 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Contractive and High-Quality Denoisers for Convergent Restoration
Mar 27, 2026Image restoration, the recovery of clean images from degraded measurements, has applications in various domains like surveillance, defense, and medical imaging. Despite achieving state-of-the-art (SOTA) restoration performance, existing convolutional and attention-based networks lack stability guarantees under minor shifts in input, exposing a robustness accuracy trade-off. We develop provably contractive (global Lipschitz $< 1$) denoiser networks that considerably reduce this gap. Our design composes proximal layers obtained from unfolding techniques, with Lipschitz-controlled convolutional refinements. By contractivity, our denoiser guarantees that input perturbations of strength $\|δ\|\le\varepsilon$ induce at most $\varepsilon$ change at the output, while strong baselines such as DnCNN and Restormer can exhibit larger deviations under the same perturbations. On image denoising, the proposed model is competitive with unconstrained SOTA denoisers, reporting the tightest gap for a provably 1-Lipschitz model and establishing that such gaps are indeed achievable by contractive denoisers. Moreover, the proposed denoisers act as strong regularizers for image restoration that provably effect convergence in Plug-and-Play algorithms. Our results show that enforcing strict Lipschitz control does not inherently degrade output quality, challenging a common assumption in the literature and moving the field toward verifiable and stable vision models. Codes and pretrained models are available at https://github.com/SHUBHI1553/Contractive-Denoisers
Stealing the Invisible: Unveiling Pre-Trained CNN Models through Adversarial Examples and Timing Side-Channels
Feb 19, 2024Machine learning, with its myriad applications, has become an integral component of numerous technological systems. A common practice in this domain is the use of transfer learning, where a pre-trained model's architecture, readily available to the public, is fine-tuned to suit specific tasks. As Machine Learning as a Service (MLaaS) platforms increasingly use pre-trained models in their backends, it's crucial to safeguard these architectures and understand their vulnerabilities. In this work, we present an approach based on the observation that the classification patterns of adversarial images can be used as a means to steal the models. Furthermore, the adversarial image classifications in conjunction with timing side channels can lead to a model stealing method. Our approach, designed for typical user-level access in remote MLaaS environments exploits varying misclassifications of adversarial images across different models to fingerprint several renowned Convolutional Neural Network (CNN) and Vision Transformer (ViT) architectures. We utilize the profiling of remote model inference times to reduce the necessary adversarial images, subsequently decreasing the number of queries required. We have presented our results over 27 pre-trained models of different CNN and ViT architectures using CIFAR-10 dataset and demonstrate a high accuracy of 88.8% while keeping the query budget under 20.
On the Evaluation of User Privacy in Deep Neural Networks using Timing Side Channel
Aug 03, 2022
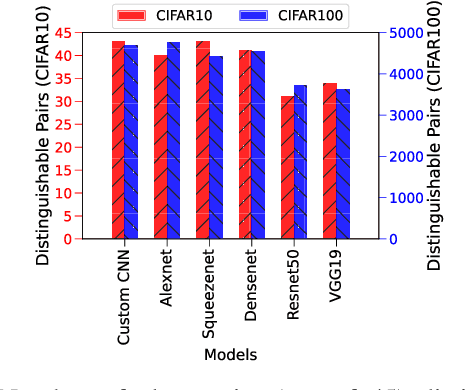
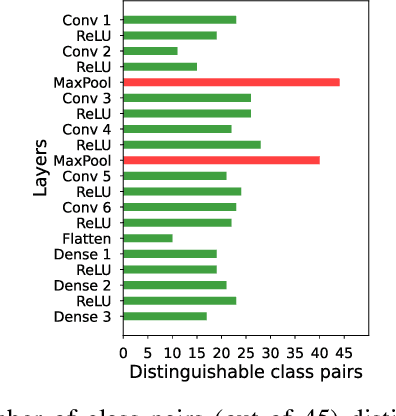

Recent Deep Learning (DL) advancements in solving complex real-world tasks have led to its widespread adoption in practical applications. However, this opportunity comes with significant underlying risks, as many of these models rely on privacy-sensitive data for training in a variety of applications, making them an overly-exposed threat surface for privacy violations. Furthermore, the widespread use of cloud-based Machine-Learning-as-a-Service (MLaaS) for its robust infrastructure support has broadened the threat surface to include a variety of remote side-channel attacks. In this paper, we first identify and report a novel data-dependent timing side-channel leakage (termed Class Leakage) in DL implementations originating from non-constant time branching operation in a widely used DL framework PyTorch. We further demonstrate a practical inference-time attack where an adversary with user privilege and hard-label black-box access to an MLaaS can exploit Class Leakage to compromise the privacy of MLaaS users. DL models are vulnerable to Membership Inference Attack (MIA), where an adversary's objective is to deduce whether any particular data has been used while training the model. In this paper, as a separate case study, we demonstrate that a DL model secured with differential privacy (a popular countermeasure against MIA) is still vulnerable to MIA against an adversary exploiting Class Leakage. We develop an easy-to-implement countermeasure by making a constant-time branching operation that alleviates the Class Leakage and also aids in mitigating MIA. We have chosen two standard benchmarking image classification datasets, CIFAR-10 and CIFAR-100 to train five state-of-the-art pre-trained DL models, over two different computing environments having Intel Xeon and Intel i7 processors to validate our approach.