 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPROVE: Improving Medical Plausibility without Reliance on HumanValidation -- An Enhanced Prototype-Guided Diffusion Framework
Nov 26, 2024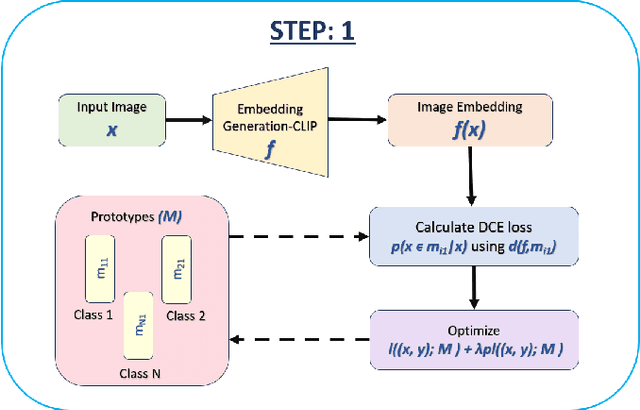

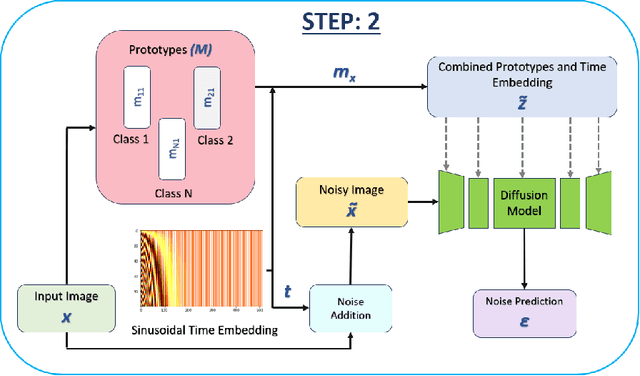
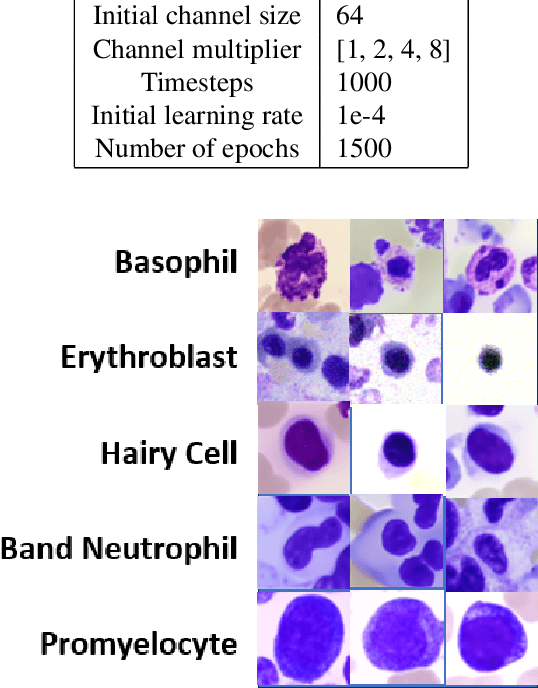
Generative models have proven to be very effective in generating synthetic medical images and find applications in downstream tasks such as enhancing rare disease datasets, long-tailed dataset augmentation, and scaling machine learning algorithms. For medical applications, the synthetically generated medical images by such models are still reasonable in quality when evaluated based on traditional metrics such as FID score, precision, and recall. However, these metrics fail to capture the medical/biological plausibility of the generated images. Human expert feedback has been used to get biological plausibility which demonstrates that these generated images have very low plausibility. Recently, the research community has further integrated this human feedback through Reinforcement Learning from Human Feedback(RLHF), which generates more medically plausible images. However, incorporating human feedback is a costly and slow process. In this work, we propose a novel approach to improve the medical plausibility of generated images without the need for human feedback. We introduce IMPROVE:Improving Medical Plausibility without Reliance on Human Validation - An Enhanced Prototype-Guided Diffusion Framework, a prototype-guided diffusion process for medical image generation and show that it substantially enhances the biological plausibility of the generated medical images without the need for any human feedback. We perform experiments on Bone Marrow and HAM10000 datasets and show that medical accuracy can be substantially increased without human feedback.
INSITE: labelling medical images using submodular functions and semi-supervised data programming
Feb 11, 2024
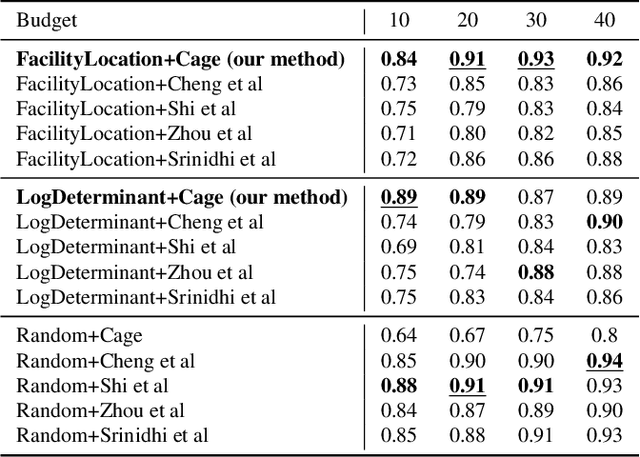
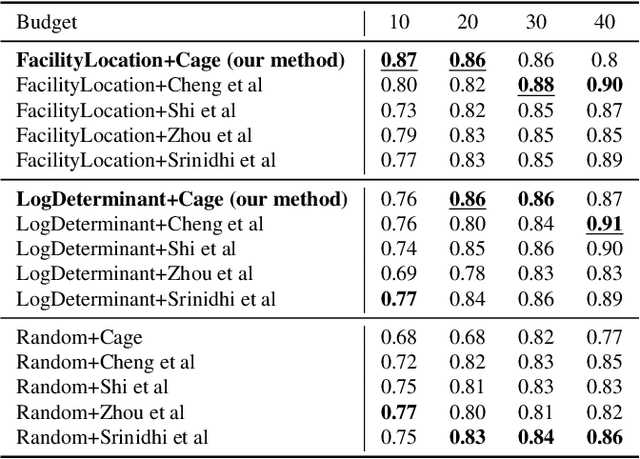
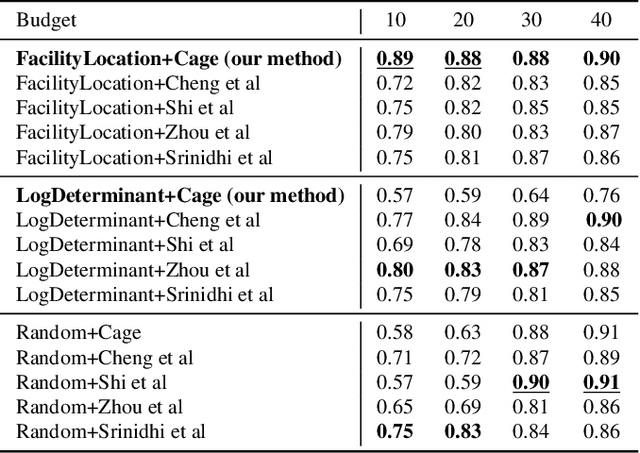
The necessity of large amounts of labeled data to train deep models, especially in medical imaging creates an implementation bottleneck in resource-constrained settings. In Insite (labelINg medical imageS usIng submodular funcTions and sEmi-supervised data programming) we apply informed subset selection to identify a small number of most representative or diverse images from a huge pool of unlabelled data subsequently annotated by a domain expert. The newly annotated images are then used as exemplars to develop several data programming-driven labeling functions. These labelling functions output a predicted-label and a similarity score when given an unlabelled image as an input. A consensus is brought amongst the outputs of these labeling functions by using a label aggregator function to assign the final predicted label to each unlabelled data point. We demonstrate that informed subset selection followed by semi-supervised data programming methods using these images as exemplars perform better than other state-of-the-art semi-supervised methods. Further, for the first time we demonstrate that this can be achieved through a small set of images used as exemplars.
Fairness for Whom? Understanding the Reader's Perception of Fairness in Text Summarization
Feb 02, 2021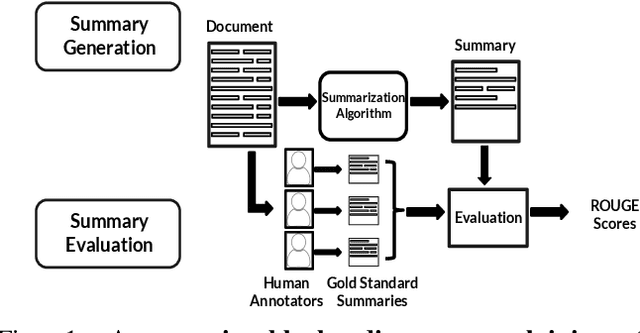

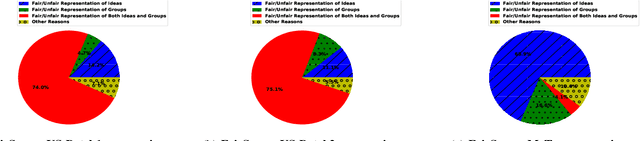

With the surge in user-generated textual information, there has been a recent increase in the use of summarization algorithms for providing an overview of the extensive content. Traditional metrics for evaluation of these algorithms (e.g. ROUGE scores) rely on matching algorithmic summaries to human-generated ones. However, it has been shown that when the textual contents are heterogeneous, e.g., when they come from different socially salient groups, most existing summarization algorithms represent the social groups very differently compared to their distribution in the original data. To mitigate such adverse impacts, some fairness-preserving summarization algorithms have also been proposed. All of these studies have considered normative notions of fairness from the perspective of writers of the contents, neglecting the readers' perceptions of the underlying fairness notions. To bridge this gap, in this work, we study the interplay between the fairness notions and how readers perceive them in textual summaries. Through our experiments, we show that reader's perception of fairness is often context-sensitive. Moreover, standard ROUGE evaluation metrics are unable to quantify the perceived (un)fairness of the summaries. To this end, we propose a human-in-the-loop metric and an automated graph-based methodology to quantify the perceived bias in textual summaries. We demonstrate their utility by quantifying the (un)fairness of several summaries of heterogeneous socio-political microblog datasets.