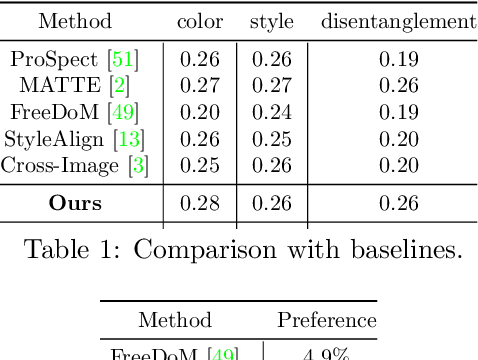

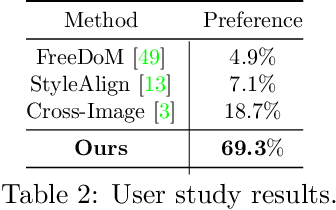

We consider the problem of independently, in a disentangled fashion, controlling the outputs of text-to-image diffusion models with color and style attributes of a user-supplied reference image. We present the first training-free, test-time-only method to disentangle and condition text-to-image models on color and style attributes from reference image. To realize this, we propose two key innovations. Our first contribution is to transform the latent codes at inference time using feature transformations that make the covariance matrix of current generation follow that of the reference image, helping meaningfully transfer color. Next, we observe that there exists a natural disentanglement between color and style in the LAB image space, which we exploit to transform the self-attention feature maps of the image being generated with respect to those of the reference computed from its L channel. Both these operations happen purely at test time and can be done independently or merged. This results in a flexible method where color and style information can come from the same reference image or two different sources, and a new generation can seamlessly fuse them in either scenario.
AlignIT: Enhancing Prompt Alignment in Customization of Text-to-Image Models
Jun 27, 2024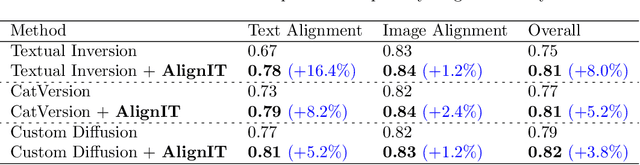



We consider the problem of customizing text-to-image diffusion models with user-supplied reference images. Given new prompts, the existing methods can capture the key concept from the reference images but fail to align the generated image with the prompt. In this work, we seek to address this key issue by proposing new methods that can easily be used in conjunction with existing customization methods that optimize the embeddings/weights at various intermediate stages of the text encoding process. The first contribution of this paper is a dissection of the various stages of the text encoding process leading up to the conditioning vector for text-to-image models. We take a holistic view of existing customization methods and notice that key and value outputs from this process differs substantially from their corresponding baseline (non-customized) models (e.g., baseline stable diffusion). While this difference does not impact the concept being customized, it leads to other parts of the generated image not being aligned with the prompt (see first row in Fig 1). Further, we also observe that these keys and values allow independent control various aspects of the final generation, enabling semantic manipulation of the output. Taken together, the features spanning these keys and values, serve as the basis for our next contribution where we fix the aforementioned issues with existing methods. We propose a new post-processing algorithm, \textbf{AlignIT}, that infuses the keys and values for the concept of interest while ensuring the keys and values for all other tokens in the input prompt are unchanged. Our proposed method can be plugged in directly to existing customization methods, leading to a substantial performance improvement in the alignment of the final result with the input prompt while retaining the customization quality.
Crafting Parts for Expressive Object Composition
Jun 14, 2024Text-to-image generation from large generative models like Stable Diffusion, DALLE-2, etc., have become a common base for various tasks due to their superior quality and extensive knowledge bases. As image composition and generation are creative processes the artists need control over various parts of the images being generated. We find that just adding details about parts in the base text prompt either leads to an entirely different image (e.g., missing/incorrect identity) or the extra part details simply being ignored. To mitigate these issues, we introduce PartCraft, which enables image generation based on fine-grained part-level details specified for objects in the base text prompt. This allows more control for artists and enables novel object compositions by combining distinctive object parts. PartCraft first localizes object parts by denoising the object region from a specific diffusion process. This enables each part token to be localized to the right object region. After obtaining part masks, we run a localized diffusion process in each of the part regions based on fine-grained part descriptions and combine them to produce the final image. All the stages of PartCraft are based on repurposing a pre-trained diffusion model, which enables it to generalize across various domains without training. We demonstrate the effectiveness of part-level control provided by PartCraft qualitatively through visual examples and quantitatively in comparison to the contemporary baselines.
An Image is Worth Multiple Words: Multi-attribute Inversion for Constrained Text-to-Image Synthesis
Nov 20, 2023We consider the problem of constraining diffusion model outputs with a user-supplied reference image. Our key objective is to extract multiple attributes (e.g., color, object, layout, style) from this single reference image, and then generate new samples with them. One line of existing work proposes to invert the reference images into a single textual conditioning vector, enabling generation of new samples with this learned token. These methods, however, do not learn multiple tokens that are necessary to condition model outputs on the multiple attributes noted above. Another line of techniques expand the inversion space to learn multiple embeddings but they do this only along the layer dimension (e.g., one per layer of the DDPM model) or the timestep dimension (one for a set of timesteps in the denoising process), leading to suboptimal attribute disentanglement. To address the aforementioned gaps, the first contribution of this paper is an extensive analysis to determine which attributes are captured in which dimension of the denoising process. As noted above, we consider both the time-step dimension (in reverse denoising) as well as the DDPM model layer dimension. We observe that often a subset of these attributes are captured in the same set of model layers and/or across same denoising timesteps. For instance, color and style are captured across same U-Net layers, whereas layout and color are captured across same timestep stages. Consequently, an inversion process that is designed only for the time-step dimension or the layer dimension is insufficient to disentangle all attributes. This leads to our second contribution where we design a new multi-attribute inversion algorithm, MATTE, with associated disentanglement-enhancing regularization losses, that operates across both dimensions and explicitly leads to four disentangled tokens (color, style, layout, and object).
Iterative Multi-granular Image Editing using Diffusion Models
Sep 01, 2023



Recent advances in text-guided image synthesis has dramatically changed how creative professionals generate artistic and aesthetically pleasing visual assets. To fully support such creative endeavors, the process should possess the ability to: 1) iteratively edit the generations and 2) control the spatial reach of desired changes (global, local or anything in between). We formalize this pragmatic problem setting as Iterative Multi-granular Editing. While there has been substantial progress with diffusion-based models for image synthesis and editing, they are all one shot (i.e., no iterative editing capabilities) and do not naturally yield multi-granular control (i.e., covering the full spectrum of local-to-global edits). To overcome these drawbacks, we propose EMILIE: Iterative Multi-granular Image Editor. EMILIE introduces a novel latent iteration strategy, which re-purposes a pre-trained diffusion model to facilitate iterative editing. This is complemented by a gradient control operation for multi-granular control. We introduce a new benchmark dataset to evaluate our newly proposed setting. We conduct exhaustive quantitatively and qualitatively evaluation against recent state-of-the-art approaches adapted to our task, to being out the mettle of EMILIE. We hope our work would attract attention to this newly identified, pragmatic problem setting.
A-STAR: Test-time Attention Segregation and Retention for Text-to-image Synthesis
Jun 26, 2023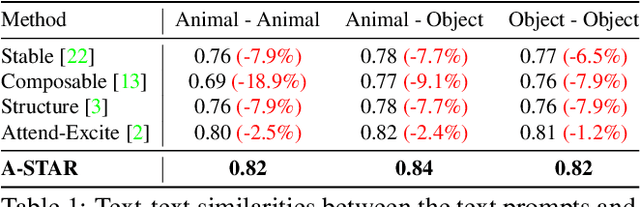
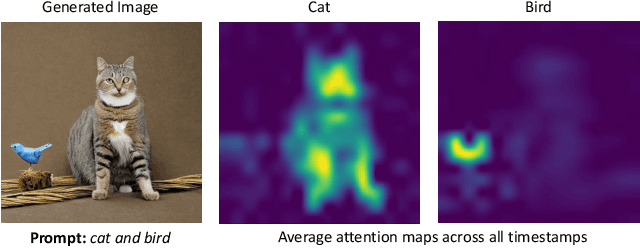
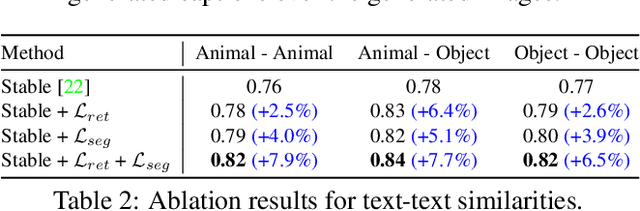

While recent developments in text-to-image generative models have led to a suite of high-performing methods capable of producing creative imagery from free-form text, there are several limitations. By analyzing the cross-attention representations of these models, we notice two key issues. First, for text prompts that contain multiple concepts, there is a significant amount of pixel-space overlap (i.e., same spatial regions) among pairs of different concepts. This eventually leads to the model being unable to distinguish between the two concepts and one of them being ignored in the final generation. Next, while these models attempt to capture all such concepts during the beginning of denoising (e.g., first few steps) as evidenced by cross-attention maps, this knowledge is not retained by the end of denoising (e.g., last few steps). Such loss of knowledge eventually leads to inaccurate generation outputs. To address these issues, our key innovations include two test-time attention-based loss functions that substantially improve the performance of pretrained baseline text-to-image diffusion models. First, our attention segregation loss reduces the cross-attention overlap between attention maps of different concepts in the text prompt, thereby reducing the confusion/conflict among various concepts and the eventual capture of all concepts in the generated output. Next, our attention retention loss explicitly forces text-to-image diffusion models to retain cross-attention information for all concepts across all denoising time steps, thereby leading to reduced information loss and the preservation of all concepts in the generated output.