 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealing the Invisible: Unveiling Pre-Trained CNN Models through Adversarial Examples and Timing Side-Channels
Feb 19, 2024Machine learning, with its myriad applications, has become an integral component of numerous technological systems. A common practice in this domain is the use of transfer learning, where a pre-trained model's architecture, readily available to the public, is fine-tuned to suit specific tasks. As Machine Learning as a Service (MLaaS) platforms increasingly use pre-trained models in their backends, it's crucial to safeguard these architectures and understand their vulnerabilities. In this work, we present an approach based on the observation that the classification patterns of adversarial images can be used as a means to steal the models. Furthermore, the adversarial image classifications in conjunction with timing side channels can lead to a model stealing method. Our approach, designed for typical user-level access in remote MLaaS environments exploits varying misclassifications of adversarial images across different models to fingerprint several renowned Convolutional Neural Network (CNN) and Vision Transformer (ViT) architectures. We utilize the profiling of remote model inference times to reduce the necessary adversarial images, subsequently decreasing the number of queries required. We have presented our results over 27 pre-trained models of different CNN and ViT architectures using CIFAR-10 dataset and demonstrate a high accuracy of 88.8% while keeping the query budget under 20.
Resisting Adversarial Attacks in Deep Neural Networks using Diverse Decision Boundaries
Aug 18, 2022


The security of deep learning (DL) systems is an extremely important field of study as they are being deployed in several applications due to their ever-improving performance to solve challenging tasks. Despite overwhelming promises, the deep learning systems are vulnerable to crafted adversarial examples, which may be imperceptible to the human eye, but can lead the model to misclassify. Protections against adversarial perturbations on ensemble-based techniques have either been shown to be vulnerable to stronger adversaries or shown to lack an end-to-end evaluation. In this paper, we attempt to develop a new ensemble-based solution that constructs defender models with diverse decision boundaries with respect to the original model. The ensemble of classifiers constructed by (1) transformation of the input by a method called Split-and-Shuffle, and (2) restricting the significant features by a method called Contrast-Significant-Features are shown to result in diverse gradients with respect to adversarial attacks, which reduces the chance of transferring adversarial examples from the original to the defender model targeting the same class. We present extensive experimentations using standard image classification datasets, namely MNIST, CIFAR-10 and CIFAR-100 against state-of-the-art adversarial attacks to demonstrate the robustness of the proposed ensemble-based defense. We also evaluate the robustness in the presence of a stronger adversary targeting all the models within the ensemble simultaneously. Results for the overall false positives and false negatives have been furnished to estimate the overall performance of the proposed methodology.
On the Evaluation of User Privacy in Deep Neural Networks using Timing Side Channel
Aug 03, 2022
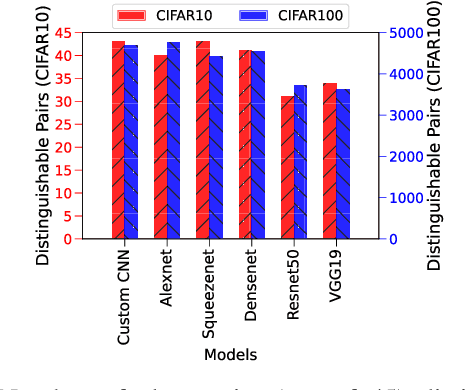
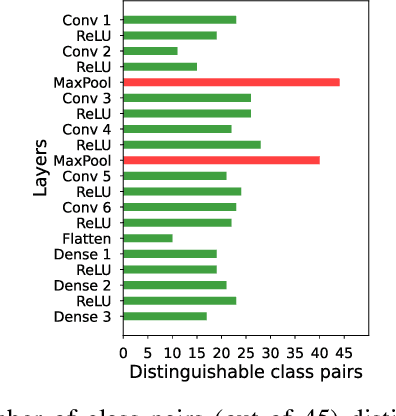

Recent Deep Learning (DL) advancements in solving complex real-world tasks have led to its widespread adoption in practical applications. However, this opportunity comes with significant underlying risks, as many of these models rely on privacy-sensitive data for training in a variety of applications, making them an overly-exposed threat surface for privacy violations. Furthermore, the widespread use of cloud-based Machine-Learning-as-a-Service (MLaaS) for its robust infrastructure support has broadened the threat surface to include a variety of remote side-channel attacks. In this paper, we first identify and report a novel data-dependent timing side-channel leakage (termed Class Leakage) in DL implementations originating from non-constant time branching operation in a widely used DL framework PyTorch. We further demonstrate a practical inference-time attack where an adversary with user privilege and hard-label black-box access to an MLaaS can exploit Class Leakage to compromise the privacy of MLaaS users. DL models are vulnerable to Membership Inference Attack (MIA), where an adversary's objective is to deduce whether any particular data has been used while training the model. In this paper, as a separate case study, we demonstrate that a DL model secured with differential privacy (a popular countermeasure against MIA) is still vulnerable to MIA against an adversary exploiting Class Leakage. We develop an easy-to-implement countermeasure by making a constant-time branching operation that alleviates the Class Leakage and also aids in mitigating MIA. We have chosen two standard benchmarking image classification datasets, CIFAR-10 and CIFAR-100 to train five state-of-the-art pre-trained DL models, over two different computing environments having Intel Xeon and Intel i7 processors to validate our approach.
PARL: Enhancing Diversity of Ensemble Networks to Resist Adversarial Attacks via Pairwise Adversarially Robust Loss Function
Dec 09, 2021
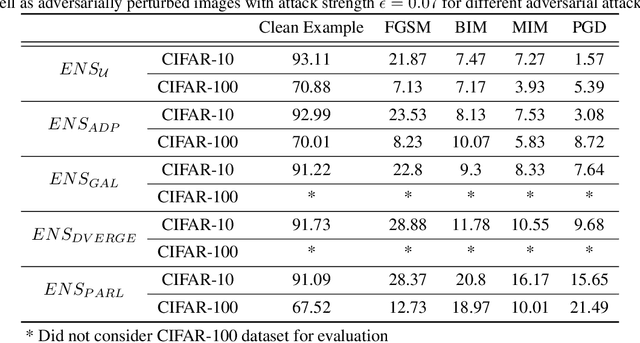
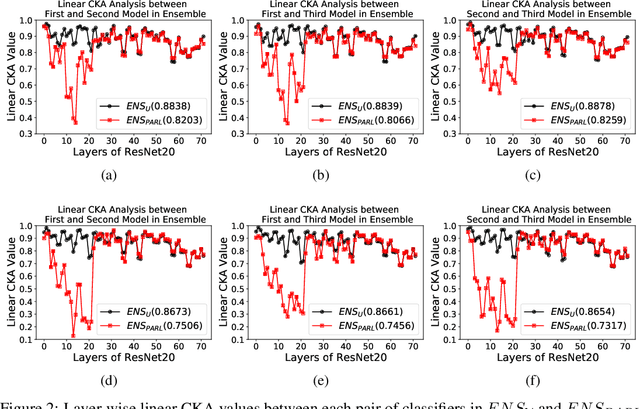

The security of Deep Learning classifiers is a critical field of study because of the existence of adversarial attacks. Such attacks usually rely on the principle of transferability, where an adversarial example crafted on a surrogate classifier tends to mislead the target classifier trained on the same dataset even if both classifiers have quite different architecture. Ensemble methods against adversarial attacks demonstrate that an adversarial example is less likely to mislead multiple classifiers in an ensemble having diverse decision boundaries. However, recent ensemble methods have either been shown to be vulnerable to stronger adversaries or shown to lack an end-to-end evaluation. This paper attempts to develop a new ensemble methodology that constructs multiple diverse classifiers using a Pairwise Adversarially Robust Loss (PARL) function during the training procedure. PARL utilizes gradients of each layer with respect to input in every classifier within the ensemble simultaneously. The proposed training procedure enables PARL to achieve higher robustness against black-box transfer attacks compared to previous ensemble methods without adversely affecting the accuracy of clean examples. We also evaluate the robustness in the presence of white-box attacks, where adversarial examples are crafted using parameters of the target classifier. We present extensive experiments using standard image classification datasets like CIFAR-10 and CIFAR-100 trained using standard ResNet20 classifier against state-of-the-art adversarial attacks to demonstrate the robustness of the proposed ensemble methodology.
Deep-Lock: Secure Authorization for Deep Neural Networks
Aug 13, 2020
Trained Deep Neural Network (DNN) models are considered valuable Intellectual Properties (IP) in several business models. Prevention of IP theft and unauthorized usage of such DNN models has been raised as of significant concern by industry. In this paper, we address the problem of preventing unauthorized usage of DNN models by proposing a generic and lightweight key-based model-locking scheme, which ensures that a locked model functions correctly only upon applying the correct secret key. The proposed scheme, known as Deep-Lock, utilizes S-Boxes with good security properties to encrypt each parameter of a trained DNN model with secret keys generated from a master key via a key scheduling algorithm. The resulting dense network of encrypted weights is found robust against model fine-tuning attacks. Finally, Deep-Lock does not require any intervention in the structure and training of the DNN models, making it applicable for all existing software and hardware implementations of DNN.
Enhancing Fault Tolerance of Neural Networks for Security-Critical Applications
Feb 05, 2019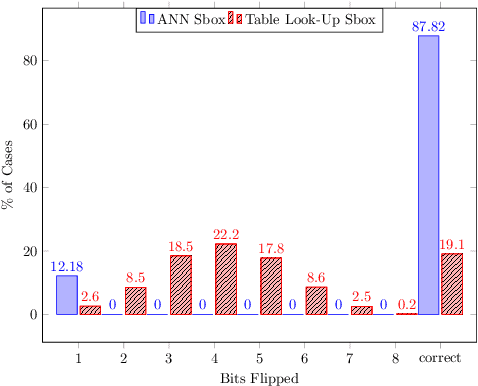

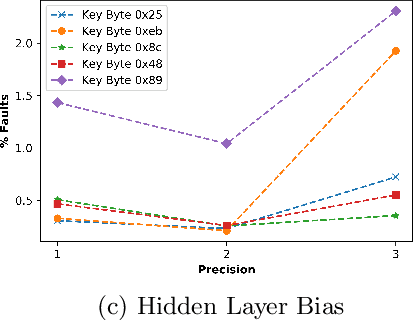
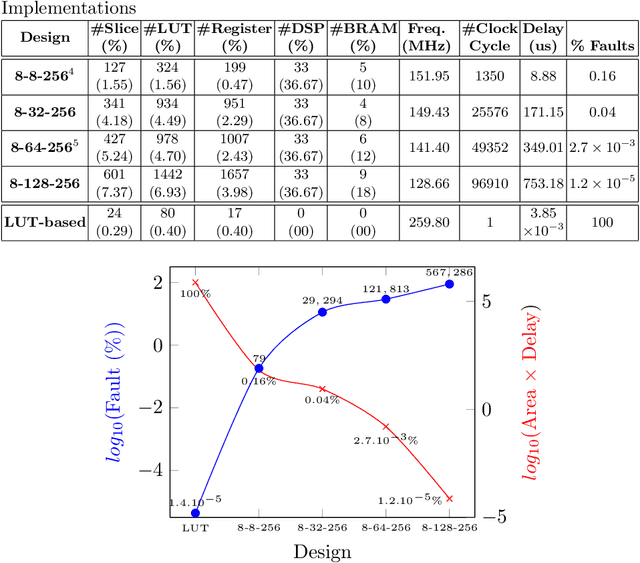
Neural Networks (NN) have recently emerged as backbone of several sensitive applications like automobile, medical image, security, etc. NNs inherently offer Partial Fault Tolerance (PFT) in their architecture; however, the biased PFT of NNs can lead to severe consequences in applications like cryptography and security critical scenarios. In this paper, we propose a revised implementation which enhances the PFT property of NN significantly with detailed mathematical analysis. We evaluated the performance of revised NN considering both software and FPGA implementation for a cryptographic primitive like AES SBox. The results show that the PFT of NNs can be significantly increased with the proposed methodology.
How Secure are Deep Learning Algorithms from Side-Channel based Reverse Engineering?
Nov 13, 2018
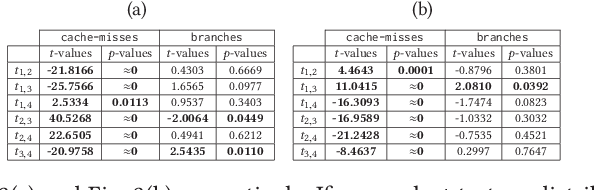
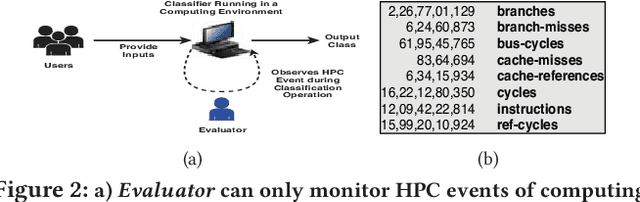

Deep Learning algorithms have recently become the de-facto paradigm for various prediction problems, which include many privacy-preserving applications like online medical image analysis. Presumably, the privacy of data in a deep learning system is a serious concern. There have been several efforts to analyze and exploit the information leakages from deep learning architectures to compromise data privacy. In this paper, however, we attempt to provide an evaluation strategy for such information leakages through deep neural network architectures by considering a case study on Convolutional Neural Network (CNN) based image classifier. The approach takes the aid of low-level hardware information, provided by Hardware Performance Counters (HPCs), during the execution of a CNN classifier and a simple hypothesis testing in order to produce an alarm if there exists any information leakage on the actual input.
Adversarial Attacks and Defences: A Survey
Sep 28, 2018
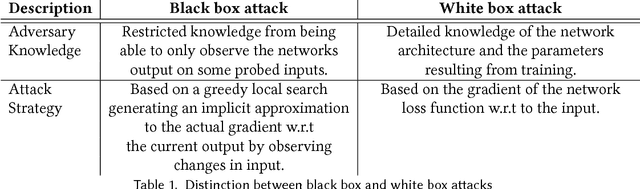


Deep learning has emerged as a strong and efficient framework that can be applied to a broad spectrum of complex learning problems which were difficult to solve using the traditional machine learning techniques in the past. In the last few years, deep learning has advanced radically in such a way that it can surpass human-level performance on a number of tasks. As a consequence, deep learning is being extensively used in most of the recent day-to-day applications. However, security of deep learning systems are vulnerable to crafted adversarial examples, which may be imperceptible to the human eye, but can lead the model to misclassify the output. In recent times, different types of adversaries based on their threat model leverage these vulnerabilities to compromise a deep learning system where adversaries have high incentives. Hence, it is extremely important to provide robustness to deep learning algorithms against these adversaries. However, there are only a few strong countermeasures which can be used in all types of attack scenarios to design a robust deep learning system. In this paper, we attempt to provide a detailed discussion on different types of adversarial attacks with various threat models and also elaborate the efficiency and challenges of recent countermeasures against them.