 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Sentiment Polarity Reduction in News Presentation through Contextual Perturbation and Large Language Models
Feb 03, 2024In today's media landscape, where news outlets play a pivotal role in shaping public opinion, it is imperative to address the issue of sentiment manipulation within news text. News writers often inject their own biases and emotional language, which can distort the objectivity of reporting. This paper introduces a novel approach to tackle this problem by reducing the polarity of latent sentiments in news content. Drawing inspiration from adversarial attack-based sentence perturbation techniques and a prompt based method using ChatGPT, we employ transformation constraints to modify sentences while preserving their core semantics. Using three perturbation methods: replacement, insertion, and deletion coupled with a context-aware masked language model, we aim to maximize the desired sentiment score for targeted news aspects through a beam search algorithm. Our experiments and human evaluations demonstrate the effectiveness of these two models in achieving reduced sentiment polarity with minimal modifications while maintaining textual similarity, fluency, and grammatical correctness. Comparative analysis confirms the competitive performance of the adversarial attack based perturbation methods and prompt-based methods, offering a promising solution to foster more objective news reporting and combat emotional language bias in the media.
Towards Adversarial Purification using Denoising AutoEncoders
Aug 29, 2022
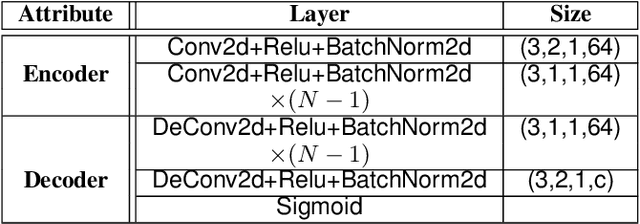
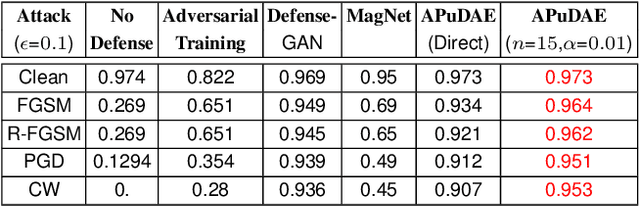

With the rapid advancement and increased use of deep learning models in image identification, security becomes a major concern to their deployment in safety-critical systems. Since the accuracy and robustness of deep learning models are primarily attributed from the purity of the training samples, therefore the deep learning architectures are often susceptible to adversarial attacks. Adversarial attacks are often obtained by making subtle perturbations to normal images, which are mostly imperceptible to humans, but can seriously confuse the state-of-the-art machine learning models. We propose a framework, named APuDAE, leveraging Denoising AutoEncoders (DAEs) to purify these samples by using them in an adaptive way and thus improve the classification accuracy of the target classifier networks that have been attacked. We also show how using DAEs adaptively instead of using them directly, improves classification accuracy further and is more robust to the possibility of designing adaptive attacks to fool them. We demonstrate our results over MNIST, CIFAR-10, ImageNet dataset and show how our framework (APuDAE) provides comparable and in most cases better performance to the baseline methods in purifying adversaries. We also design adaptive attack specifically designed to attack our purifying model and demonstrate how our defense is robust to that.
Resisting Adversarial Attacks in Deep Neural Networks using Diverse Decision Boundaries
Aug 18, 2022


The security of deep learning (DL) systems is an extremely important field of study as they are being deployed in several applications due to their ever-improving performance to solve challenging tasks. Despite overwhelming promises, the deep learning systems are vulnerable to crafted adversarial examples, which may be imperceptible to the human eye, but can lead the model to misclassify. Protections against adversarial perturbations on ensemble-based techniques have either been shown to be vulnerable to stronger adversaries or shown to lack an end-to-end evaluation. In this paper, we attempt to develop a new ensemble-based solution that constructs defender models with diverse decision boundaries with respect to the original model. The ensemble of classifiers constructed by (1) transformation of the input by a method called Split-and-Shuffle, and (2) restricting the significant features by a method called Contrast-Significant-Features are shown to result in diverse gradients with respect to adversarial attacks, which reduces the chance of transferring adversarial examples from the original to the defender model targeting the same class. We present extensive experimentations using standard image classification datasets, namely MNIST, CIFAR-10 and CIFAR-100 against state-of-the-art adversarial attacks to demonstrate the robustness of the proposed ensemble-based defense. We also evaluate the robustness in the presence of a stronger adversary targeting all the models within the ensemble simultaneously. Results for the overall false positives and false negatives have been furnished to estimate the overall performance of the proposed methodology.
Deep Learning-based Spatially Explicit Emulation of an Agent-Based Simulator for Pandemic in a City
May 28, 2022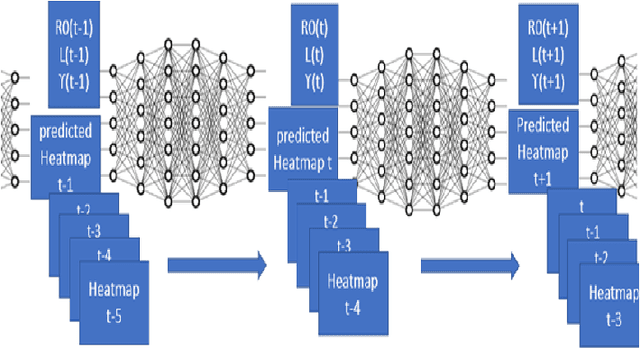

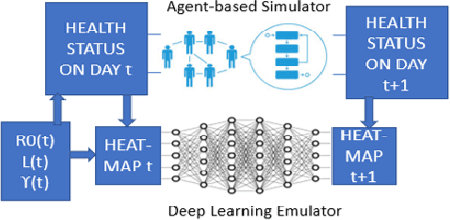

Agent-Based Models are very useful for simulation of physical or social processes, such as the spreading of a pandemic in a city. Such models proceed by specifying the behavior of individuals (agents) and their interactions, and parameterizing the process of infection based on such interactions based on the geography and demography of the city. However, such models are computationally very expensive, and the complexity is often linear in the total number of agents. This seriously limits the usage of such models for simulations, which often have to be run hundreds of times for policy planning and even model parameter estimation. An alternative is to develop an emulator, a surrogate model that can predict the Agent-Based Simulator's output based on its initial conditions and parameters. In this paper, we discuss a Deep Learning model based on Dilated Convolutional Neural Network that can emulate such an agent based model with high accuracy. We show that use of this model instead of the original Agent-Based Model provides us major gains in the speed of simulations, allowing much quicker calibration to observations, and more extensive scenario analysis. The models we consider are spatially explicit, as the locations of the infected individuals are simulated instead of the gross counts. Another aspect of our emulation framework is its divide-and-conquer approach that divides the city into several small overlapping blocks and carries out the emulation in them parallelly, after which these results are merged together. This ensures that the same emulator can work for a city of any size, and also provides significant improvement of time complexity of the emulator, compared to the original simulator.
PARL: Enhancing Diversity of Ensemble Networks to Resist Adversarial Attacks via Pairwise Adversarially Robust Loss Function
Dec 09, 2021
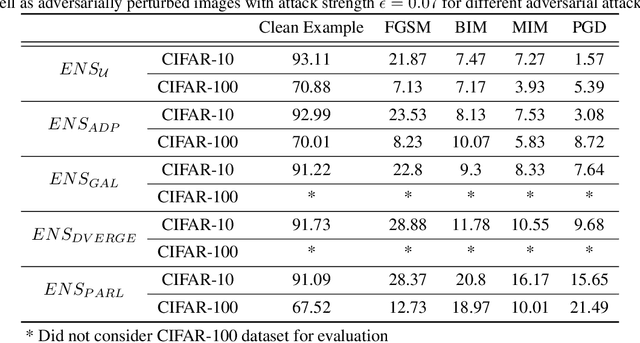
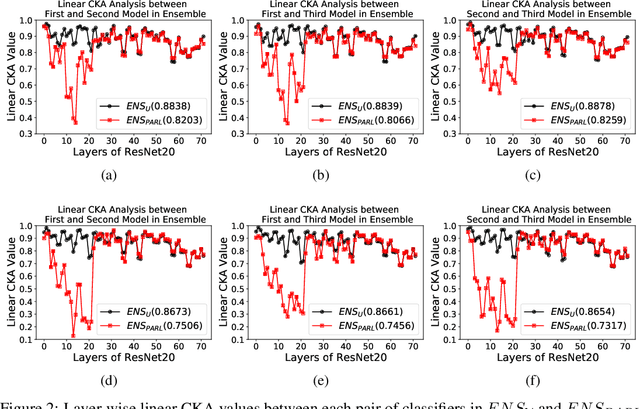

The security of Deep Learning classifiers is a critical field of study because of the existence of adversarial attacks. Such attacks usually rely on the principle of transferability, where an adversarial example crafted on a surrogate classifier tends to mislead the target classifier trained on the same dataset even if both classifiers have quite different architecture. Ensemble methods against adversarial attacks demonstrate that an adversarial example is less likely to mislead multiple classifiers in an ensemble having diverse decision boundaries. However, recent ensemble methods have either been shown to be vulnerable to stronger adversaries or shown to lack an end-to-end evaluation. This paper attempts to develop a new ensemble methodology that constructs multiple diverse classifiers using a Pairwise Adversarially Robust Loss (PARL) function during the training procedure. PARL utilizes gradients of each layer with respect to input in every classifier within the ensemble simultaneously. The proposed training procedure enables PARL to achieve higher robustness against black-box transfer attacks compared to previous ensemble methods without adversely affecting the accuracy of clean examples. We also evaluate the robustness in the presence of white-box attacks, where adversarial examples are crafted using parameters of the target classifier. We present extensive experiments using standard image classification datasets like CIFAR-10 and CIFAR-100 trained using standard ResNet20 classifier against state-of-the-art adversarial attacks to demonstrate the robustness of the proposed ensemble methodology.
Detecting Adversaries, yet Faltering to Noise? Leveraging Conditional Variational AutoEncoders for Adversary Detection in the Presence of Noisy Images
Dec 09, 2021

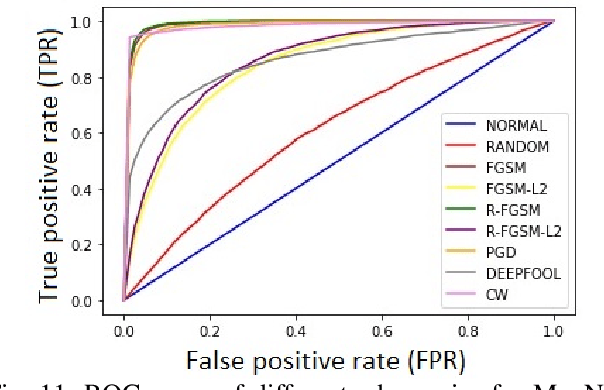
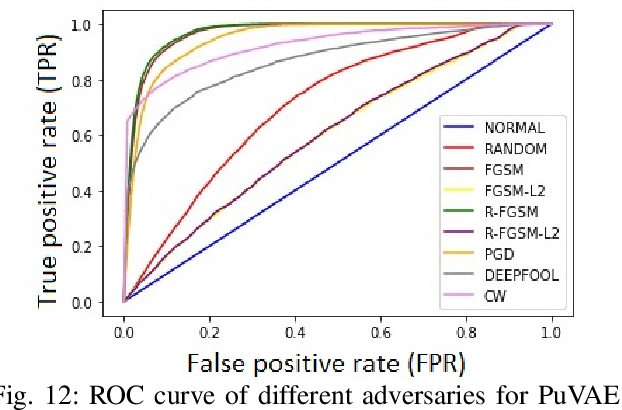
With the rapid advancement and increased use of deep learning models in image identification, security becomes a major concern to their deployment in safety-critical systems. Since the accuracy and robustness of deep learning models are primarily attributed from the purity of the training samples, therefore the deep learning architectures are often susceptible to adversarial attacks. Adversarial attacks are often obtained by making subtle perturbations to normal images, which are mostly imperceptible to humans, but can seriously confuse the state-of-the-art machine learning models. What is so special in the slightest intelligent perturbations or noise additions over normal images that it leads to catastrophic classifications by the deep neural networks? Using statistical hypothesis testing, we find that Conditional Variational AutoEncoders (CVAE) are surprisingly good at detecting imperceptible image perturbations. In this paper, we show how CVAEs can be effectively used to detect adversarial attacks on image classification networks. We demonstrate our results over MNIST, CIFAR-10 dataset and show how our method gives comparable performance to the state-of-the-art methods in detecting adversaries while not getting confused with noisy images, where most of the existing methods falter.