 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale Space Diffusion
Mar 09, 2026Diffusion models degrade images through noise, and reversing this process reveals an information hierarchy across timesteps. Scale-space theory exhibits a similar hierarchy via low-pass filtering. We formalize this connection and show that highly noisy diffusion states contain no more information than small, downsampled images - raising the question of why they must be processed at full resolution. To address this, we fuse scale spaces into the diffusion process by formulating a family of diffusion models with generalized linear degradations and practical implementations. Using downsampling as the degradation yields our proposed Scale Space Diffusion. To support Scale Space Diffusion, we introduce Flexi-UNet, a UNet variant that performs resolution-preserving and resolution-increasing denoising using only the necessary parts of the network. We evaluate our framework on CelebA and ImageNet and analyze its scaling behavior across resolutions and network depths. Our project website ( https://prateksha.github.io/projects/scale-space-diffusion/ ) is available publicly.
Design-o-meter: Towards Evaluating and Refining Graphic Designs
Nov 22, 2024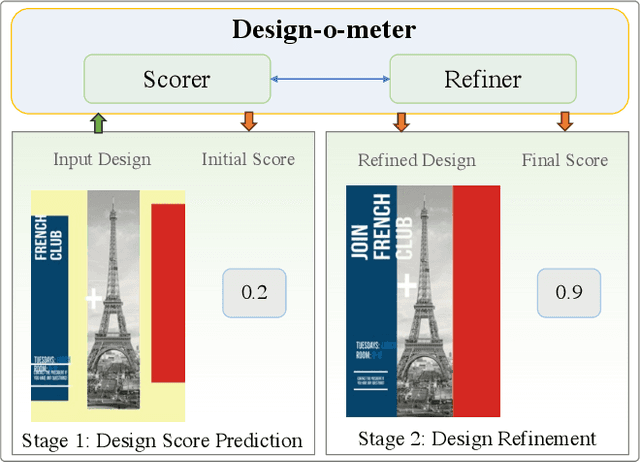
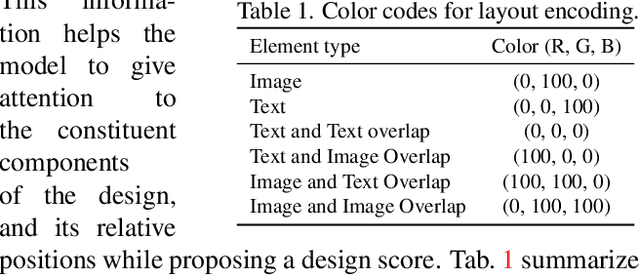
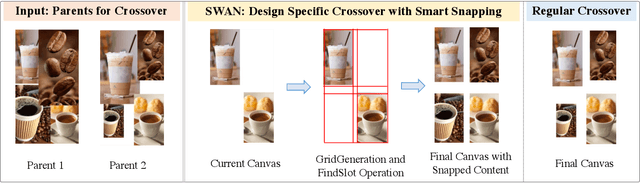
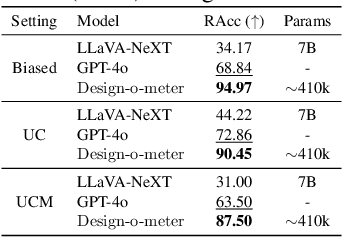
Graphic designs are an effective medium for visual communication. They range from greeting cards to corporate flyers and beyond. Off-late, machine learning techniques are able to generate such designs, which accelerates the rate of content production. An automated way of evaluating their quality becomes critical. Towards this end, we introduce Design-o-meter, a data-driven methodology to quantify the goodness of graphic designs. Further, our approach can suggest modifications to these designs to improve its visual appeal. To the best of our knowledge, Design-o-meter is the first approach that scores and refines designs in a unified framework despite the inherent subjectivity and ambiguity of the setting. Our exhaustive quantitative and qualitative analysis of our approach against baselines adapted for the task (including recent Multimodal LLM-based approaches) brings out the efficacy of our methodology. We hope our work will usher more interest in this important and pragmatic problem setting.
Iterative Multi-granular Image Editing using Diffusion Models
Sep 01, 2023



Recent advances in text-guided image synthesis has dramatically changed how creative professionals generate artistic and aesthetically pleasing visual assets. To fully support such creative endeavors, the process should possess the ability to: 1) iteratively edit the generations and 2) control the spatial reach of desired changes (global, local or anything in between). We formalize this pragmatic problem setting as Iterative Multi-granular Editing. While there has been substantial progress with diffusion-based models for image synthesis and editing, they are all one shot (i.e., no iterative editing capabilities) and do not naturally yield multi-granular control (i.e., covering the full spectrum of local-to-global edits). To overcome these drawbacks, we propose EMILIE: Iterative Multi-granular Image Editor. EMILIE introduces a novel latent iteration strategy, which re-purposes a pre-trained diffusion model to facilitate iterative editing. This is complemented by a gradient control operation for multi-granular control. We introduce a new benchmark dataset to evaluate our newly proposed setting. We conduct exhaustive quantitatively and qualitatively evaluation against recent state-of-the-art approaches adapted to our task, to being out the mettle of EMILIE. We hope our work would attract attention to this newly identified, pragmatic problem setting.
Learning with Multi-modal Gradient Attention for Explainable Composed Image Retrieval
Aug 31, 2023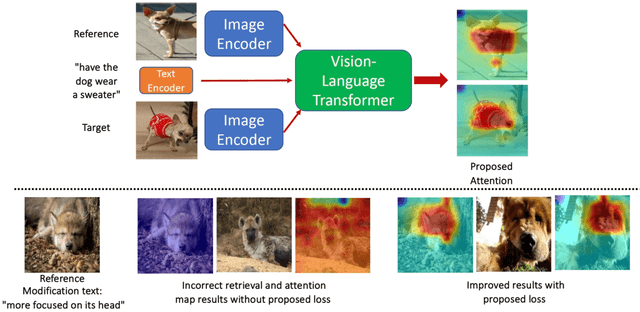

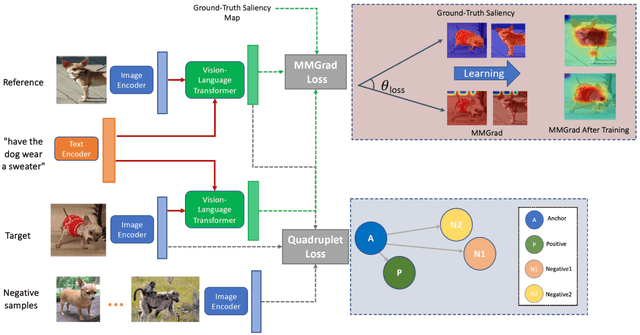
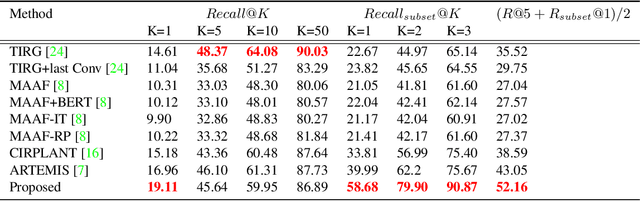
We consider the problem of composed image retrieval that takes an input query consisting of an image and a modification text indicating the desired changes to be made on the image and retrieves images that match these changes. Current state-of-the-art techniques that address this problem use global features for the retrieval, resulting in incorrect localization of the regions of interest to be modified because of the global nature of the features, more so in cases of real-world, in-the-wild images. Since modifier texts usually correspond to specific local changes in an image, it is critical that models learn local features to be able to both localize and retrieve better. To this end, our key novelty is a new gradient-attention-based learning objective that explicitly forces the model to focus on the local regions of interest being modified in each retrieval step. We achieve this by first proposing a new visual image attention computation technique, which we call multi-modal gradient attention (MMGrad) that is explicitly conditioned on the modifier text. We next demonstrate how MMGrad can be incorporated into an end-to-end model training strategy with a new learning objective that explicitly forces these MMGrad attention maps to highlight the correct local regions corresponding to the modifier text. By training retrieval models with this new loss function, we show improved grounding by means of better visual attention maps, leading to better explainability of the models as well as competitive quantitative retrieval performance on standard benchmark datasets.
Contextual Prompt Learning for Vision-Language Understanding
Jul 03, 2023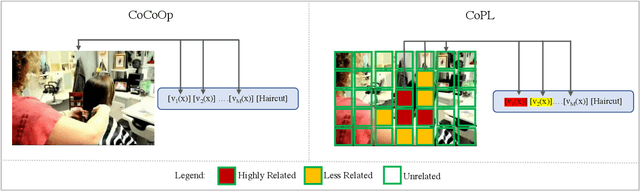
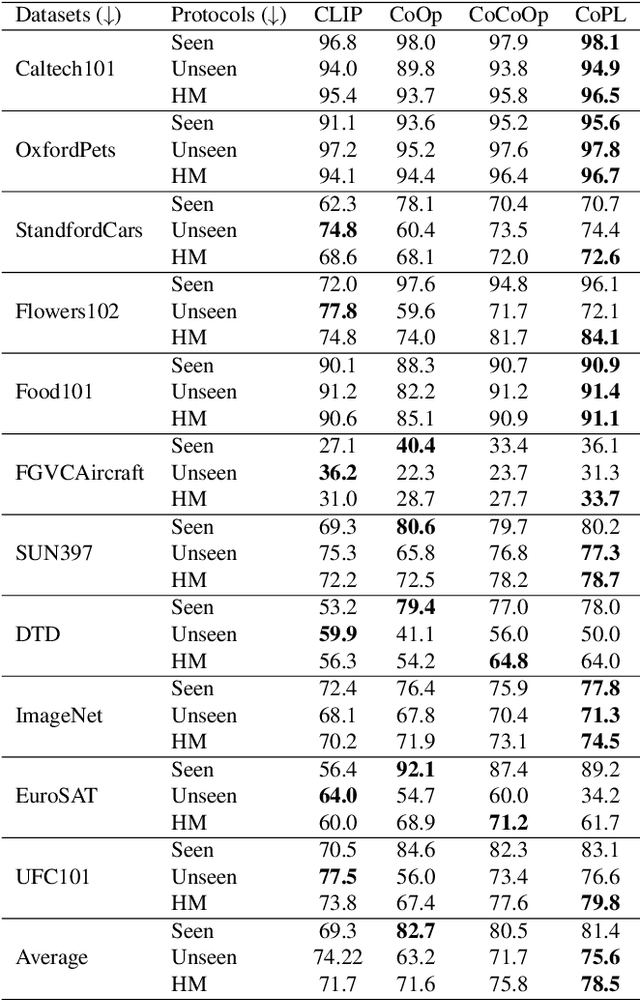
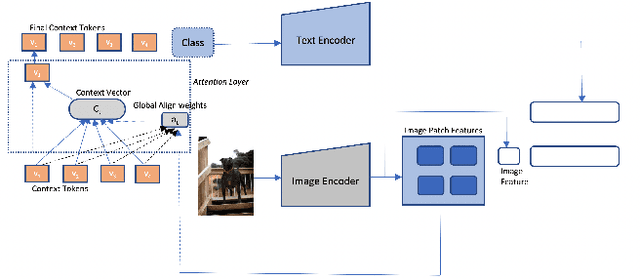

Recent advances in multimodal learning has resulted in powerful vision-language models, whose representations are generalizable across a variety of downstream tasks. Recently, their generalizability has been further extended by incorporating trainable prompts, borrowed from the natural language processing literature. While such prompt learning techniques have shown impressive results, we identify that these prompts are trained based on global image features which limits itself in two aspects: First, by using global features, these prompts could be focusing less on the discriminative foreground image, resulting in poor generalization to various out-of-distribution test cases. Second, existing work weights all prompts equally whereas our intuition is that these prompts are more specific to the type of the image. We address these issues with as part of our proposed Contextual Prompt Learning (CoPL) framework, capable of aligning the prompts to the localized features of the image. Our key innovations over earlier works include using local image features as part of the prompt learning process, and more crucially, learning to weight these prompts based on local features that are appropriate for the task at hand. This gives us dynamic prompts that are both aligned to local image features as well as aware of local contextual relationships. Our extensive set of experiments on a variety of standard and few-shot datasets show that our method produces substantially improved performance when compared to the current state of the art methods. We also demonstrate both few-shot and out-of-distribution performance to establish the utility of learning dynamic prompts that are aligned to local image features.