 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: A Reasoning-Guided Attribution Framework for Explainable Visual Data Analysis
Aug 23, 2025Data visualizations like charts are fundamental tools for quantitative analysis and decision-making across fields, requiring accurate interpretation and mathematical reasoning. The emergence of Multimodal Large Language Models (MLLMs) offers promising capabilities for automated visual data analysis, such as processing charts, answering questions, and generating summaries. However, they provide no visibility into which parts of the visual data informed their conclusions; this black-box nature poses significant challenges to real-world trust and adoption. In this paper, we take the first major step towards evaluating and enhancing the capabilities of MLLMs to attribute their reasoning process by highlighting the specific regions in charts and graphs that justify model answers. To this end, we contribute RADAR, a semi-automatic approach to obtain a benchmark dataset comprising 17,819 diverse samples with charts, questions, reasoning steps, and attribution annotations. We also introduce a method that provides attribution for chart-based mathematical reasoning. Experimental results demonstrate that our reasoning-guided approach improves attribution accuracy by 15% compared to baseline methods, and enhanced attribution capabilities translate to stronger answer generation, achieving an average BERTScore of $\sim$ 0.90, indicating high alignment with ground truth responses. This advancement represents a significant step toward more interpretable and trustworthy chart analysis systems, enabling users to verify and understand model decisions through reasoning and attribution.
FloAt: Flow Warping of Self-Attention for Clothing Animation Generation
Nov 22, 2024
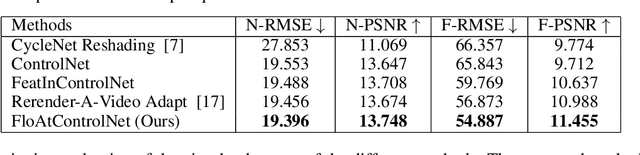
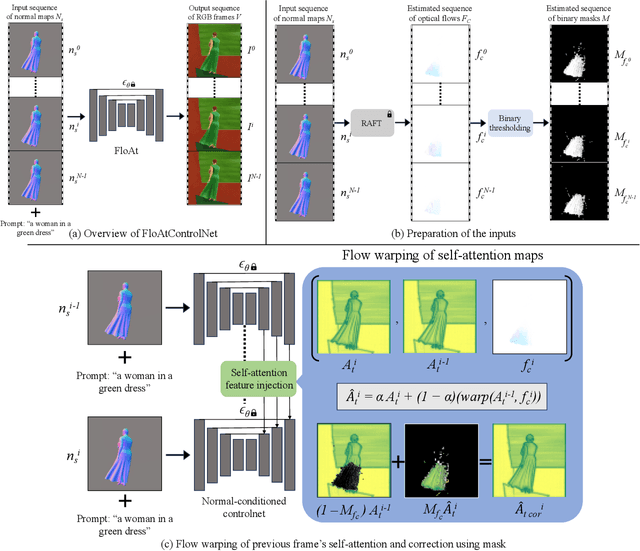
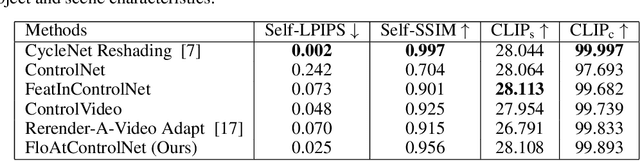
We propose a diffusion model-based approach, FloAtControlNet to generate cinemagraphs composed of animations of human clothing. We focus on human clothing like dresses, skirts and pants. The input to our model is a text prompt depicting the type of clothing and the texture of clothing like leopard, striped, or plain, and a sequence of normal maps that capture the underlying animation that we desire in the output. The backbone of our method is a normal-map conditioned ControlNet which is operated in a training-free regime. The key observation is that the underlying animation is embedded in the flow of the normal maps. We utilize the flow thus obtained to manipulate the self-attention maps of appropriate layers. Specifically, the self-attention maps of a particular layer and frame are recomputed as a linear combination of itself and the self-attention maps of the same layer and the previous frame, warped by the flow on the normal maps of the two frames. We show that manipulating the self-attention maps greatly enhances the quality of the clothing animation, making it look more natural as well as suppressing the background artifacts. Through extensive experiments, we show that the method proposed beats all baselines both qualitatively in terms of visual results and user study. Specifically, our method is able to alleviate the background flickering that exists in other diffusion model-based baselines that we consider. In addition, we show that our method beats all baselines in terms of RMSE and PSNR computed using the input normal map sequences and the normal map sequences obtained from the output RGB frames. Further, we show that well-established evaluation metrics like LPIPS, SSIM, and CLIP scores that are generally for visual quality are not necessarily suitable for capturing the subtle motions in human clothing animations.
Design-o-meter: Towards Evaluating and Refining Graphic Designs
Nov 22, 2024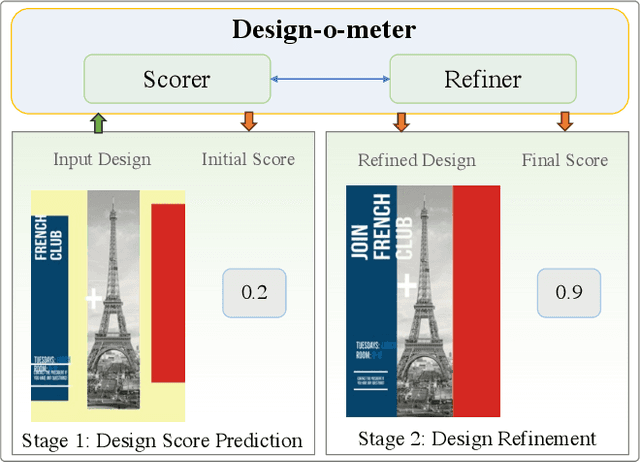
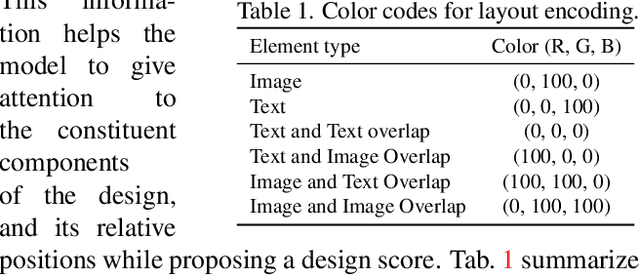
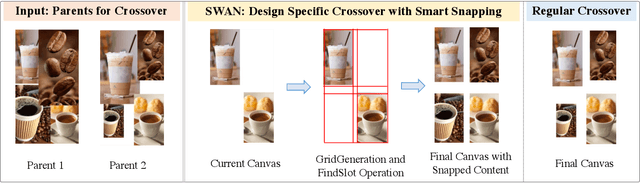
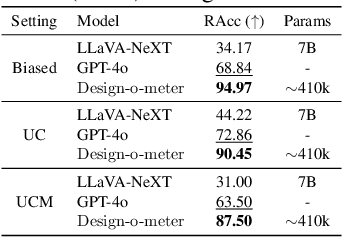
Graphic designs are an effective medium for visual communication. They range from greeting cards to corporate flyers and beyond. Off-late, machine learning techniques are able to generate such designs, which accelerates the rate of content production. An automated way of evaluating their quality becomes critical. Towards this end, we introduce Design-o-meter, a data-driven methodology to quantify the goodness of graphic designs. Further, our approach can suggest modifications to these designs to improve its visual appeal. To the best of our knowledge, Design-o-meter is the first approach that scores and refines designs in a unified framework despite the inherent subjectivity and ambiguity of the setting. Our exhaustive quantitative and qualitative analysis of our approach against baselines adapted for the task (including recent Multimodal LLM-based approaches) brings out the efficacy of our methodology. We hope our work will usher more interest in this important and pragmatic problem setting.
Test-time Conditional Text-to-Image Synthesis Using Diffusion Models
Nov 16, 2024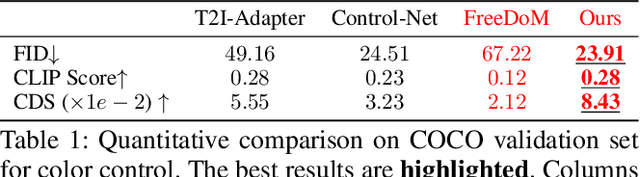
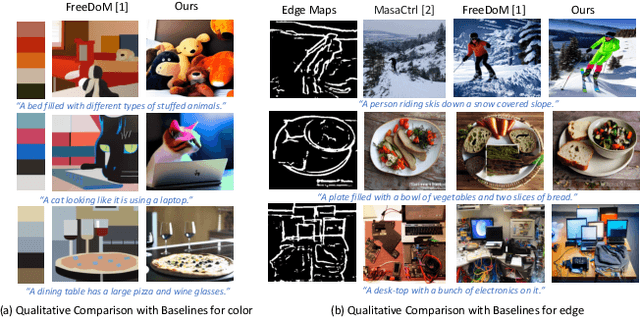
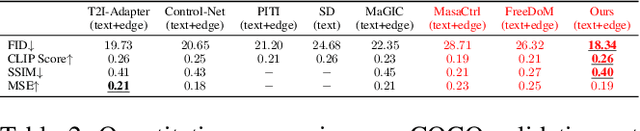
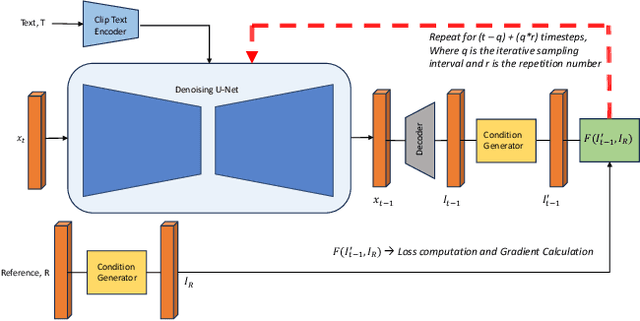
We consider the problem of conditional text-to-image synthesis with diffusion models. Most recent works need to either finetune specific parts of the base diffusion model or introduce new trainable parameters, leading to deployment inflexibility due to the need for training. To address this gap in the current literature, we propose our method called TINTIN: Test-time Conditional Text-to-Image Synthesis using Diffusion Models which is a new training-free test-time only algorithm to condition text-to-image diffusion model outputs on conditioning factors such as color palettes and edge maps. In particular, we propose to interpret noise predictions during denoising as gradients of an energy-based model, leading to a flexible approach to manipulate the noise by matching predictions inferred from them to the ground truth conditioning input. This results in, to the best of our knowledge, the first approach to control model outputs with input color palettes, which we realize using a novel color distribution matching loss. We also show this test-time noise manipulation can be easily extensible to other types of conditioning, e.g., edge maps. We conduct extensive experiments using a variety of text prompts, color palettes, and edge maps and demonstrate significant improvement over the current state-of-the-art, both qualitatively and quantitatively.
Training-free Color-Style Disentanglement for Constrained Text-to-Image Synthesis
Sep 04, 2024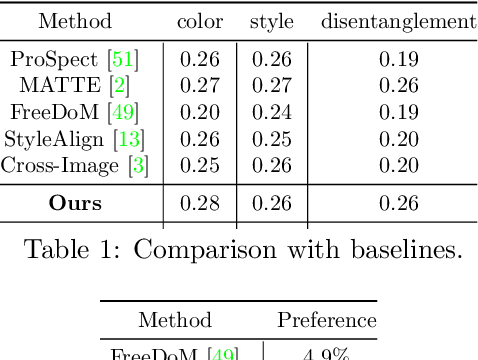


We consider the problem of independently, in a disentangled fashion, controlling the outputs of text-to-image diffusion models with color and style attributes of a user-supplied reference image. We present the first training-free, test-time-only method to disentangle and condition text-to-image models on color and style attributes from reference image. To realize this, we propose two key innovations. Our first contribution is to transform the latent codes at inference time using feature transformations that make the covariance matrix of current generation follow that of the reference image, helping meaningfully transfer color. Next, we observe that there exists a natural disentanglement between color and style in the LAB image space, which we exploit to transform the self-attention feature maps of the image being generated with respect to those of the reference computed from its L channel. Both these operations happen purely at test time and can be done independently or merged. This results in a flexible method where color and style information can come from the same reference image or two different sources, and a new generation can seamlessly fuse them in either scenario.
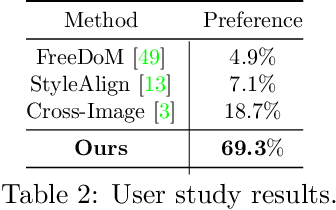
AlignIT: Enhancing Prompt Alignment in Customization of Text-to-Image Models
Jun 27, 2024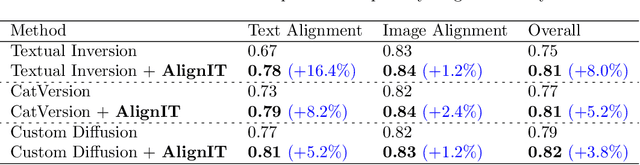



We consider the problem of customizing text-to-image diffusion models with user-supplied reference images. Given new prompts, the existing methods can capture the key concept from the reference images but fail to align the generated image with the prompt. In this work, we seek to address this key issue by proposing new methods that can easily be used in conjunction with existing customization methods that optimize the embeddings/weights at various intermediate stages of the text encoding process. The first contribution of this paper is a dissection of the various stages of the text encoding process leading up to the conditioning vector for text-to-image models. We take a holistic view of existing customization methods and notice that key and value outputs from this process differs substantially from their corresponding baseline (non-customized) models (e.g., baseline stable diffusion). While this difference does not impact the concept being customized, it leads to other parts of the generated image not being aligned with the prompt (see first row in Fig 1). Further, we also observe that these keys and values allow independent control various aspects of the final generation, enabling semantic manipulation of the output. Taken together, the features spanning these keys and values, serve as the basis for our next contribution where we fix the aforementioned issues with existing methods. We propose a new post-processing algorithm, \textbf{AlignIT}, that infuses the keys and values for the concept of interest while ensuring the keys and values for all other tokens in the input prompt are unchanged. Our proposed method can be plugged in directly to existing customization methods, leading to a substantial performance improvement in the alignment of the final result with the input prompt while retaining the customization quality.
Post-Hoc Answer Attribution for Grounded and Trustworthy Long Document Comprehension: Task, Insights, and Challenges
Jun 11, 2024Attributing answer text to its source document for information-seeking questions is crucial for building trustworthy, reliable, and accountable systems. We formulate a new task of post-hoc answer attribution for long document comprehension (LDC). Owing to the lack of long-form abstractive and information-seeking LDC datasets, we refactor existing datasets to assess the strengths and weaknesses of existing retrieval-based and proposed answer decomposition and textual entailment-based optimal selection attribution systems for this task. We throw light on the limitations of existing datasets and the need for datasets to assess the actual performance of systems on this task.
MeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models
Jun 07, 2024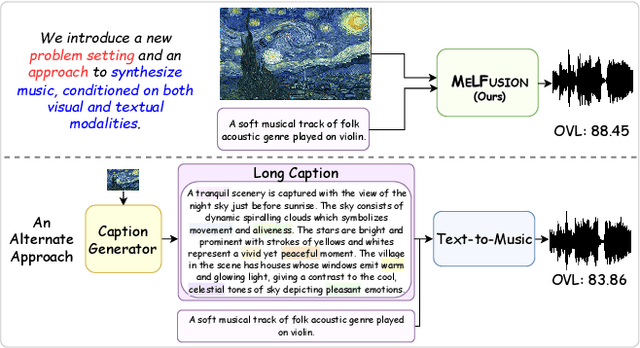
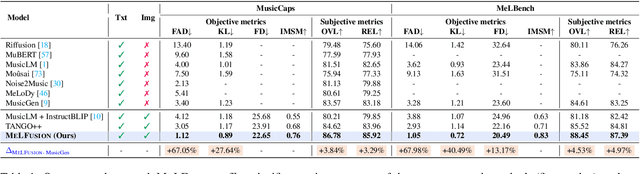
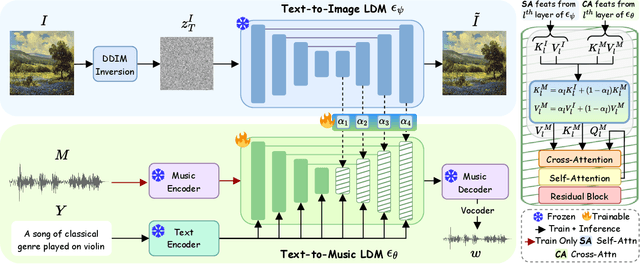
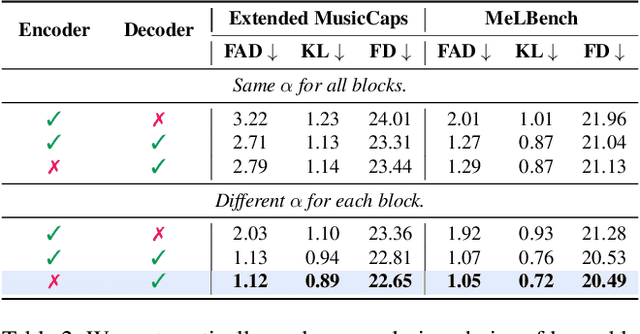
Music is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel "visual synapse", which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area.
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
May 28, 2024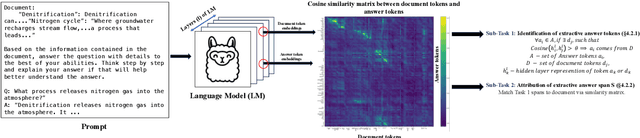
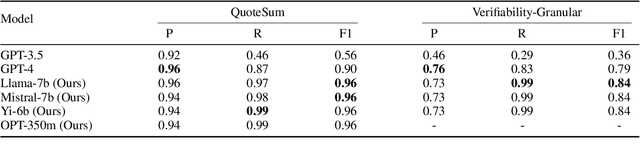

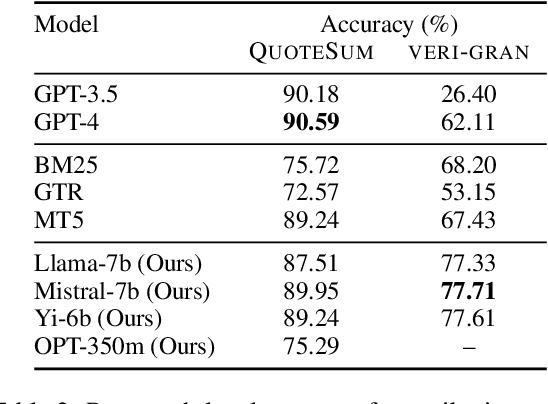
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with "glue text" generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
Social Media Ready Caption Generation for Brands
Jan 03, 2024
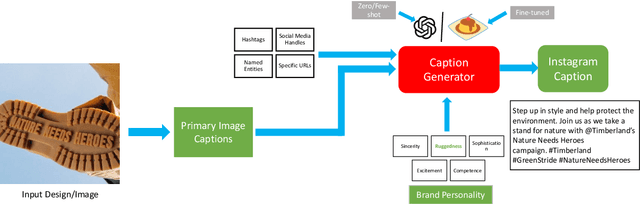
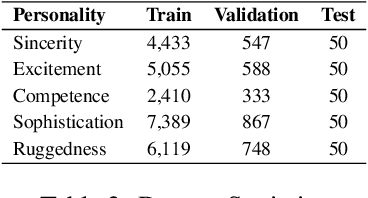
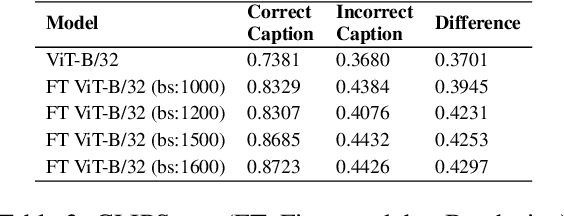
Social media advertisements are key for brand marketing, aiming to attract consumers with captivating captions and pictures or logos. While previous research has focused on generating captions for general images, incorporating brand personalities into social media captioning remains unexplored. Brand personalities are shown to be affecting consumers' behaviours and social interactions and thus are proven to be a key aspect of marketing strategies. Current open-source multimodal LLMs are not directly suited for this task. Hence, we propose a pipeline solution to assist brands in creating engaging social media captions that align with the image and the brand personalities. Our architecture is based on two parts: a the first part contains an image captioning model that takes in an image that the brand wants to post online and gives a plain English caption; b the second part takes in the generated caption along with the target brand personality and outputs a catchy personality-aligned social media caption. Along with brand personality, our system also gives users the flexibility to provide hashtags, Instagram handles, URLs, and named entities they want the caption to contain, making the captions more semantically related to the social media handles. Comparative evaluations against various baselines demonstrate the effectiveness of our approach, both qualitatively and quantitatively.