 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRINT: Script-agnostic Structure Recognition in Tables
Mar 15, 2025Table Structure Recognition (TSR) is vital for various downstream tasks like information retrieval, table reconstruction, and document understanding. While most state-of-the-art (SOTA) research predominantly focuses on TSR in English documents, the need for similar capabilities in other languages is evident, considering the global diversity of data. Moreover, creating substantial labeled data in non-English languages and training these SOTA models from scratch is costly and time-consuming. We propose TSR as a language-agnostic cell arrangement prediction and introduce SPRINT, Script-agnostic Structure Recognition in Tables. SPRINT uses recently introduced Optimized Table Structure Language (OTSL) sequences to predict table structures. We show that when coupled with a pre-trained table grid estimator, SPRINT can improve the overall tree edit distance-based similarity structure scores of tables even for non-English documents. We experimentally evaluate our performance across benchmark TSR datasets including PubTabNet, FinTabNet, and PubTables-1M. Our findings reveal that SPRINT not only matches SOTA models in performance on standard datasets but also demonstrates lower latency. Additionally, SPRINT excels in accurately identifying table structures in non-English documents, surpassing current leading models by showing an absolute average increase of 11.12%. We also present an algorithm for converting valid OTSL predictions into a widely used HTML-based table representation. To encourage further research, we release our code and Multilingual Scanned and Scene Table Structure Recognition Dataset, MUSTARD labeled with OTSL sequences for 1428 tables in thirteen languages encompassing several scripts at https://github.com/IITB-LEAP-OCR/SPRINT
PLATTER: A Page-Level Handwritten Text Recognition System for Indic Scripts
Feb 10, 2025In recent years, the field of Handwritten Text Recognition (HTR) has seen the emergence of various new models, each claiming to perform competitively better than the other in specific scenarios. However, making a fair comparison of these models is challenging due to inconsistent choices and diversity in test sets. Furthermore, recent advancements in HTR often fail to account for the diverse languages, especially Indic languages, likely due to the scarcity of relevant labeled datasets. Moreover, much of the previous work has focused primarily on character-level or word-level recognition, overlooking the crucial stage of Handwritten Text Detection (HTD) necessary for building a page-level end-to-end handwritten OCR pipeline. Through our paper, we address these gaps by making three pivotal contributions. Firstly, we present an end-to-end framework for Page-Level hAndwriTTen TExt Recognition (PLATTER) by treating it as a two-stage problem involving word-level HTD followed by HTR. This approach enables us to identify, assess, and address challenges in each stage independently. Secondly, we demonstrate the usage of PLATTER to measure the performance of our language-agnostic HTD model and present a consistent comparison of six trained HTR models on ten diverse Indic languages thereby encouraging consistent comparisons. Finally, we also release a Corpus of Handwritten Indic Scripts (CHIPS), a meticulously curated, page-level Indic handwritten OCR dataset labeled for both detection and recognition purposes. Additionally, we release our code and trained models, to encourage further contributions in this direction.
StructFormer: Document Structure-based Masked Attention and its Impact on Language Model Pre-Training
Nov 25, 2024
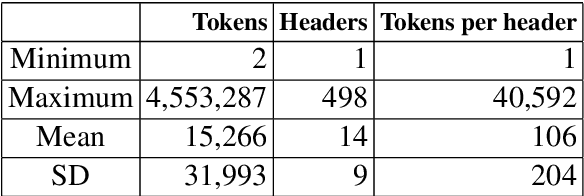

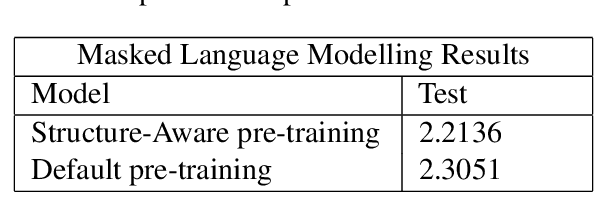
Most state-of-the-art techniques for Language Models (LMs) today rely on transformer-based architectures and their ubiquitous attention mechanism. However, the exponential growth in computational requirements with longer input sequences confines Transformers to handling short passages. Recent efforts have aimed to address this limitation by introducing selective attention mechanisms, notably local and global attention. While sparse attention mechanisms, akin to full attention in being Turing-complete, have been theoretically established, their practical impact on pre-training remains unexplored. This study focuses on empirically assessing the influence of global attention on BERT pre-training. The primary steps involve creating an extensive corpus of structure-aware text through arXiv data, alongside a text-only counterpart. We carry out pre-training on these two datasets, investigate shifts in attention patterns, and assess their implications for downstream tasks. Our analysis underscores the significance of incorporating document structure into LM models, demonstrating their capacity to excel in more abstract tasks, such as document understanding.
TEXTRON: Weakly Supervised Multilingual Text Detection through Data Programming
Feb 15, 2024Several recent deep learning (DL) based techniques perform considerably well on image-based multilingual text detection. However, their performance relies heavily on the availability and quality of training data. There are numerous types of page-level document images consisting of information in several modalities, languages, fonts, and layouts. This makes text detection a challenging problem in the field of computer vision (CV), especially for low-resource or handwritten languages. Furthermore, there is a scarcity of word-level labeled data for text detection, especially for multilingual settings and Indian scripts that incorporate both printed and handwritten text. Conventionally, Indian script text detection requires training a DL model on plenty of labeled data, but to the best of our knowledge, no relevant datasets are available. Manual annotation of such data requires a lot of time, effort, and expertise. In order to solve this problem, we propose TEXTRON, a Data Programming-based approach, where users can plug various text detection methods into a weak supervision-based learning framework. One can view this approach to multilingual text detection as an ensemble of different CV-based techniques and DL approaches. TEXTRON can leverage the predictions of DL models pre-trained on a significant amount of language data in conjunction with CV-based methods to improve text detection in other languages. We demonstrate that TEXTRON can improve the detection performance for documents written in Indian languages, despite the absence of corresponding labeled data. Further, through extensive experimentation, we show improvement brought about by our approach over the current State-of-the-art (SOTA) models, especially for handwritten Devanagari text. Code and dataset has been made available at https://github.com/IITB-LEAP-OCR/TEXTRON
INSITE: labelling medical images using submodular functions and semi-supervised data programming
Feb 11, 2024
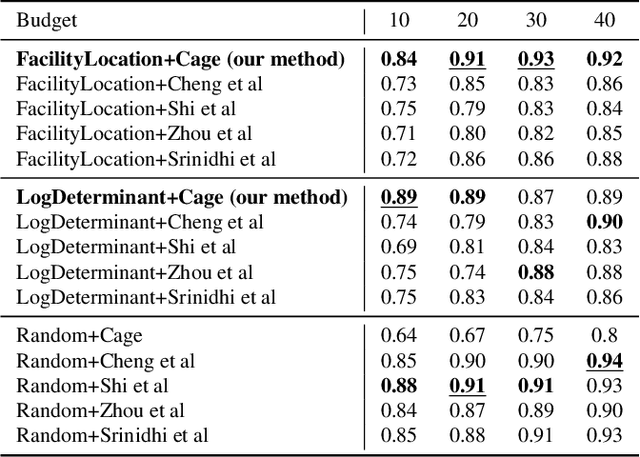
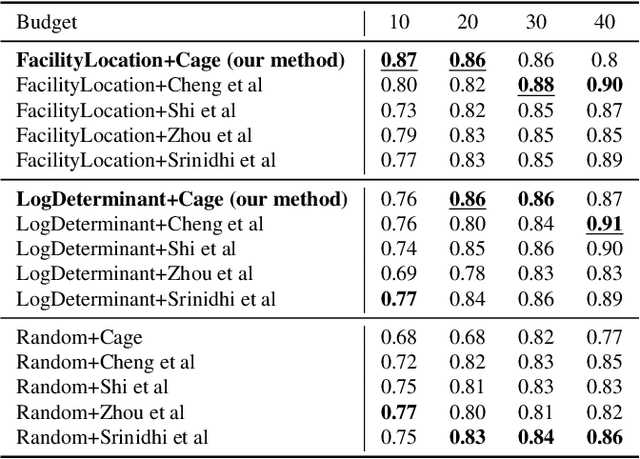
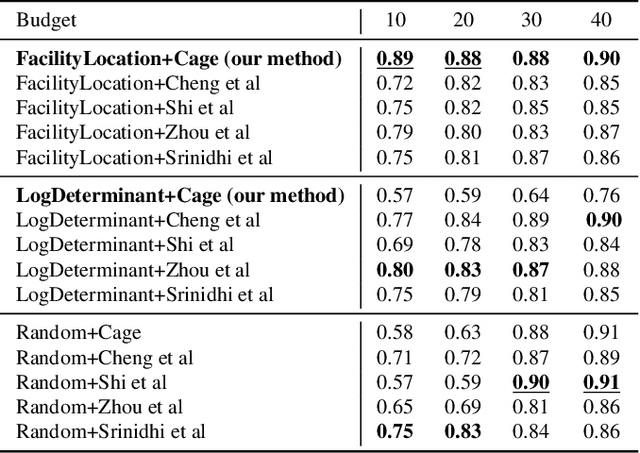
The necessity of large amounts of labeled data to train deep models, especially in medical imaging creates an implementation bottleneck in resource-constrained settings. In Insite (labelINg medical imageS usIng submodular funcTions and sEmi-supervised data programming) we apply informed subset selection to identify a small number of most representative or diverse images from a huge pool of unlabelled data subsequently annotated by a domain expert. The newly annotated images are then used as exemplars to develop several data programming-driven labeling functions. These labelling functions output a predicted-label and a similarity score when given an unlabelled image as an input. A consensus is brought amongst the outputs of these labeling functions by using a label aggregator function to assign the final predicted label to each unlabelled data point. We demonstrate that informed subset selection followed by semi-supervised data programming methods using these images as exemplars perform better than other state-of-the-art semi-supervised methods. Further, for the first time we demonstrate that this can be achieved through a small set of images used as exemplars.
EIGEN: Expert-Informed Joint Learning Aggregation for High-Fidelity Information Extraction from Document Images
Nov 23, 2023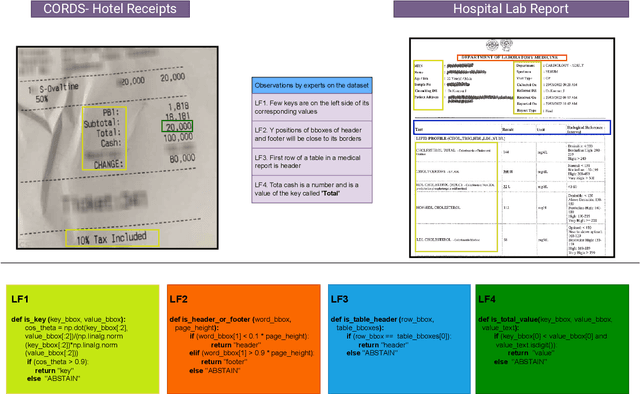



Information Extraction (IE) from document images is challenging due to the high variability of layout formats. Deep models such as LayoutLM and BROS have been proposed to address this problem and have shown promising results. However, they still require a large amount of field-level annotations for training these models. Other approaches using rule-based methods have also been proposed based on the understanding of the layout and semantics of a form such as geometric position, or type of the fields, etc. In this work, we propose a novel approach, EIGEN (Expert-Informed Joint Learning aGgrEatioN), which combines rule-based methods with deep learning models using data programming approaches to circumvent the requirement of annotation of large amounts of training data. Specifically, EIGEN consolidates weak labels induced from multiple heuristics through generative models and use them along with a small number of annotated labels to jointly train a deep model. In our framework, we propose the use of labeling functions that include incorporating contextual information thus capturing the visual and language context of a word for accurate categorization. We empirically show that our EIGEN framework can significantly improve the performance of state-of-the-art deep models with the availability of very few labeled data instances. The source code is available at https://github.com/ayushayush591/EIGEN-High-Fidelity-Extraction-Document-Images.
UDAAN - Machine Learning based Post-Editing tool for Document Translation
Mar 03, 2022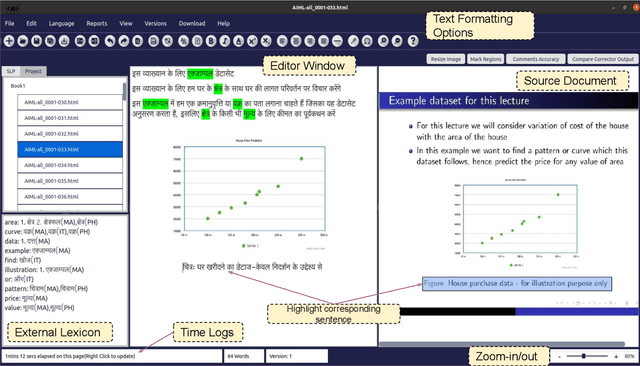
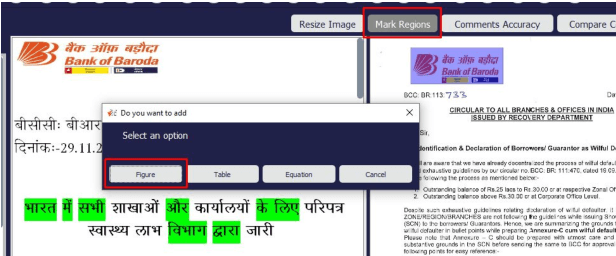
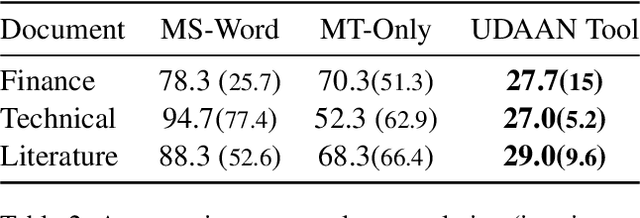
We introduce UDAAN, an open-source post-editing tool that can reduce manual editing efforts to quickly produce publishable-standard documents in different languages. UDAAN has an end-to-end Machine Translation (MT) plus post-editing pipeline wherein users can upload a document to obtain raw MT output. Further, users can edit the raw translations using our tool. UDAAN offers several advantages: a) Domain-aware, vocabulary-based lexical constrained MT. b) source-target and target-target lexicon suggestions for users. Replacements are based on the source and target texts lexicon alignment. c) Suggestions for translations are based on logs created during user interaction. d) Source-target sentence alignment visualisation that reduces the cognitive load of users during editing. e) Translated outputs from our tool are available in multiple formats: docs, latex, and PDF. Although we limit our experiments to English-to-Hindi translation for the current study, our tool is independent of the source and target languages. Experimental results based on the usage of the tools and users feedback show that our tool speeds up the translation time approximately by a factor of three compared to the baseline method of translating documents from scratch.