 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation Errors Significantly Impact Low-Resource Languages in Cross-Lingual Learning
Paper and Code


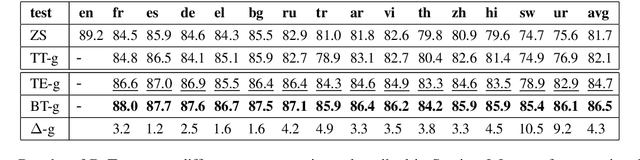

Popular benchmarks (e.g., XNLI) used to evaluate cross-lingual language understanding consist of parallel versions of English evaluation sets in multiple target languages created with the help of professional translators. When creating such parallel data, it is critical to ensure high-quality translations for all target languages for an accurate characterization of cross-lingual transfer. In this work, we find that translation inconsistencies do exist and interestingly they disproportionally impact low-resource languages in XNLI. To identify such inconsistencies, we propose measuring the gap in performance between zero-shot evaluations on the human-translated and machine-translated target text across multiple target languages; relatively large gaps are indicative of translation errors. We also corroborate that translation errors exist for two target languages, namely Hindi and Urdu, by doing a manual reannotation of human-translated test instances in these two languages and finding poor agreement with the original English labels these instances were supposed to inherit.