 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multilingual Embeddings via Multi-Way Parallel Text Alignment
Feb 25, 2026Multilingual pretraining typically lacks explicit alignment signals, leading to suboptimal cross-lingual alignment in the representation space. In this work, we show that training standard pretrained models for cross-lingual alignment with a multi-way parallel corpus in a diverse pool of languages can substantially improve multilingual and cross-lingual representations for NLU tasks. We construct a multi-way parallel dataset using translations of English text from an off-the-shelf NMT model for a pool of six target languages and achieve strong cross-lingual alignment through contrastive learning. This leads to substantial performance gains across both seen and unseen languages for multiple tasks from the MTEB benchmark evaluated for XLM-Roberta and multilingual BERT base models. Using a multi-way parallel corpus for contrastive training yields substantial gains on bitext mining (21.3%), semantic similarity (5.3%), and classification (28.4%) compared to English-centric (En-X) bilingually parallel data, where X is sampled from a pool of multiple target languages. Furthermore, finetuning mE5 model on a small dataset with multi-way parallelism significantly improves bitext mining compared to one without, underscoring the importance of multi-way cross-lingual supervision even for models already pretrained for high-quality sentence embeddings.
Boosting Zero-Shot Crosslingual Performance using LLM-Based Augmentations with Effective Data Selection
Jul 15, 2024



Large language models (LLMs) are very proficient text generators. We leverage this capability of LLMs to generate task-specific data via zero-shot prompting and promote cross-lingual transfer for low-resource target languages. Given task-specific data in a source language and a teacher model trained on this data, we propose using this teacher to label LLM generations and employ a set of simple data selection strategies that use the teacher's label probabilities. Our data selection strategies help us identify a representative subset of diverse generations that help boost zero-shot accuracies while being efficient, in comparison to using all the LLM generations (without any subset selection). We also highlight other important design choices that affect cross-lingual performance such as the use of translations of source data and what labels are best to use for the LLM generations. We observe significant performance gains across sentiment analysis and natural language inference tasks (of up to a maximum of 7.13 absolute points and 1.5 absolute points on average) across a number of target languages (Hindi, Marathi, Urdu, Swahili) and domains.
GenSco: Can Question Decomposition based Passage Alignment improve Question Answering?
Jul 14, 2024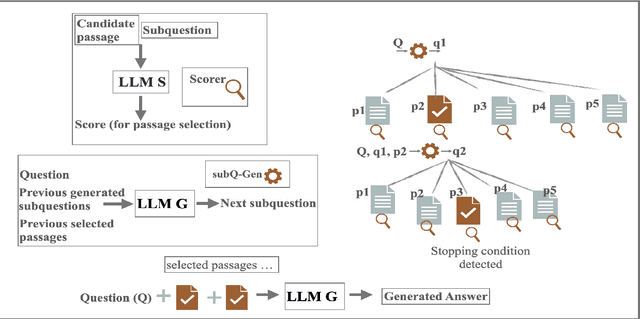
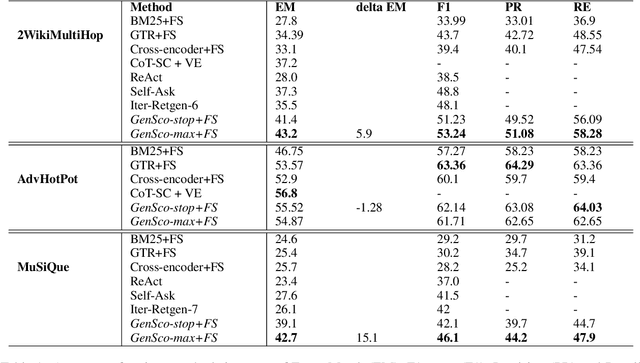
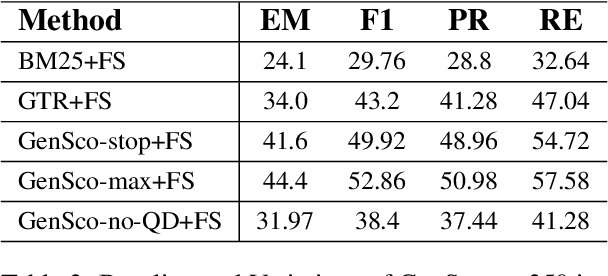
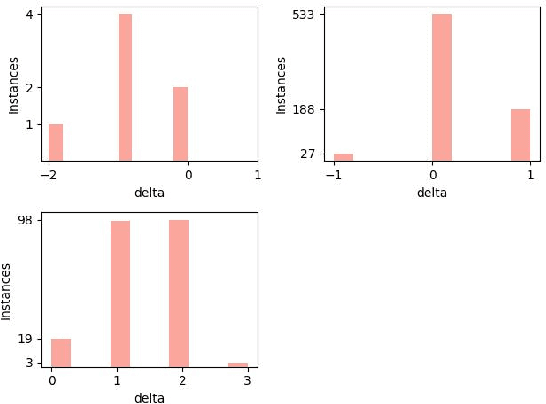
Retrieval augmented generation (RAG) with large language models (LLMs) for Question Answering (QA) entails furnishing relevant context within the prompt to facilitate the LLM in answer generation. During the generation, inaccuracies or hallucinations frequently occur due to two primary factors: inadequate or distracting context in the prompts, and the inability of LLMs to effectively reason through the facts. In this paper, we investigate whether providing aligned context via a carefully selected passage sequence leads to better answer generation by the LLM for multi-hop QA. We introduce, "GenSco", a novel approach of selecting passages based on the predicted decomposition of the multi-hop questions}. The framework consists of two distinct LLMs: (i) Generator LLM, which is used for question decomposition and final answer generation; (ii) an auxiliary open-sourced LLM, used as the scorer, to semantically guide the Generator for passage selection. The generator is invoked only once for the answer generation, resulting in a cost-effective and efficient approach. We evaluate on three broadly established multi-hop question answering datasets: 2WikiMultiHop, Adversarial HotPotQA and MuSiQue and achieve an absolute gain of $15.1$ and $5.9$ points in Exact Match score with respect to the best performing baselines over MuSiQue and 2WikiMultiHop respectively.
Translation Errors Significantly Impact Low-Resource Languages in Cross-Lingual Learning
Feb 03, 2024

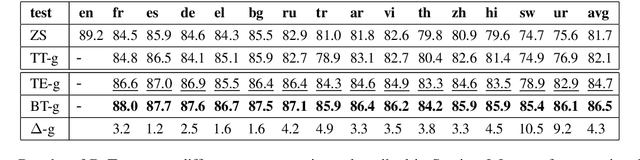

Popular benchmarks (e.g., XNLI) used to evaluate cross-lingual language understanding consist of parallel versions of English evaluation sets in multiple target languages created with the help of professional translators. When creating such parallel data, it is critical to ensure high-quality translations for all target languages for an accurate characterization of cross-lingual transfer. In this work, we find that translation inconsistencies do exist and interestingly they disproportionally impact low-resource languages in XNLI. To identify such inconsistencies, we propose measuring the gap in performance between zero-shot evaluations on the human-translated and machine-translated target text across multiple target languages; relatively large gaps are indicative of translation errors. We also corroborate that translation errors exist for two target languages, namely Hindi and Urdu, by doing a manual reannotation of human-translated test instances in these two languages and finding poor agreement with the original English labels these instances were supposed to inherit.