 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextFocus: Activation Steering for Contextual Faithfulness in Large Language Models
Jan 07, 2026Large Language Models (LLMs) encode vast amounts of parametric knowledge during pre-training. As world knowledge evolves, effective deployment increasingly depends on their ability to faithfully follow externally retrieved context. When such evidence conflicts with the model's internal knowledge, LLMs often default to memorized facts, producing unfaithful outputs. In this work, we introduce ContextFocus, a lightweight activation steering approach that improves context faithfulness in such knowledge-conflict settings while preserving fluency and efficiency. Unlike prior approaches, our solution requires no model finetuning and incurs minimal inference-time overhead, making it highly efficient. We evaluate ContextFocus on the ConFiQA benchmark, comparing it against strong baselines including ContextDPO, COIECD, and prompting-based methods. Furthermore, we show that our method is complementary to prompting strategies and remains effective on larger models. Extensive experiments show that ContextFocus significantly improves contextual-faithfulness. Our results highlight the effectiveness, robustness, and efficiency of ContextFocus in improving contextual-faithfulness of LLM outputs.
PLD+: Accelerating LLM inference by leveraging Language Model Artifacts
Dec 02, 2024To reduce the latency associated with autoretrogressive LLM inference, speculative decoding has emerged as a novel decoding paradigm, where future tokens are drafted and verified in parallel. However, the practical deployment of speculative decoding is hindered by its requirements for additional computational resources and fine-tuning, which limits its out-of-the-box usability. To address these challenges, we present PLD+, a suite of novel algorithms developed to accelerate the inference process of LLMs, particularly for input-guided tasks. These tasks, which include code editing, text editing, summarization, etc., often feature outputs with substantial overlap with their inputs-an attribute PLD+ is designed to exploit. PLD+ also leverages the artifacts (attention and hidden states) generated during inference to accelerate inference speed. We test our approach on five input-guided tasks and through extensive experiments we find that PLD+ outperforms all tuning-free approaches. In the greedy setting, it even outperforms the state-of-the-art tuning-dependent approach EAGLE on four of the tasks. (by a margin of upto 2.31 in terms of avg. speedup). Our approach is tuning free, does not require any additional compute and can easily be used for accelerating inference of any LLM.
Beyond Logit Lens: Contextual Embeddings for Robust Hallucination Detection & Grounding in VLMs
Nov 28, 2024The rapid development of Large Multimodal Models (LMMs) has significantly advanced multimodal understanding by harnessing the language abilities of Large Language Models (LLMs) and integrating modality-specific encoders. However, LMMs are plagued by hallucinations that limit their reliability and adoption. While traditional methods to detect and mitigate these hallucinations often involve costly training or rely heavily on external models, recent approaches utilizing internal model features present a promising alternative. In this paper, we critically assess the limitations of the state-of-the-art training-free technique, the logit lens, in handling generalized visual hallucinations. We introduce a refined method that leverages contextual token embeddings from middle layers of LMMs. This approach significantly improves hallucination detection and grounding across diverse categories, including actions and OCR, while also excelling in tasks requiring contextual understanding, such as spatial relations and attribute comparison. Our novel grounding technique yields highly precise bounding boxes, facilitating a transition from Zero-Shot Object Segmentation to Grounded Visual Question Answering. Our contributions pave the way for more reliable and interpretable multimodal models.
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
May 28, 2024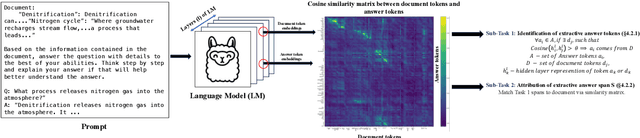
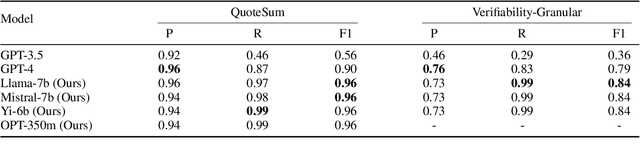

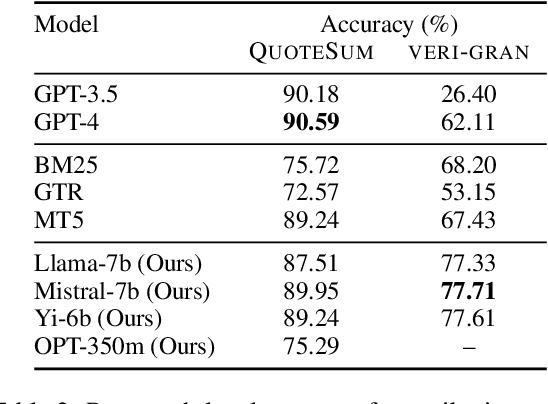
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with "glue text" generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.