 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADVOSYNTH: A Synthetic Multi-Advocate Dataset for Speaker Identification in Courtroom Scenarios
Jan 15, 2026As large-scale speech-to-speech models achieve high fidelity, the distinction between synthetic voices in structured environments becomes a vital area of study. This paper introduces Advosynth-500, a specialized dataset comprising 100 synthetic speech files featuring 10 unique advocate identities. Using the Speech Llama Omni model, we simulate five distinct advocate pairs engaged in courtroom arguments. We define specific vocal characteristics for each advocate and present a speaker identification challenge to evaluate the ability of modern systems to map audio files to their respective synthetic origins. Dataset is available at this link-https: //github.com/naturenurtureelite/ADVOSYNTH-500.
STRIVE: A Think & Improve Approach with Iterative Refinement for Enhancing Question Quality Estimation
Apr 08, 2025Automatically assessing question quality is crucial for educators as it saves time, ensures consistency, and provides immediate feedback for refining teaching materials. We propose a novel methodology called STRIVE (Structured Thinking and Refinement with multiLLMs for Improving Verified Question Estimation) using a series of Large Language Models (LLMs) for automatic question evaluation. This approach aims to improve the accuracy and depth of question quality assessment, ultimately supporting diverse learners and enhancing educational practices. The method estimates question quality in an automated manner by generating multiple evaluations based on the strengths and weaknesses of the provided question and then choosing the best solution generated by the LLM. Then the process is improved by iterative review and response with another LLM until the evaluation metric values converge. This sophisticated method of evaluating question quality improves the estimation of question quality by automating the task of question quality evaluation. Correlation scores show that using this proposed method helps to improve correlation with human judgments compared to the baseline method. Error analysis shows that metrics like relevance and appropriateness improve significantly relative to human judgments by using STRIVE.
Leveraging Prompt-Tuning for Bengali Grammatical Error Explanation Using Large Language Models
Apr 08, 2025We propose a novel three-step prompt-tuning method for Bengali Grammatical Error Explanation (BGEE) using state-of-the-art large language models (LLMs) such as GPT-4, GPT-3.5 Turbo, and Llama-2-70b. Our approach involves identifying and categorizing grammatical errors in Bengali sentences, generating corrected versions of the sentences, and providing natural language explanations for each identified error. We evaluate the performance of our BGEE system using both automated evaluation metrics and human evaluation conducted by experienced Bengali language experts. Our proposed prompt-tuning approach shows that GPT-4, the best performing LLM, surpasses the baseline model in automated evaluation metrics, with a 5.26% improvement in F1 score and a 6.95% improvement in exact match. Furthermore, compared to the previous baseline, GPT-4 demonstrates a decrease of 25.51% in wrong error type and a decrease of 26.27% in wrong error explanation. However, the results still lag behind the human baseline.
Towards Smarter Hiring: Are Zero-Shot and Few-Shot Pre-trained LLMs Ready for HR Spoken Interview Transcript Analysis?
Apr 08, 2025This research paper presents a comprehensive analysis of the performance of prominent pre-trained large language models (LLMs), including GPT-4 Turbo, GPT-3.5 Turbo, text-davinci-003, text-babbage-001, text-curie-001, text-ada-001, llama-2-7b-chat, llama-2-13b-chat, and llama-2-70b-chat, in comparison to expert human evaluators in providing scores, identifying errors, and offering feedback and improvement suggestions to candidates during mock HR (Human Resources) interviews. We introduce a dataset called HURIT (Human Resource Interview Transcripts), which comprises 3,890 HR interview transcripts sourced from real-world HR interview scenarios. Our findings reveal that pre-trained LLMs, particularly GPT-4 Turbo and GPT-3.5 Turbo, exhibit commendable performance and are capable of producing evaluations comparable to those of expert human evaluators. Although these LLMs demonstrate proficiency in providing scores comparable to human experts in terms of human evaluation metrics, they frequently fail to identify errors and offer specific actionable advice for candidate performance improvement in HR interviews. Our research suggests that the current state-of-the-art pre-trained LLMs are not fully conducive for automatic deployment in an HR interview assessment. Instead, our findings advocate for a human-in-the-loop approach, to incorporate manual checks for inconsistencies and provisions for improving feedback quality as a more suitable strategy.
Leveraging In-Context Learning and Retrieval-Augmented Generation for Automatic Question Generation in Educational Domains
Jan 29, 2025Question generation in education is a time-consuming and cognitively demanding task, as it requires creating questions that are both contextually relevant and pedagogically sound. Current automated question generation methods often generate questions that are out of context. In this work, we explore advanced techniques for automated question generation in educational contexts, focusing on In-Context Learning (ICL), Retrieval-Augmented Generation (RAG), and a novel Hybrid Model that merges both methods. We implement GPT-4 for ICL using few-shot examples and BART with a retrieval module for RAG. The Hybrid Model combines RAG and ICL to address these issues and improve question quality. Evaluation is conducted using automated metrics, followed by human evaluation metrics. Our results show that both the ICL approach and the Hybrid Model consistently outperform other methods, including baseline models, by generating more contextually accurate and relevant questions.
HateGPT: Unleashing GPT-3.5 Turbo to Combat Hate Speech on X
Nov 14, 2024
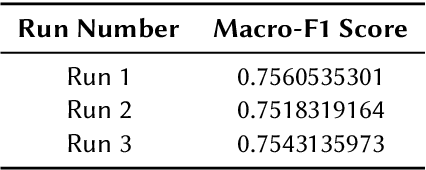
The widespread use of social media platforms like Twitter and Facebook has enabled people of all ages to share their thoughts and experiences, leading to an immense accumulation of user-generated content. However, alongside the benefits, these platforms also face the challenge of managing hate speech and offensive content, which can undermine rational discourse and threaten democratic values. As a result, there is a growing need for automated methods to detect and mitigate such content, especially given the complexity of conversations that may require contextual analysis across multiple languages, including code-mixed languages like Hinglish, German-English, and Bangla. We participated in the English task where we have to classify English tweets into two categories namely Hate and Offensive and Non Hate-Offensive. In this work, we experiment with state-of-the-art large language models like GPT-3.5 Turbo via prompting to classify tweets into Hate and Offensive or Non Hate-Offensive. In this study, we evaluate the performance of a classification model using Macro-F1 scores across three distinct runs. The Macro-F1 score, which balances precision and recall across all classes, is used as the primary metric for model evaluation. The scores obtained are 0.756 for run 1, 0.751 for run 2, and 0.754 for run 3, indicating a high level of performance with minimal variance among the runs. The results suggest that the model consistently performs well in terms of precision and recall, with run 1 showing the highest performance. These findings highlight the robustness and reliability of the model across different runs.
CryptoLLM: Unleashing the Power of Prompted LLMs for SmartQnA and Classification of Crypto Posts
Nov 12, 2024The rapid growth of social media has resulted in an large volume of user-generated content, particularly in niche domains such as cryptocurrency. This task focuses on developing robust classification models to accurately categorize cryptocurrency-related social media posts into predefined classes, including but not limited to objective, positive, negative, etc. Additionally, the task requires participants to identify the most relevant answers from a set of posts in response to specific questions. By leveraging advanced LLMs, this research aims to enhance the understanding and filtering of cryptocurrency discourse, thereby facilitating more informed decision-making in this volatile sector. We have used a prompt-based technique to solve the classification task for reddit posts and twitter posts. Also, we have used 64-shot technique along with prompts on GPT-4-Turbo model to determine whether a answer is relevant to a question or not.
Cancer-Answer: Empowering Cancer Care with Advanced Large Language Models
Nov 11, 2024Gastrointestinal (GI) tract cancers account for a substantial portion of the global cancer burden, where early diagnosis is critical for improved management and patient outcomes. The complex aetiologies and overlapping symptoms across GI cancers often delay diagnosis, leading to suboptimal treatment strategies. Cancer-related queries are crucial for timely diagnosis, treatment, and patient education, as access to accurate, comprehensive information can significantly influence outcomes. However, the complexity of cancer as a disease, combined with the vast amount of available data, makes it difficult for clinicians and patients to quickly find precise answers. To address these challenges, we leverage large language models (LLMs) such as GPT-3.5 Turbo to generate accurate, contextually relevant responses to cancer-related queries. Pre-trained with medical data, these models provide timely, actionable insights that support informed decision-making in cancer diagnosis and care, ultimately improving patient outcomes. We calculate two metrics: A1 (which represents the fraction of entities present in the model-generated answer compared to the gold standard) and A2 (which represents the linguistic correctness and meaningfulness of the model-generated answer with respect to the gold standard), achieving maximum values of 0.546 and 0.881, respectively.
RetrieveGPT: Merging Prompts and Mathematical Models for Enhanced Code-Mixed Information Retrieval
Nov 07, 2024
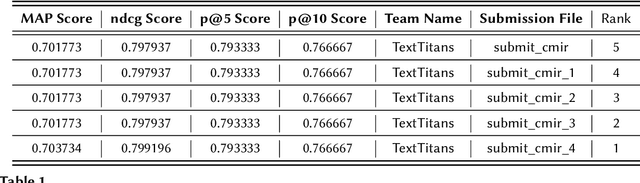
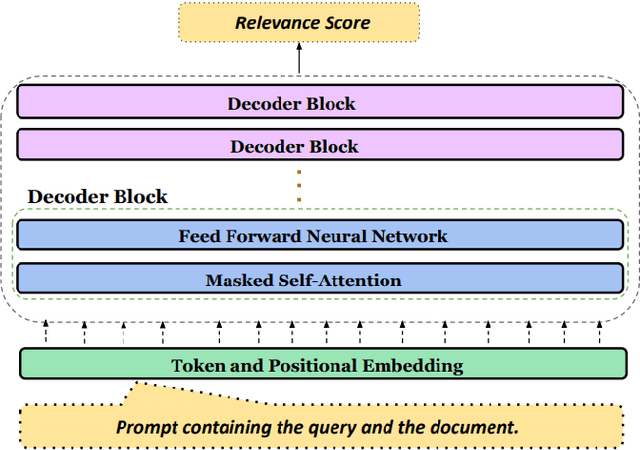
Code-mixing, the integration of lexical and grammatical elements from multiple languages within a single sentence, is a widespread linguistic phenomenon, particularly prevalent in multilingual societies. In India, social media users frequently engage in code-mixed conversations using the Roman script, especially among migrant communities who form online groups to share relevant local information. This paper focuses on the challenges of extracting relevant information from code-mixed conversations, specifically within Roman transliterated Bengali mixed with English. This study presents a novel approach to address these challenges by developing a mechanism to automatically identify the most relevant answers from code-mixed conversations. We have experimented with a dataset comprising of queries and documents from Facebook, and Query Relevance files (QRels) to aid in this task. Our results demonstrate the effectiveness of our approach in extracting pertinent information from complex, code-mixed digital conversations, contributing to the broader field of natural language processing in multilingual and informal text environments. We use GPT-3.5 Turbo via prompting alongwith using the sequential nature of relevant documents to frame a mathematical model which helps to detect relevant documents corresponding to a query.
Prompt Engineering Using GPT for Word-Level Code-Mixed Language Identification in Low-Resource Dravidian Languages
Nov 06, 2024



Language Identification (LI) is crucial for various natural language processing tasks, serving as a foundational step in applications such as sentiment analysis, machine translation, and information retrieval. In multilingual societies like India, particularly among the youth engaging on social media, text often exhibits code-mixing, blending local languages with English at different linguistic levels. This phenomenon presents formidable challenges for LI systems, especially when languages intermingle within single words. Dravidian languages, prevalent in southern India, possess rich morphological structures yet suffer from under-representation in digital platforms, leading to the adoption of Roman or hybrid scripts for communication. This paper introduces a prompt based method for a shared task aimed at addressing word-level LI challenges in Dravidian languages. In this work, we leveraged GPT-3.5 Turbo to understand whether the large language models is able to correctly classify words into correct categories. Our findings show that the Kannada model consistently outperformed the Tamil model across most metrics, indicating a higher accuracy and reliability in identifying and categorizing Kannada language instances. In contrast, the Tamil model showed moderate performance, particularly needing improvement in precision and recall.