 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVehicle Routing with Finite Time Horizon using Deep Reinforcement Learning with Improved Network Embedding
Jan 21, 2026In this paper, we study the vehicle routing problem with a finite time horizon. In this routing problem, the objective is to maximize the number of customer requests served within a finite time horizon. We present a novel routing network embedding module which creates local node embedding vectors and a context-aware global graph representation. The proposed Markov decision process for the vehicle routing problem incorporates the node features, the network adjacency matrix and the edge features as components of the state space. We incorporate the remaining finite time horizon into the network embedding module to provide a proper routing context to the embedding module. We integrate our embedding module with a policy gradient-based deep Reinforcement Learning framework to solve the vehicle routing problem with finite time horizon. We trained and validated our proposed routing method on real-world routing networks, as well as synthetically generated Euclidean networks. Our experimental results show that our method achieves a higher customer service rate than the existing routing methods. Additionally, the solution time of our method is significantly lower than that of the existing methods.
Towards Smarter Hiring: Are Zero-Shot and Few-Shot Pre-trained LLMs Ready for HR Spoken Interview Transcript Analysis?
Apr 08, 2025This research paper presents a comprehensive analysis of the performance of prominent pre-trained large language models (LLMs), including GPT-4 Turbo, GPT-3.5 Turbo, text-davinci-003, text-babbage-001, text-curie-001, text-ada-001, llama-2-7b-chat, llama-2-13b-chat, and llama-2-70b-chat, in comparison to expert human evaluators in providing scores, identifying errors, and offering feedback and improvement suggestions to candidates during mock HR (Human Resources) interviews. We introduce a dataset called HURIT (Human Resource Interview Transcripts), which comprises 3,890 HR interview transcripts sourced from real-world HR interview scenarios. Our findings reveal that pre-trained LLMs, particularly GPT-4 Turbo and GPT-3.5 Turbo, exhibit commendable performance and are capable of producing evaluations comparable to those of expert human evaluators. Although these LLMs demonstrate proficiency in providing scores comparable to human experts in terms of human evaluation metrics, they frequently fail to identify errors and offer specific actionable advice for candidate performance improvement in HR interviews. Our research suggests that the current state-of-the-art pre-trained LLMs are not fully conducive for automatic deployment in an HR interview assessment. Instead, our findings advocate for a human-in-the-loop approach, to incorporate manual checks for inconsistencies and provisions for improving feedback quality as a more suitable strategy.
Leveraging In-Context Learning and Retrieval-Augmented Generation for Automatic Question Generation in Educational Domains
Jan 29, 2025Question generation in education is a time-consuming and cognitively demanding task, as it requires creating questions that are both contextually relevant and pedagogically sound. Current automated question generation methods often generate questions that are out of context. In this work, we explore advanced techniques for automated question generation in educational contexts, focusing on In-Context Learning (ICL), Retrieval-Augmented Generation (RAG), and a novel Hybrid Model that merges both methods. We implement GPT-4 for ICL using few-shot examples and BART with a retrieval module for RAG. The Hybrid Model combines RAG and ICL to address these issues and improve question quality. Evaluation is conducted using automated metrics, followed by human evaluation metrics. Our results show that both the ICL approach and the Hybrid Model consistently outperform other methods, including baseline models, by generating more contextually accurate and relevant questions.
MIRROR: A Novel Approach for the Automated Evaluation of Open-Ended Question Generation
Oct 16, 2024Automatic question generation is a critical task that involves evaluating question quality by considering factors such as engagement, pedagogical value, and the ability to stimulate critical thinking. These aspects require human-like understanding and judgment, which automated systems currently lack. However, human evaluations are costly and impractical for large-scale samples of generated questions. Therefore, we propose a novel system, MIRROR (Multi-LLM Iterative Review and Response for Optimized Rating), which leverages large language models (LLMs) to automate the evaluation process for questions generated by automated question generation systems. We experimented with several state-of-the-art LLMs, such as GPT-4, Gemini, and Llama2-70b. We observed that the scores of human evaluation metrics, namely relevance, appropriateness, novelty, complexity, and grammaticality, improved when using the feedback-based approach called MIRROR, tending to be closer to the human baseline scores. Furthermore, we observed that Pearson's correlation coefficient between GPT-4 and human experts improved when using our proposed feedback-based approach, MIRROR, compared to direct prompting for evaluation. Error analysis shows that our proposed approach, MIRROR, significantly helps to improve relevance and appropriateness.
Enhancing Low-Resource NMT with a Multilingual Encoder and Knowledge Distillation: A Case Study
Jul 09, 2024Neural Machine Translation (NMT) remains a formidable challenge, especially when dealing with low-resource languages. Pre-trained sequence-to-sequence (seq2seq) multi-lingual models, such as mBART-50, have demonstrated impressive performance in various low-resource NMT tasks. However, their pre-training has been confined to 50 languages, leaving out support for numerous low-resource languages, particularly those spoken in the Indian subcontinent. Expanding mBART-50's language support requires complex pre-training, risking performance decline due to catastrophic forgetting. Considering these expanding challenges, this paper explores a framework that leverages the benefits of a pre-trained language model along with knowledge distillation in a seq2seq architecture to facilitate translation for low-resource languages, including those not covered by mBART-50. The proposed framework employs a multilingual encoder-based seq2seq model as the foundational architecture and subsequently uses complementary knowledge distillation techniques to mitigate the impact of imbalanced training. Our framework is evaluated on three low-resource Indic languages in four Indic-to-Indic directions, yielding significant BLEU-4 and chrF improvements over baselines. Further, we conduct human evaluation to confirm effectiveness of our approach. Our code is publicly available at https://github.com/raypretam/Two-step-low-res-NMT.
How Effective is GPT-4 Turbo in Generating School-Level Questions from Textbooks Based on Bloom's Revised Taxonomy?
Jun 21, 2024
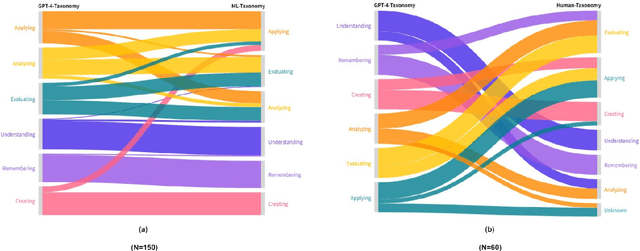
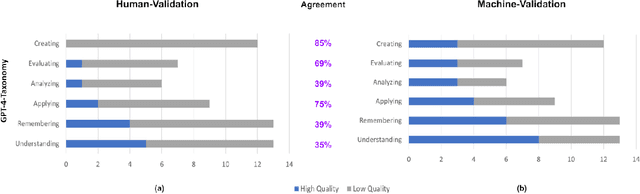
We evaluate the effectiveness of GPT-4 Turbo in generating educational questions from NCERT textbooks in zero-shot mode. Our study highlights GPT-4 Turbo's ability to generate questions that require higher-order thinking skills, especially at the "understanding" level according to Bloom's Revised Taxonomy. While we find a notable consistency between questions generated by GPT-4 Turbo and those assessed by humans in terms of complexity, there are occasional differences. Our evaluation also uncovers variations in how humans and machines evaluate question quality, with a trend inversely related to Bloom's Revised Taxonomy levels. These findings suggest that while GPT-4 Turbo is a promising tool for educational question generation, its efficacy varies across different cognitive levels, indicating a need for further refinement to fully meet educational standards.
How Ready Are Generative Pre-trained Large Language Models for Explaining Bengali Grammatical Errors?
May 27, 2024Grammatical error correction (GEC) tools, powered by advanced generative artificial intelligence (AI), competently correct linguistic inaccuracies in user input. However, they often fall short in providing essential natural language explanations, which are crucial for learning languages and gaining a deeper understanding of the grammatical rules. There is limited exploration of these tools in low-resource languages such as Bengali. In such languages, grammatical error explanation (GEE) systems should not only correct sentences but also provide explanations for errors. This comprehensive approach can help language learners in their quest for proficiency. Our work introduces a real-world, multi-domain dataset sourced from Bengali speakers of varying proficiency levels and linguistic complexities. This dataset serves as an evaluation benchmark for GEE systems, allowing them to use context information to generate meaningful explanations and high-quality corrections. Various generative pre-trained large language models (LLMs), including GPT-4 Turbo, GPT-3.5 Turbo, Text-davinci-003, Text-babbage-001, Text-curie-001, Text-ada-001, Llama-2-7b, Llama-2-13b, and Llama-2-70b, are assessed against human experts for performance comparison. Our research underscores the limitations in the automatic deployment of current state-of-the-art generative pre-trained LLMs for Bengali GEE. Advocating for human intervention, our findings propose incorporating manual checks to address grammatical errors and improve feedback quality. This approach presents a more suitable strategy to refine the GEC tools in Bengali, emphasizing the educational aspect of language learning.
Exploring the Capabilities of Prompted Large Language Models in Educational and Assessment Applications
May 19, 2024In the era of generative artificial intelligence (AI), the fusion of large language models (LLMs) offers unprecedented opportunities for innovation in the field of modern education. We embark on an exploration of prompted LLMs within the context of educational and assessment applications to uncover their potential. Through a series of carefully crafted research questions, we investigate the effectiveness of prompt-based techniques in generating open-ended questions from school-level textbooks, assess their efficiency in generating open-ended questions from undergraduate-level technical textbooks, and explore the feasibility of employing a chain-of-thought inspired multi-stage prompting approach for language-agnostic multiple-choice question (MCQ) generation. Additionally, we evaluate the ability of prompted LLMs for language learning, exemplified through a case study in the low-resource Indian language Bengali, to explain Bengali grammatical errors. We also evaluate the potential of prompted LLMs to assess human resource (HR) spoken interview transcripts. By juxtaposing the capabilities of LLMs with those of human experts across various educational tasks and domains, our aim is to shed light on the potential and limitations of LLMs in reshaping educational practices.
From Text to Context: An Entailment Approach for News Stakeholder Classification
May 14, 2024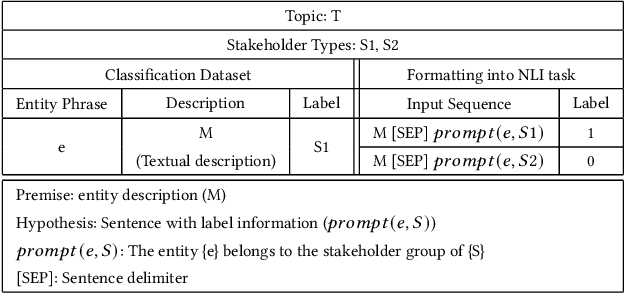



Navigating the complex landscape of news articles involves understanding the various actors or entities involved, referred to as news stakeholders. These stakeholders, ranging from policymakers to opposition figures, citizens, and more, play pivotal roles in shaping news narratives. Recognizing their stakeholder types, reflecting their roles, political alignments, social standing, and more, is paramount for a nuanced comprehension of news content. Despite existing works focusing on salient entity extraction, coverage variations, and political affiliations through social media data, the automated detection of stakeholder roles within news content remains an underexplored domain. In this paper, we bridge this gap by introducing an effective approach to classify stakeholder types in news articles. Our method involves transforming the stakeholder classification problem into a natural language inference task, utilizing contextual information from news articles and external knowledge to enhance the accuracy of stakeholder type detection. Moreover, our proposed model showcases efficacy in zero-shot settings, further extending its applicability to diverse news contexts.
Deciphering Political Entity Sentiment in News with Large Language Models: Zero-Shot and Few-Shot Strategies
Apr 05, 2024Sentiment analysis plays a pivotal role in understanding public opinion, particularly in the political domain where the portrayal of entities in news articles influences public perception. In this paper, we investigate the effectiveness of Large Language Models (LLMs) in predicting entity-specific sentiment from political news articles. Leveraging zero-shot and few-shot strategies, we explore the capability of LLMs to discern sentiment towards political entities in news content. Employing a chain-of-thought (COT) approach augmented with rationale in few-shot in-context learning, we assess whether this method enhances sentiment prediction accuracy. Our evaluation on sentiment-labeled datasets demonstrates that LLMs, outperform fine-tuned BERT models in capturing entity-specific sentiment. We find that learning in-context significantly improves model performance, while the self-consistency mechanism enhances consistency in sentiment prediction. Despite the promising results, we observe inconsistencies in the effectiveness of the COT prompting method. Overall, our findings underscore the potential of LLMs in entity-centric sentiment analysis within the political news domain and highlight the importance of suitable prompting strategies and model architectures.