 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructFormer: Document Structure-based Masked Attention and its Impact on Language Model Pre-Training
Nov 25, 2024
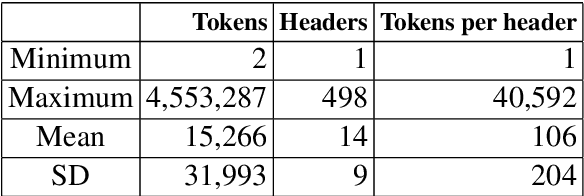

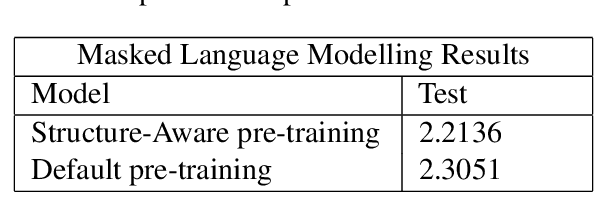
Most state-of-the-art techniques for Language Models (LMs) today rely on transformer-based architectures and their ubiquitous attention mechanism. However, the exponential growth in computational requirements with longer input sequences confines Transformers to handling short passages. Recent efforts have aimed to address this limitation by introducing selective attention mechanisms, notably local and global attention. While sparse attention mechanisms, akin to full attention in being Turing-complete, have been theoretically established, their practical impact on pre-training remains unexplored. This study focuses on empirically assessing the influence of global attention on BERT pre-training. The primary steps involve creating an extensive corpus of structure-aware text through arXiv data, alongside a text-only counterpart. We carry out pre-training on these two datasets, investigate shifts in attention patterns, and assess their implications for downstream tasks. Our analysis underscores the significance of incorporating document structure into LM models, demonstrating their capacity to excel in more abstract tasks, such as document understanding.
GenSco: Can Question Decomposition based Passage Alignment improve Question Answering?
Jul 14, 2024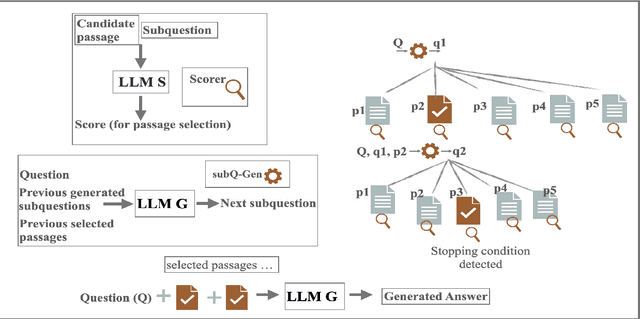
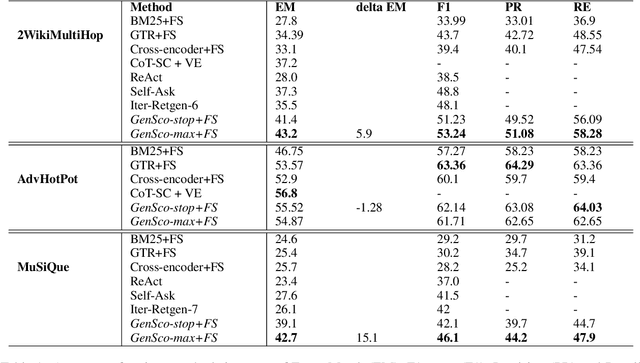
Retrieval augmented generation (RAG) with large language models (LLMs) for Question Answering (QA) entails furnishing relevant context within the prompt to facilitate the LLM in answer generation. During the generation, inaccuracies or hallucinations frequently occur due to two primary factors: inadequate or distracting context in the prompts, and the inability of LLMs to effectively reason through the facts. In this paper, we investigate whether providing aligned context via a carefully selected passage sequence leads to better answer generation by the LLM for multi-hop QA. We introduce, "GenSco", a novel approach of selecting passages based on the predicted decomposition of the multi-hop questions}. The framework consists of two distinct LLMs: (i) Generator LLM, which is used for question decomposition and final answer generation; (ii) an auxiliary open-sourced LLM, used as the scorer, to semantically guide the Generator for passage selection. The generator is invoked only once for the answer generation, resulting in a cost-effective and efficient approach. We evaluate on three broadly established multi-hop question answering datasets: 2WikiMultiHop, Adversarial HotPotQA and MuSiQue and achieve an absolute gain of $15.1$ and $5.9$ points in Exact Match score with respect to the best performing baselines over MuSiQue and 2WikiMultiHop respectively.
ReAct: A Review Comment Dataset for Actionability (and more)
Oct 02, 2022Review comments play an important role in the evolution of documents. For a large document, the number of review comments may become large, making it difficult for the authors to quickly grasp what the comments are about. It is important to identify the nature of the comments to identify which comments require some action on the part of document authors, along with identifying the types of these comments. In this paper, we introduce an annotated review comment dataset ReAct. The review comments are sourced from OpenReview site. We crowd-source annotations for these reviews for actionability and type of comments. We analyze the properties of the dataset and validate the quality of annotations. We release the dataset (https://github.com/gtmdotme/ReAct) to the research community as a major contribution. We also benchmark our data with standard baselines for classification tasks and analyze their performance.