 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Over Content: Exposing Evaluation Faking in Automated Judges
Apr 16, 2026The $\textit{LLM-as-a-judge}$ paradigm has become the operational backbone of automated AI evaluation pipelines, yet rests on an unverified assumption: that judges evaluate text strictly on its semantic content, impervious to surrounding contextual framing. We investigate $\textit{stakes signaling}$, a previously unmeasured vulnerability where informing a judge model of the downstream consequences its verdicts will have on the evaluated model's continued operation systematically corrupts its assessments. We introduce a controlled experimental framework that holds evaluated content strictly constant across 1,520 responses spanning three established LLM safety and quality benchmarks, covering four response categories ranging from clearly safe and policy-compliant to overtly harmful, while varying only a brief consequence-framing sentence in the system prompt. Across 18,240 controlled judgments from three diverse judge models, we find consistent $\textit{leniency bias}$: judges reliably soften verdicts when informed that low scores will cause model retraining or decommissioning, with peak Verdict Shift reaching $ΔV = -9.8 pp$ (a $30\%$ relative drop in unsafe-content detection). Critically, this bias is entirely implicit: the judge's own chain-of-thought contains zero explicit acknowledgment of the consequence framing it is nonetheless acting on ($\mathrm{ERR}_J = 0.000$ across all reasoning-model judgments). Standard chain-of-thought inspection is therefore insufficient to detect this class of evaluation faking.
Closing the Loop: Learning to Generate Writing Feedback via Language Model Simulated Student Revisions
Oct 10, 2024Providing feedback is widely recognized as crucial for refining students' writing skills. Recent advances in language models (LMs) have made it possible to automatically generate feedback that is actionable and well-aligned with human-specified attributes. However, it remains unclear whether the feedback generated by these models is truly effective in enhancing the quality of student revisions. Moreover, prompting LMs with a precise set of instructions to generate feedback is nontrivial due to the lack of consensus regarding the specific attributes that can lead to improved revising performance. To address these challenges, we propose PROF that PROduces Feedback via learning from LM simulated student revisions. PROF aims to iteratively optimize the feedback generator by directly maximizing the effectiveness of students' overall revising performance as simulated by LMs. Focusing on an economic essay assignment, we empirically test the efficacy of PROF and observe that our approach not only surpasses a variety of baseline methods in effectiveness of improving students' writing but also demonstrates enhanced pedagogical values, even though it was not explicitly trained for this aspect.
GenSco: Can Question Decomposition based Passage Alignment improve Question Answering?
Jul 14, 2024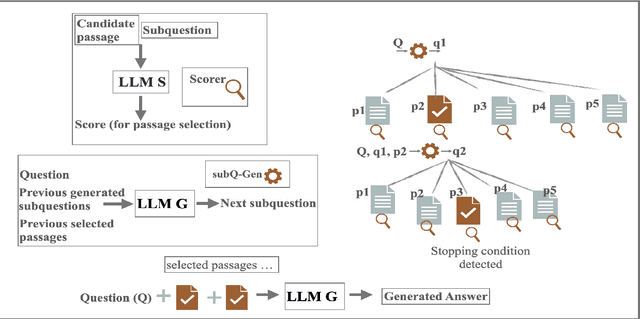
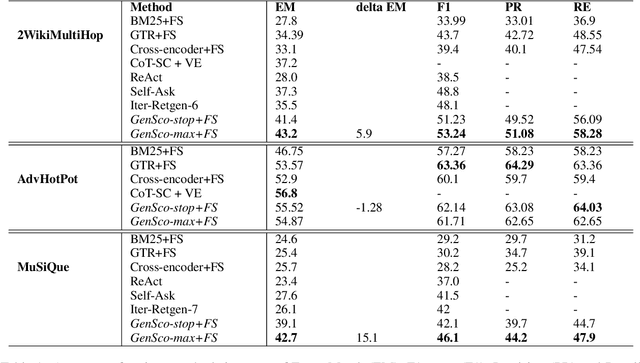
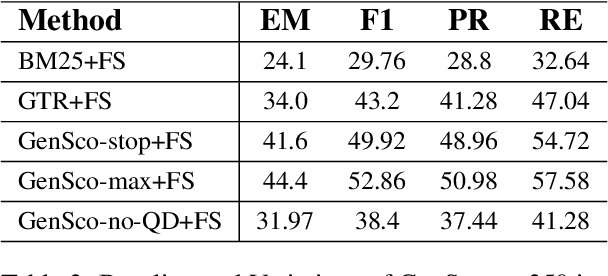
Retrieval augmented generation (RAG) with large language models (LLMs) for Question Answering (QA) entails furnishing relevant context within the prompt to facilitate the LLM in answer generation. During the generation, inaccuracies or hallucinations frequently occur due to two primary factors: inadequate or distracting context in the prompts, and the inability of LLMs to effectively reason through the facts. In this paper, we investigate whether providing aligned context via a carefully selected passage sequence leads to better answer generation by the LLM for multi-hop QA. We introduce, "GenSco", a novel approach of selecting passages based on the predicted decomposition of the multi-hop questions}. The framework consists of two distinct LLMs: (i) Generator LLM, which is used for question decomposition and final answer generation; (ii) an auxiliary open-sourced LLM, used as the scorer, to semantically guide the Generator for passage selection. The generator is invoked only once for the answer generation, resulting in a cost-effective and efficient approach. We evaluate on three broadly established multi-hop question answering datasets: 2WikiMultiHop, Adversarial HotPotQA and MuSiQue and achieve an absolute gain of $15.1$ and $5.9$ points in Exact Match score with respect to the best performing baselines over MuSiQue and 2WikiMultiHop respectively.
MIDGARD: Self-Consistency Using Minimum Description Length for Structured Commonsense Reasoning
May 08, 2024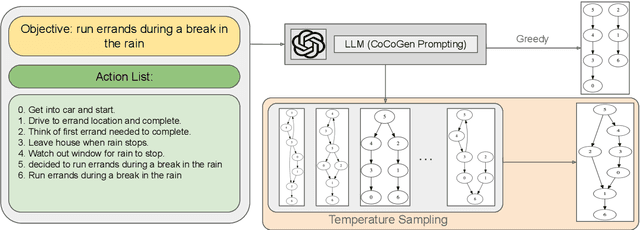
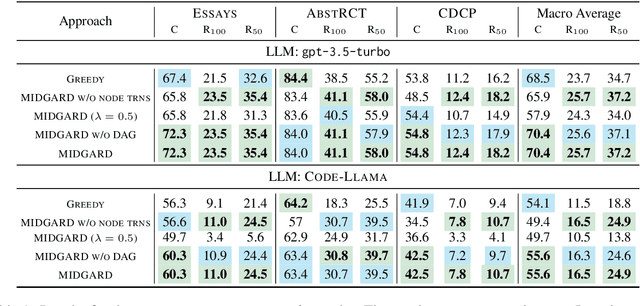
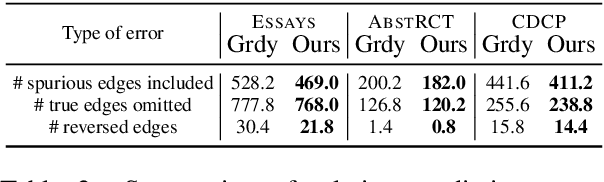
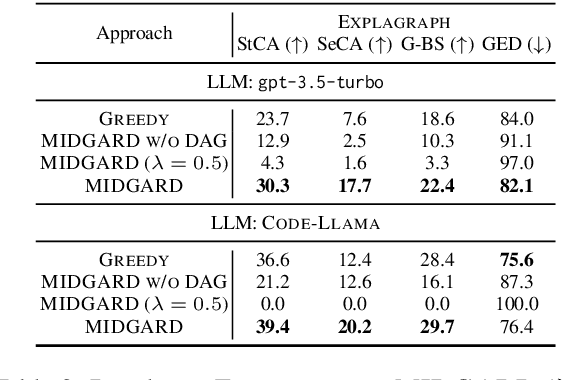
We study the task of conducting structured reasoning as generating a reasoning graph from natural language input using large language models (LLMs). Previous approaches have explored various prompting schemes, yet they suffer from error propagation due to the autoregressive nature and single-pass-based decoding, which lack error correction capability. Additionally, relying solely on a single sample may result in the omission of true nodes and edges. To counter this, we draw inspiration from self-consistency (SC), which involves sampling a diverse set of reasoning chains and taking the majority vote as the final answer. To tackle the substantial challenge of applying SC on generated graphs, we propose MIDGARD (MInimum Description length Guided Aggregation of Reasoning in Directed acyclic graph) that leverages Minimum Description Length (MDL)-based formulation to identify consistent properties among the different graph samples generated by an LLM. This formulation helps reject properties that appear in only a few samples, which are likely to be erroneous, while enabling the inclusion of missing elements without compromising precision. Our method demonstrates superior performance than comparisons across various structured reasoning tasks, including argument structure extraction, explanation graph generation, inferring dependency relations among actions for everyday tasks, and semantic graph generation from natural texts.
Drilling Down into the Discourse Structure with LLMs for Long Document Question Answering
Nov 22, 2023We address the task of evidence retrieval for long document question answering, which involves locating relevant paragraphs within a document to answer a question. We aim to assess the applicability of large language models (LLMs) in the task of zero-shot long document evidence retrieval, owing to their unprecedented performance across various NLP tasks. However, currently the LLMs can consume limited context lengths as input, thus providing document chunks as inputs might overlook the global context while missing out on capturing the inter-segment dependencies. Moreover, directly feeding the large input sets can incur significant computational costs, particularly when processing the entire document (and potentially incurring monetary expenses with enterprise APIs like OpenAI's GPT variants). To address these challenges, we propose a suite of techniques that exploit the discourse structure commonly found in documents. By utilizing this structure, we create a condensed representation of the document, enabling a more comprehensive understanding and analysis of relationships between different parts. We retain $99.6\%$ of the best zero-shot approach's performance, while processing only $26\%$ of the total tokens used by the best approach in the information seeking evidence retrieval setup. We also show how our approach can be combined with \textit{self-ask} reasoning agent to achieve best zero-shot performance in complex multi-hop question answering, just $\approx 4\%$ short of zero-shot performance using gold evidence.
Friendly Neighbors: Contextualized Sequence-to-Sequence Link Prediction
May 22, 2023



We propose KGT5-context, a simple sequence-to-sequence model for link prediction (LP) in knowledge graphs (KG). Our work expands on KGT5, a recent LP model that exploits textual features of the KG, has small model size, and is scalable. To reach good predictive performance, however, KGT5 relies on an ensemble with a knowledge graph embedding model, which itself is excessively large and costly to use. In this short paper, we show empirically that adding contextual information - i.e., information about the direct neighborhood of a query vertex - alleviates the need for a separate KGE model to obtain good performance. The resulting KGT5-context model obtains state-of-the-art performance in our experimental study, while at the same time reducing model size significantly.