 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Ranked List Truncation for Reranking Pipelines via LLM-generated Reference-Documents
Apr 10, 2026Large Language Models (LLM) have been widely used in reranking. Computational overhead and large context lengths remain a challenging issue for LLM rerankers. Efficient reranking usually involves selecting a subset of the ranked list from the first stage, known as ranked list truncation (RLT). The truncated list is processed further by a reranker. For LLM rerankers, the ranked list is often partitioned and processed sequentially in batches to reduce the context length. Both these steps involve hyperparameters and topic-agnostic heuristics. Recently, LLMs have been shown to be effective for relevance judgment. Equivalently, we propose that LLMs can be used to generate reference documents that can act as a pivot between relevant and non-relevant documents in a ranked list. We propose methods to use these generated reference documents for RLT as well as for efficient listwise reranking. While reranking, we process the ranked list in either parallel batches of non-overlapping windows or overlapping windows with adaptive strides, improving the existing fixed stride setup. The generated reference documents are also shown to improve existing efficient listwise reranking frameworks. Experiments on TREC Deep Learning benchmarks show that our approach outperforms existing RLT-based approaches. In-domain and out-of-domain benchmarks demonstrate that our proposed methods accelerate LLM-based listwise reranking by up to 66\% compared to existing approaches. This work not only establishes a practical paradigm for efficient LLM-based reranking but also provides insight into the capability of LLMs to generate semantically controlled documents using relevance signals.
Beyond CLIP: Knowledge-Enhanced Multimodal Transformers for Cross-Modal Alignment in Diabetic Retinopathy Diagnosis
Dec 22, 2025Diabetic retinopathy (DR) is a leading cause of preventable blindness worldwide, demanding accurate automated diagnostic systems. While general-domain vision-language models like Contrastive Language-Image Pre-Training (CLIP) perform well on natural image tasks, they struggle in medical domain applications, particularly in cross-modal retrieval for ophthalmological images. We propose a novel knowledge-enhanced joint embedding framework that integrates retinal fundus images, clinical text, and structured patient data through a multimodal transformer architecture to address the critical gap in medical image-text alignment. Our approach employs separate encoders for each modality: a Vision Transformer (ViT-B/16) for retinal images, Bio-ClinicalBERT for clinical narratives, and a multilayer perceptron for structured demographic and clinical features. These modalities are fused through a joint transformer with modality-specific embeddings, trained using multiple objectives including contrastive losses between modality pairs, reconstruction losses for images and text, and classification losses for DR severity grading according to ICDR and SDRG schemes. Experimental results on the Brazilian Multilabel Ophthalmological Dataset (BRSET) demonstrate significant improvements over baseline models. Our framework achieves near-perfect text-to-image retrieval performance with Recall@1 of 99.94% compared to fine-tuned CLIP's 1.29%, while maintaining state-of-the-art classification accuracy of 97.05% for SDRG and 97.97% for ICDR. Furthermore, zero-shot evaluation on the unseen DeepEyeNet dataset validates strong generalizability with 93.95% Recall@1 versus 0.22% for fine-tuned CLIP. These results demonstrate that our multimodal training approach effectively captures cross-modal relationships in the medical domain, establishing both superior retrieval capabilities and robust diagnostic performance.
Modeling Ranking Properties with In-Context Learning
May 23, 2025While standard IR models are mainly designed to optimize relevance, real-world search often needs to balance additional objectives such as diversity and fairness. These objectives depend on inter-document interactions and are commonly addressed using post-hoc heuristics or supervised learning methods, which require task-specific training for each ranking scenario and dataset. In this work, we propose an in-context learning (ICL) approach that eliminates the need for such training. Instead, our method relies on a small number of example rankings that demonstrate the desired trade-offs between objectives for past queries similar to the current input. We evaluate our approach on four IR test collections to investigate multiple auxiliary objectives: group fairness (TREC Fairness), polarity diversity (Touch\'e), and topical diversity (TREC Deep Learning 2019/2020). We empirically validate that our method enables control over ranking behavior through demonstration engineering, allowing nuanced behavioral adjustments without explicit optimization.
MorCode: Face Morphing Attack Generation using Generative Codebooks
Oct 10, 2024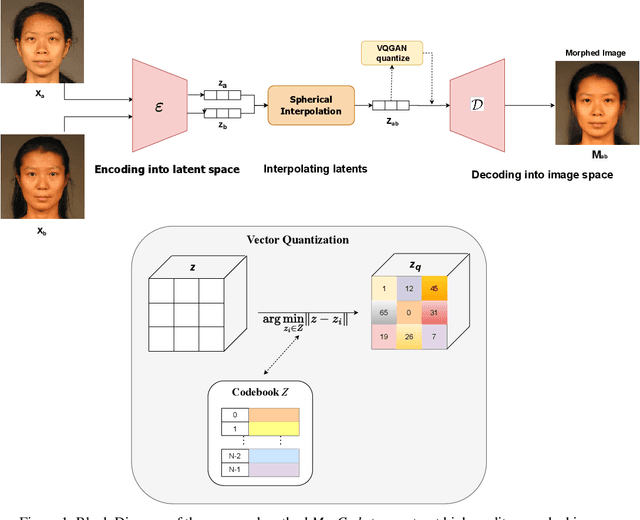
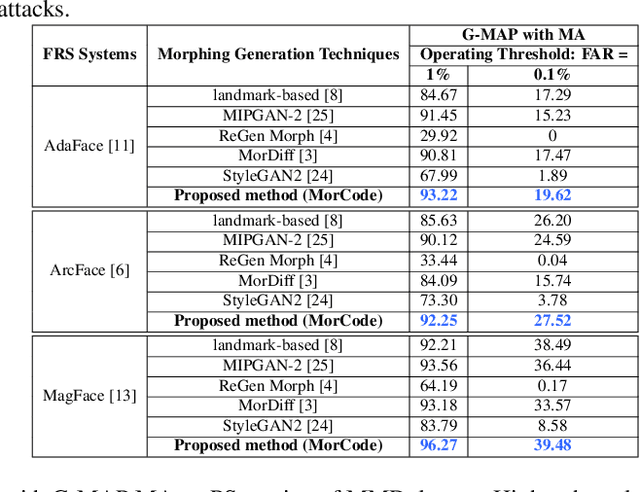

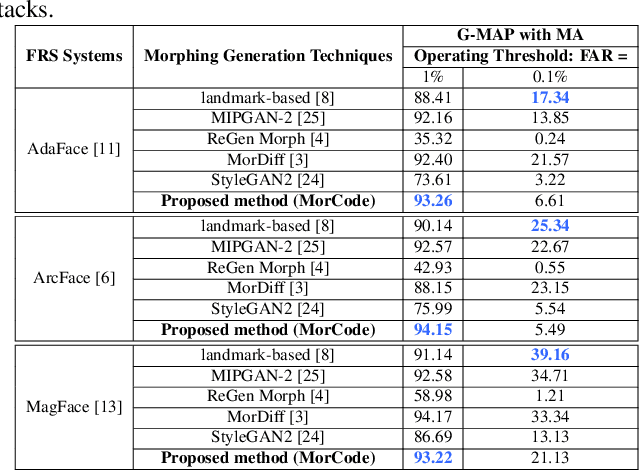
Face recognition systems (FRS) can be compromised by face morphing attacks, which blend textural and geometric information from multiple facial images. The rapid evolution of generative AI, especially Generative Adversarial Networks (GAN) or Diffusion models, where encoded images are interpolated to generate high-quality face morphing images. In this work, we present a novel method for the automatic face morphing generation method \textit{MorCode}, which leverages a contemporary encoder-decoder architecture conditioned on codebook learning to generate high-quality morphing images. Extensive experiments were performed on the newly constructed morphing dataset using five state-of-the-art morphing generation techniques using both digital and print-scan data. The attack potential of the proposed morphing generation technique, \textit{MorCode}, was benchmarked using three different face recognition systems. The obtained results indicate the highest attack potential of the proposed \textit{MorCode} when compared with five state-of-the-art morphing generation methods on both digital and print scan data.
Few-shot Pairwise Rank Prompting: An Effective Non-Parametric Retrieval Model
Sep 27, 2024A supervised ranking model, despite its advantage of being effective, usually involves complex processing - typically multiple stages of task-specific pre-training and fine-tuning. This has motivated researchers to explore simpler pipelines leveraging large language models (LLMs) that are capable of working in a zero-shot manner. However, since zero-shot inference does not make use of a training set of pairs of queries and their relevant documents, its performance is mostly worse than that of supervised models, which are trained on such example pairs. Motivated by the existing findings that training examples generally improve zero-shot performance, in our work, we explore if this also applies to ranking models. More specifically, given a query and a pair of documents, the preference prediction task is improved by augmenting examples of preferences for similar queries from a training set. Our proposed pairwise few-shot ranker demonstrates consistent improvements over the zero-shot baseline on both in-domain (TREC DL) and out-domain (BEIR subset) retrieval benchmarks. Our method also achieves a close performance to that of a supervised model without requiring any complex training pipeline.
NeuralMultiling: A Novel Neural Architecture Search for Smartphone based Multilingual Speaker Verification
Aug 08, 2024



Multilingual speaker verification introduces the challenge of verifying a speaker in multiple languages. Existing systems were built using i-vector/x-vector approaches along with Bi-LSTMs, which were trained to discriminate speakers, irrespective of the language. Instead of exploring the design space manually, we propose a neural architecture search for multilingual speaker verification suitable for mobile devices, called \textbf{NeuralMultiling}. First, our algorithm searches for an optimal operational combination of neural cells with different architectures for normal cells and reduction cells and then derives a CNN model by stacking neural cells. Using the derived architecture, we performed two different studies:1) language agnostic condition and 2) interoperability between languages and devices on the publicly available Multilingual Audio-Visual Smartphone (MAVS) dataset. The experimental results suggest that the derived architecture significantly outperforms the existing Autospeech method by a 5-6\% reduction in the Equal Error Rate (EER) with fewer model parameters.
Straight Through Gumbel Softmax Estimator based Bimodal Neural Architecture Search for Audio-Visual Deepfake Detection
Jun 19, 2024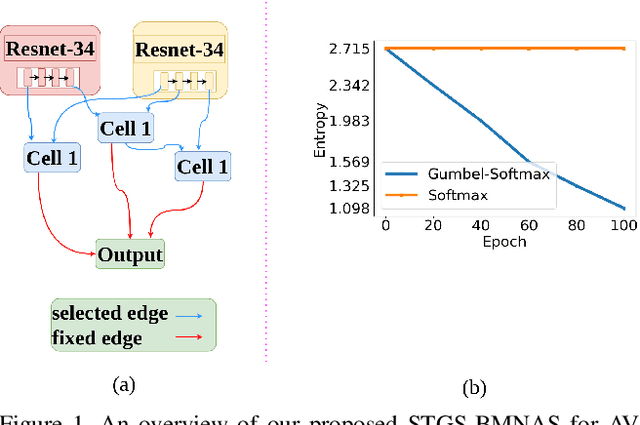

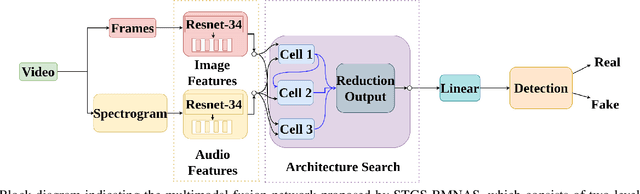
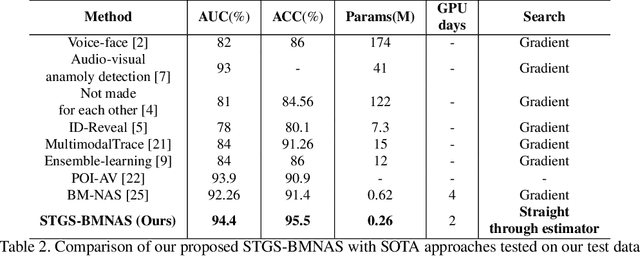
Deepfakes are a major security risk for biometric authentication. This technology creates realistic fake videos that can impersonate real people, fooling systems that rely on facial features and voice patterns for identification. Existing multimodal deepfake detectors rely on conventional fusion methods, such as majority rule and ensemble voting, which often struggle to adapt to changing data characteristics and complex patterns. In this paper, we introduce the Straight-through Gumbel-Softmax (STGS) framework, offering a comprehensive approach to search multimodal fusion model architectures. Using a two-level search approach, the framework optimizes the network architecture, parameters, and performance. Initially, crucial features were efficiently identified from backbone networks, whereas within the cell structure, a weighted fusion operation integrated information from various sources. An architecture that maximizes the classification performance is derived by varying parameters such as temperature and sampling time. The experimental results on the FakeAVCeleb and SWAN-DF datasets demonstrated an impressive AUC value 94.4\% achieved with minimal model parameters.
MLSD-GAN -- Generating Strong High Quality Face Morphing Attacks using Latent Semantic Disentanglement
Apr 19, 2024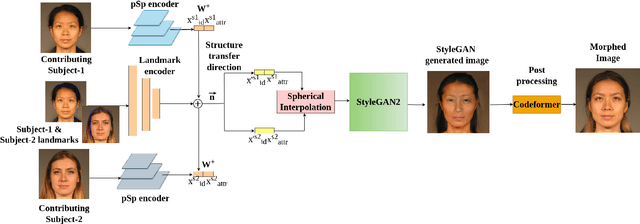

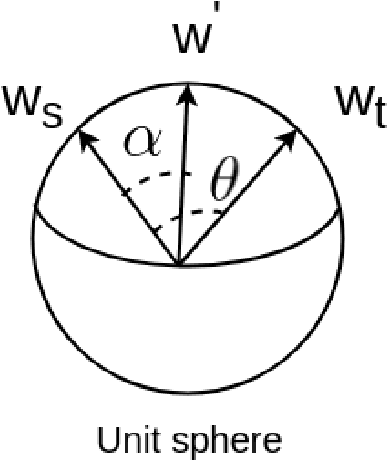
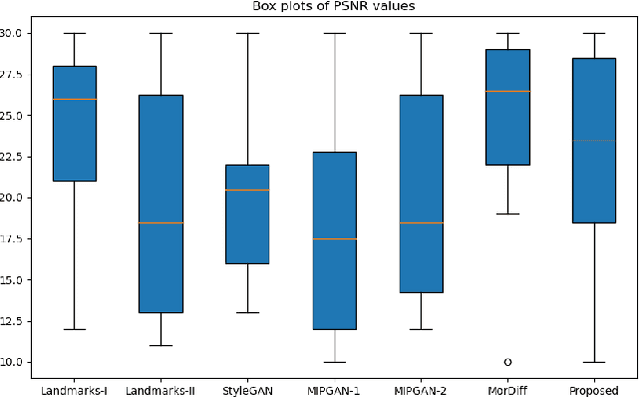
Face-morphing attacks are a growing concern for biometric researchers, as they can be used to fool face recognition systems (FRS). These attacks can be generated at the image level (supervised) or representation level (unsupervised). Previous unsupervised morphing attacks have relied on generative adversarial networks (GANs). More recently, researchers have used linear interpolation of StyleGAN-encoded images to generate morphing attacks. In this paper, we propose a new method for generating high-quality morphing attacks using StyleGAN disentanglement. Our approach, called MLSD-GAN, spherically interpolates the disentangled latents to produce realistic and diverse morphing attacks. We evaluate the vulnerability of MLSD-GAN on two deep-learning-based FRS techniques. The results show that MLSD-GAN poses a significant threat to FRS, as it can generate morphing attacks that are highly effective at fooling these systems.
Graph Expansion in Pruned Recurrent Neural Network Layers Preserve Performance
Mar 17, 2024
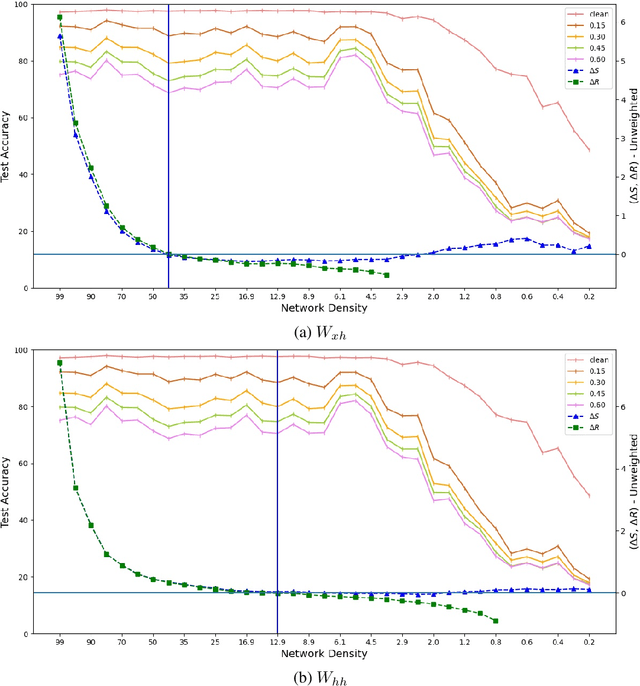
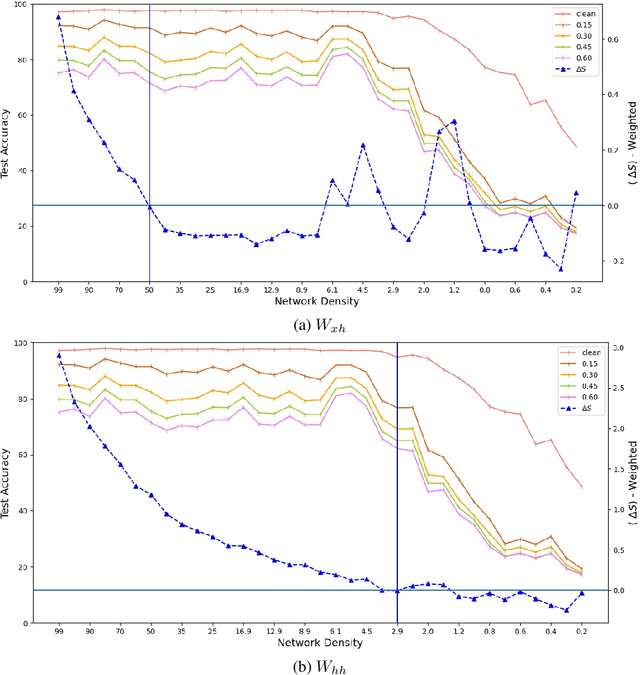
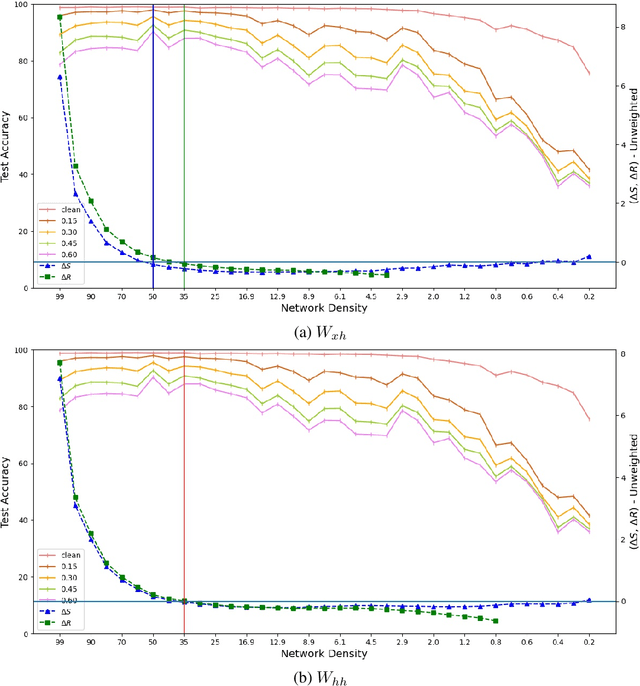
Expansion property of a graph refers to its strong connectivity as well as sparseness. It has been reported that deep neural networks can be pruned to a high degree of sparsity while maintaining their performance. Such pruning is essential for performing real time sequence learning tasks using recurrent neural networks in resource constrained platforms. We prune recurrent networks such as RNNs and LSTMs, maintaining a large spectral gap of the underlying graphs and ensuring their layerwise expansion properties. We also study the time unfolded recurrent network graphs in terms of the properties of their bipartite layers. Experimental results for the benchmark sequence MNIST, CIFAR-10, and Google speech command data show that expander graph properties are key to preserving classification accuracy of RNN and LSTM.
Stealing the Invisible: Unveiling Pre-Trained CNN Models through Adversarial Examples and Timing Side-Channels
Feb 19, 2024Machine learning, with its myriad applications, has become an integral component of numerous technological systems. A common practice in this domain is the use of transfer learning, where a pre-trained model's architecture, readily available to the public, is fine-tuned to suit specific tasks. As Machine Learning as a Service (MLaaS) platforms increasingly use pre-trained models in their backends, it's crucial to safeguard these architectures and understand their vulnerabilities. In this work, we present an approach based on the observation that the classification patterns of adversarial images can be used as a means to steal the models. Furthermore, the adversarial image classifications in conjunction with timing side channels can lead to a model stealing method. Our approach, designed for typical user-level access in remote MLaaS environments exploits varying misclassifications of adversarial images across different models to fingerprint several renowned Convolutional Neural Network (CNN) and Vision Transformer (ViT) architectures. We utilize the profiling of remote model inference times to reduce the necessary adversarial images, subsequently decreasing the number of queries required. We have presented our results over 27 pre-trained models of different CNN and ViT architectures using CIFAR-10 dataset and demonstrate a high accuracy of 88.8% while keeping the query budget under 20.