 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralMultiling: A Novel Neural Architecture Search for Smartphone based Multilingual Speaker Verification
Aug 08, 2024



Multilingual speaker verification introduces the challenge of verifying a speaker in multiple languages. Existing systems were built using i-vector/x-vector approaches along with Bi-LSTMs, which were trained to discriminate speakers, irrespective of the language. Instead of exploring the design space manually, we propose a neural architecture search for multilingual speaker verification suitable for mobile devices, called \textbf{NeuralMultiling}. First, our algorithm searches for an optimal operational combination of neural cells with different architectures for normal cells and reduction cells and then derives a CNN model by stacking neural cells. Using the derived architecture, we performed two different studies:1) language agnostic condition and 2) interoperability between languages and devices on the publicly available Multilingual Audio-Visual Smartphone (MAVS) dataset. The experimental results suggest that the derived architecture significantly outperforms the existing Autospeech method by a 5-6\% reduction in the Equal Error Rate (EER) with fewer model parameters.
ExtSwap: Leveraging Extended Latent Mapper for Generating High Quality Face Swapping
Oct 19, 2023



We present a novel face swapping method using the progressively growing structure of a pre-trained StyleGAN. Previous methods use different encoder decoder structures, embedding integration networks to produce high-quality results, but their quality suffers from entangled representation. We disentangle semantics by deriving identity and attribute features separately. By learning to map the concatenated features into the extended latent space, we leverage the state-of-the-art quality and its rich semantic extended latent space. Extensive experiments suggest that the proposed method successfully disentangles identity and attribute features and outperforms many state-of-the-art face swapping methods, both qualitatively and quantitatively.
Melody Extraction from Polyphonic Music by Deep Learning Approaches: A Review
Feb 02, 2022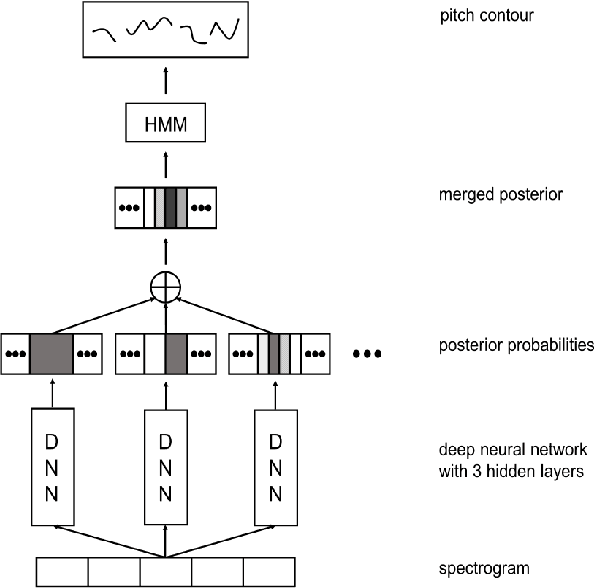
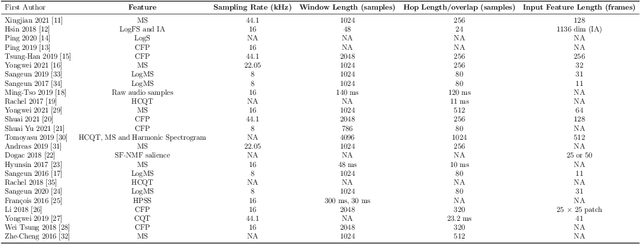
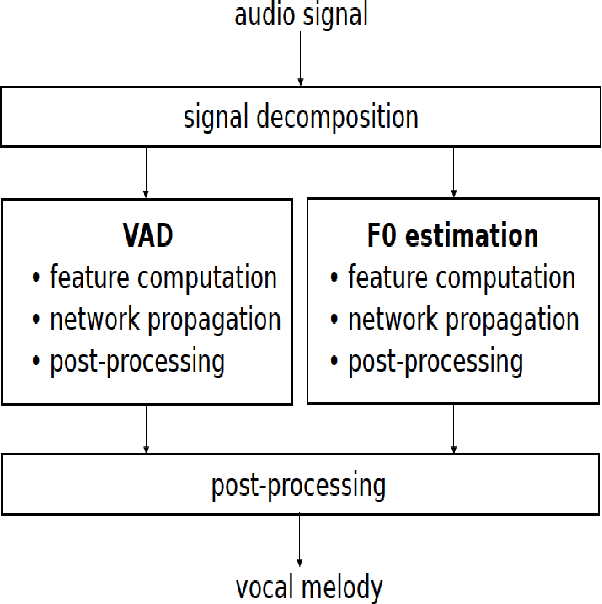
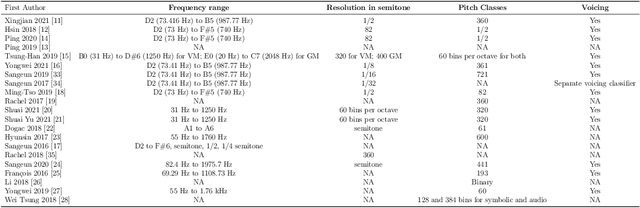
Melody extraction is a vital music information retrieval task among music researchers for its potential applications in education pedagogy and the music industry. Melody extraction is a notoriously challenging task due to the presence of background instruments. Also, often melodic source exhibits similar characteristics to that of the other instruments. The interfering background accompaniment with the vocals makes extracting the melody from the mixture signal much more challenging. Until recently, classical signal processing-based melody extraction methods were quite popular among melody extraction researchers. The ability of the deep learning models to model large-scale data and the ability of the models to learn automatic features by exploiting spatial and temporal dependencies inspired many researchers to adopt deep learning models for melody extraction. In this paper, an attempt has been made to review the up-to-date data-driven deep learning approaches for melody extraction from polyphonic music. The available deep models have been categorized based on the type of neural network used and the output representation they use for predicting melody. Further, the architectures of the 25 melody extraction models are briefly presented. The loss functions used to optimize the model parameters of the melody extraction models are broadly categorized into four categories and briefly describe the loss functions used by various melody extraction models. Also, the various input representations adopted by the melody extraction models and the parameter settings are deeply described. A section describing the explainability of the block-box melody extraction deep neural networks is included. The performance of 25 melody extraction methods is compared. The possible future directions to explore/improve the melody extraction methods are also presented in the paper.