 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMITE: Enhancing Fairness in LLMs through Optimal In-Context Example Selection via Dynamic Validation
Aug 25, 2025Large Language Models (LLMs) are widely used for downstream tasks such as tabular classification, where ensuring fairness in their outputs is critical for inclusivity, equal representation, and responsible AI deployment. This study introduces a novel approach to enhancing LLM performance and fairness through the concept of a dynamic validation set, which evolves alongside the test set, replacing the traditional static validation approach. We also propose an iterative algorithm, SMITE, to select optimal in-context examples, with each example set validated against its corresponding dynamic validation set. The in-context set with the lowest total error is used as the final demonstration set. Our experiments across four different LLMs show that our proposed techniques significantly improve both predictive accuracy and fairness compared to baseline methods. To our knowledge, this is the first study to apply dynamic validation in the context of in-context learning for LLMs.
Rethinking Hate Speech Detection on Social Media: Can LLMs Replace Traditional Models?
Jun 15, 2025Hate speech detection across contemporary social media presents unique challenges due to linguistic diversity and the informal nature of online discourse. These challenges are further amplified in settings involving code-mixing, transliteration, and culturally nuanced expressions. While fine-tuned transformer models, such as BERT, have become standard for this task, we argue that recent large language models (LLMs) not only surpass them but also redefine the landscape of hate speech detection more broadly. To support this claim, we introduce IndoHateMix, a diverse, high-quality dataset capturing Hindi-English code-mixing and transliteration in the Indian context, providing a realistic benchmark to evaluate model robustness in complex multilingual scenarios where existing NLP methods often struggle. Our extensive experiments show that cutting-edge LLMs (such as LLaMA-3.1) consistently outperform task-specific BERT-based models, even when fine-tuned on significantly less data. With their superior generalization and adaptability, LLMs offer a transformative approach to mitigating online hate in diverse environments. This raises the question of whether future works should prioritize developing specialized models or focus on curating richer and more varied datasets to further enhance the effectiveness of LLMs.
Sometimes the Model doth Preach: Quantifying Religious Bias in Open LLMs through Demographic Analysis in Asian Nations
Mar 10, 2025Large Language Models (LLMs) are capable of generating opinions and propagating bias unknowingly, originating from unrepresentative and non-diverse data collection. Prior research has analysed these opinions with respect to the West, particularly the United States. However, insights thus produced may not be generalized in non-Western populations. With the widespread usage of LLM systems by users across several different walks of life, the cultural sensitivity of each generated output is of crucial interest. Our work proposes a novel method that quantitatively analyzes the opinions generated by LLMs, improving on previous work with regards to extracting the social demographics of the models. Our method measures the distance from an LLM's response to survey respondents, through Hamming Distance, to infer the demographic characteristics reflected in the model's outputs. We evaluate modern, open LLMs such as Llama and Mistral on surveys conducted in various global south countries, with a focus on India and other Asian nations, specifically assessing the model's performance on surveys related to religious tolerance and identity. Our analysis reveals that most open LLMs match a single homogeneous profile, varying across different countries/territories, which in turn raises questions about the risks of LLMs promoting a hegemonic worldview, and undermining perspectives of different minorities. Our framework may also be useful for future research investigating the complex intersection between training data, model architecture, and the resulting biases reflected in LLM outputs, particularly concerning sensitive topics like religious tolerance and identity.
Through the Prism of Culture: Evaluating LLMs' Understanding of Indian Subcultures and Traditions
Jan 28, 2025
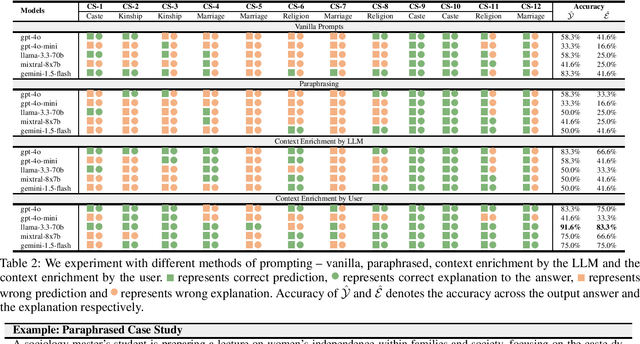


Large Language Models (LLMs) have shown remarkable advancements but also raise concerns about cultural bias, often reflecting dominant narratives at the expense of under-represented subcultures. In this study, we evaluate the capacity of LLMs to recognize and accurately respond to the Little Traditions within Indian society, encompassing localized cultural practices and subcultures such as caste, kinship, marriage, and religion. Through a series of case studies, we assess whether LLMs can balance the interplay between dominant Great Traditions and localized Little Traditions. We explore various prompting strategies and further investigate whether using prompts in regional languages enhances the models cultural sensitivity and response quality. Our findings reveal that while LLMs demonstrate an ability to articulate cultural nuances, they often struggle to apply this understanding in practical, context-specific scenarios. To the best of our knowledge, this is the first study to analyze LLMs engagement with Indian subcultures, offering critical insights into the challenges of embedding cultural diversity in AI systems.
Sponsored is the New Organic: Implications of Sponsored Results on Quality of Search Results in the Amazon Marketplace
Jul 26, 2024



Interleaving sponsored results (advertisements) amongst organic results on search engine result pages (SERP) has become a common practice across multiple digital platforms. Advertisements have catered to consumer satisfaction and fostered competition in digital public spaces; making them an appealing gateway for businesses to reach their consumers. However, especially in the context of digital marketplaces, due to the competitive nature of the sponsored results with the organic ones, multiple unwanted repercussions have surfaced affecting different stakeholders. From the consumers' perspective the sponsored ads/results may cause degradation of search quality and nudge consumers to potentially irrelevant and costlier products. The sponsored ads may also affect the level playing field of the competition in the marketplaces among sellers. To understand and unravel these potential concerns, we analyse the Amazon digital marketplace in four different countries by simulating 4,800 search operations. Our analyses over SERPs consisting 2M organic and 638K sponsored results show items with poor organic ranks (beyond 100th position) appear as sponsored results even before the top organic results on the first page of Amazon SERP. Moreover, we also observe that in majority of the cases, these top sponsored results are costlier and are of poorer quality than the top organic results. We believe these observations can motivate researchers for further deliberation to bring in more transparency and guard rails in the advertising practices followed in digital marketplaces.
Investigating Nudges toward Related Sellers on E-commerce Marketplaces: A Case Study on Amazon
Jul 01, 2024



E-commerce marketplaces provide business opportunities to millions of sellers worldwide. Some of these sellers have special relationships with the marketplace by virtue of using their subsidiary services (e.g., fulfillment and/or shipping services provided by the marketplace) -- we refer to such sellers collectively as Related Sellers. When multiple sellers offer to sell the same product, the marketplace helps a customer in selecting an offer (by a seller) through (a) a default offer selection algorithm, (b) showing features about each of the offers and the corresponding sellers (price, seller performance metrics, seller's number of ratings etc.), and (c) finally evaluating the sellers along these features. In this paper, we perform an end-to-end investigation into how the above apparatus can nudge customers toward the Related Sellers on Amazon's four different marketplaces in India, USA, Germany and France. We find that given explicit choices, customers' preferred offers and algorithmically selected offers can be significantly different. We highlight that Amazon is adopting different performance metric evaluation policies for different sellers, potentially benefiting Related Sellers. For instance, such policies result in notable discrepancy between the actual performance metric and the presented performance metric of Related Sellers. We further observe that among the seller-centric features visible to customers, sellers' number of ratings influences their decisions the most, yet it may not reflect the true quality of service by the seller, rather reflecting the scale at which the seller operates, thereby implicitly steering customers toward larger Related Sellers. Moreover, when customers are shown the rectified metrics for the different sellers, their preference toward Related Sellers is almost halved.
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Jun 22, 2024Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. Inherently LLMs produce abstractive summaries, and the task of achieving extractive summaries through LLMs still remains largely unexplored. To bridge this gap, in this work, we propose a novel framework LaMSUM to generate extractive summaries through LLMs for large user-generated text by leveraging voting algorithms. Our evaluation on three popular open-source LLMs (Llama 3, Mixtral and Gemini) reveal that the LaMSUM outperforms state-of-the-art extractive summarization methods. We further attempt to provide the rationale behind the output summary produced by LLMs. Overall, this is one of the early attempts to achieve extractive summarization for large user-generated text by utilizing LLMs, and likely to generate further interest in the community.
Artificial Intelligence (AI) in Legal Data Mining
May 23, 2024Despite the availability of vast amounts of data, legal data is often unstructured, making it difficult even for law practitioners to ingest and comprehend the same. It is important to organise the legal information in a way that is useful for practitioners and downstream automation tasks. The word ontology was used by Greek philosophers to discuss concepts of existence, being, becoming and reality. Today, scientists use this term to describe the relation between concepts, data, and entities. A great example for a working ontology was developed by Dhani and Bhatt. This ontology deals with Indian court cases on intellectual property rights (IPR) The future of legal ontologies is likely to be handled by computer experts and legal experts alike.
Antitrust, Amazon, and Algorithmic Auditing
Mar 27, 2024



In digital markets, antitrust law and special regulations aim to ensure that markets remain competitive despite the dominating role that digital platforms play today in everyone's life. Unlike traditional markets, market participant behavior is easily observable in these markets. We present a series of empirical investigations into the extent to which Amazon engages in practices that are typically described as self-preferencing. We discuss how the computer science tools used in this paper can be used in a regulatory environment that is based on algorithmic auditing and requires regulating digital markets at scale.
Few-Shot Fairness: Unveiling LLM's Potential for Fairness-Aware Classification
Feb 28, 2024



Employing Large Language Models (LLM) in various downstream applications such as classification is crucial, especially for smaller companies lacking the expertise and resources required for fine-tuning a model. Fairness in LLMs helps ensure inclusivity, equal representation based on factors such as race, gender and promotes responsible AI deployment. As the use of LLMs has become increasingly prevalent, it is essential to assess whether LLMs can generate fair outcomes when subjected to considerations of fairness. In this study, we introduce a framework outlining fairness regulations aligned with various fairness definitions, with each definition being modulated by varying degrees of abstraction. We explore the configuration for in-context learning and the procedure for selecting in-context demonstrations using RAG, while incorporating fairness rules into the process. Experiments conducted with different LLMs indicate that GPT-4 delivers superior results in terms of both accuracy and fairness compared to other models. This work is one of the early attempts to achieve fairness in prediction tasks by utilizing LLMs through in-context learning.