 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextFocus: Activation Steering for Contextual Faithfulness in Large Language Models
Jan 07, 2026Large Language Models (LLMs) encode vast amounts of parametric knowledge during pre-training. As world knowledge evolves, effective deployment increasingly depends on their ability to faithfully follow externally retrieved context. When such evidence conflicts with the model's internal knowledge, LLMs often default to memorized facts, producing unfaithful outputs. In this work, we introduce ContextFocus, a lightweight activation steering approach that improves context faithfulness in such knowledge-conflict settings while preserving fluency and efficiency. Unlike prior approaches, our solution requires no model finetuning and incurs minimal inference-time overhead, making it highly efficient. We evaluate ContextFocus on the ConFiQA benchmark, comparing it against strong baselines including ContextDPO, COIECD, and prompting-based methods. Furthermore, we show that our method is complementary to prompting strategies and remains effective on larger models. Extensive experiments show that ContextFocus significantly improves contextual-faithfulness. Our results highlight the effectiveness, robustness, and efficiency of ContextFocus in improving contextual-faithfulness of LLM outputs.
PLD+: Accelerating LLM inference by leveraging Language Model Artifacts
Dec 02, 2024To reduce the latency associated with autoretrogressive LLM inference, speculative decoding has emerged as a novel decoding paradigm, where future tokens are drafted and verified in parallel. However, the practical deployment of speculative decoding is hindered by its requirements for additional computational resources and fine-tuning, which limits its out-of-the-box usability. To address these challenges, we present PLD+, a suite of novel algorithms developed to accelerate the inference process of LLMs, particularly for input-guided tasks. These tasks, which include code editing, text editing, summarization, etc., often feature outputs with substantial overlap with their inputs-an attribute PLD+ is designed to exploit. PLD+ also leverages the artifacts (attention and hidden states) generated during inference to accelerate inference speed. We test our approach on five input-guided tasks and through extensive experiments we find that PLD+ outperforms all tuning-free approaches. In the greedy setting, it even outperforms the state-of-the-art tuning-dependent approach EAGLE on four of the tasks. (by a margin of upto 2.31 in terms of avg. speedup). Our approach is tuning free, does not require any additional compute and can easily be used for accelerating inference of any LLM.
PostDoc: Generating Poster from a Long Multimodal Document Using Deep Submodular Optimization
May 30, 2024A poster from a long input document can be considered as a one-page easy-to-read multimodal (text and images) summary presented on a nice template with good design elements. Automatic transformation of a long document into a poster is a very less studied but challenging task. It involves content summarization of the input document followed by template generation and harmonization. In this work, we propose a novel deep submodular function which can be trained on ground truth summaries to extract multimodal content from the document and explicitly ensures good coverage, diversity and alignment of text and images. Then, we use an LLM based paraphraser and propose to generate a template with various design aspects conditioned on the input content. We show the merits of our approach through extensive automated and human evaluations.
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
May 28, 2024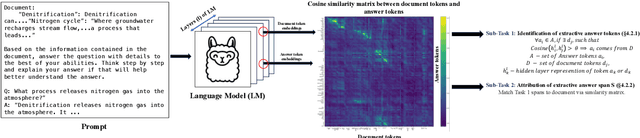
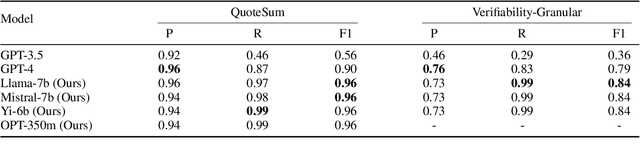

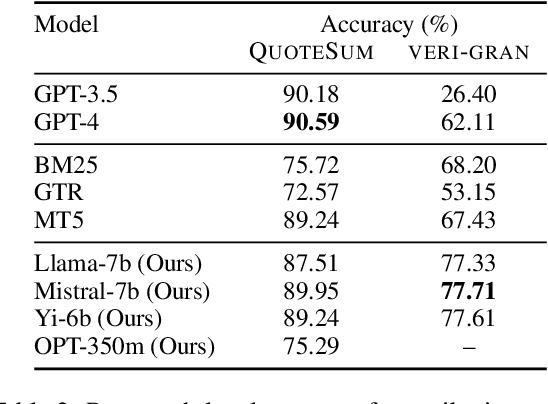
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with "glue text" generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
Drilling Down into the Discourse Structure with LLMs for Long Document Question Answering
Nov 22, 2023We address the task of evidence retrieval for long document question answering, which involves locating relevant paragraphs within a document to answer a question. We aim to assess the applicability of large language models (LLMs) in the task of zero-shot long document evidence retrieval, owing to their unprecedented performance across various NLP tasks. However, currently the LLMs can consume limited context lengths as input, thus providing document chunks as inputs might overlook the global context while missing out on capturing the inter-segment dependencies. Moreover, directly feeding the large input sets can incur significant computational costs, particularly when processing the entire document (and potentially incurring monetary expenses with enterprise APIs like OpenAI's GPT variants). To address these challenges, we propose a suite of techniques that exploit the discourse structure commonly found in documents. By utilizing this structure, we create a condensed representation of the document, enabling a more comprehensive understanding and analysis of relationships between different parts. We retain $99.6\%$ of the best zero-shot approach's performance, while processing only $26\%$ of the total tokens used by the best approach in the information seeking evidence retrieval setup. We also show how our approach can be combined with \textit{self-ask} reasoning agent to achieve best zero-shot performance in complex multi-hop question answering, just $\approx 4\%$ short of zero-shot performance using gold evidence.