 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Augmentation in CLIP for Improved Anatomy Detection on Multi-modal Medical Images
May 31, 2024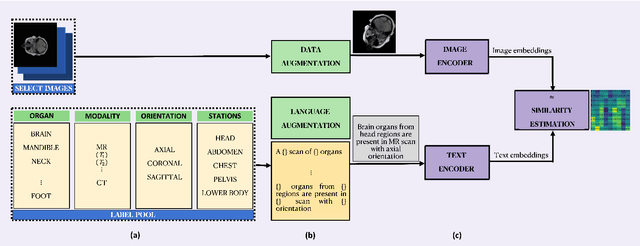
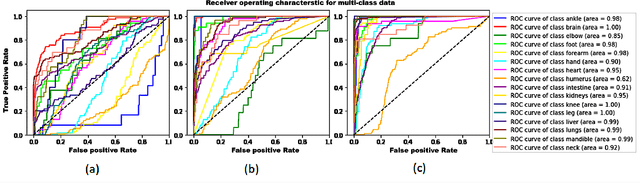
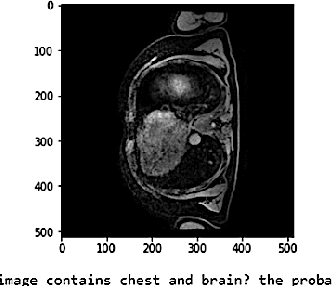
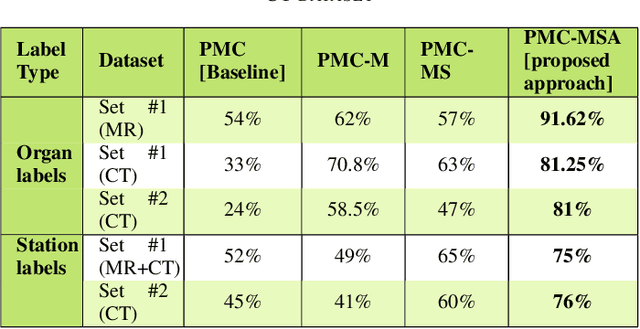
Vision-language models have emerged as a powerful tool for previously challenging multi-modal classification problem in the medical domain. This development has led to the exploration of automated image description generation for multi-modal clinical scans, particularly for radiology report generation. Existing research has focused on clinical descriptions for specific modalities or body regions, leaving a gap for a model providing entire-body multi-modal descriptions. In this paper, we address this gap by automating the generation of standardized body station(s) and list of organ(s) across the whole body in multi-modal MR and CT radiological images. Leveraging the versatility of the Contrastive Language-Image Pre-training (CLIP), we refine and augment the existing approach through multiple experiments, including baseline model fine-tuning, adding station(s) as a superset for better correlation between organs, along with image and language augmentations. Our proposed approach demonstrates 47.6% performance improvement over baseline PubMedCLIP.
One-shot Localization and Segmentation of Medical Images with Foundation Models
Oct 28, 2023



Recent advances in Vision Transformers (ViT) and Stable Diffusion (SD) models with their ability to capture rich semantic features of the image have been used for image correspondence tasks on natural images. In this paper, we examine the ability of a variety of pre-trained ViT (DINO, DINOv2, SAM, CLIP) and SD models, trained exclusively on natural images, for solving the correspondence problems on medical images. While many works have made a case for in-domain training, we show that the models trained on natural images can offer good performance on medical images across different modalities (CT,MR,Ultrasound) sourced from various manufacturers, over multiple anatomical regions (brain, thorax, abdomen, extremities), and on wide variety of tasks. Further, we leverage the correspondence with respect to a template image to prompt a Segment Anything (SAM) model to arrive at single shot segmentation, achieving dice range of 62%-90% across tasks, using just one image as reference. We also show that our single-shot method outperforms the recently proposed few-shot segmentation method - UniverSeg (Dice range 47%-80%) on most of the semantic segmentation tasks(six out of seven) across medical imaging modalities.
Deep Attention-Based Alignment Network for Melody Generation from Incomplete Lyrics
Jan 23, 2023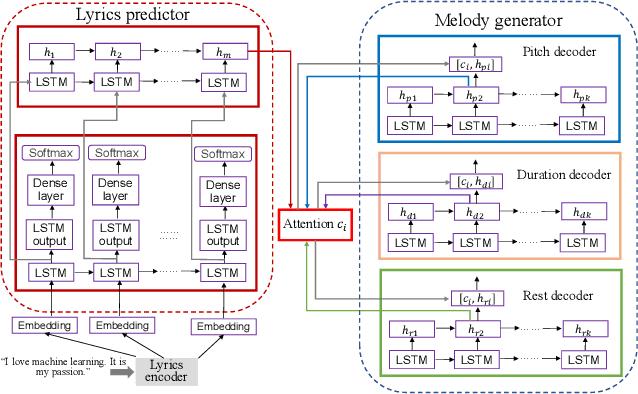
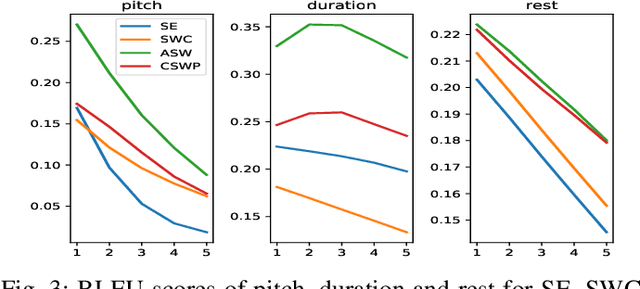
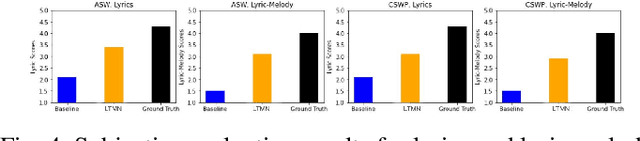
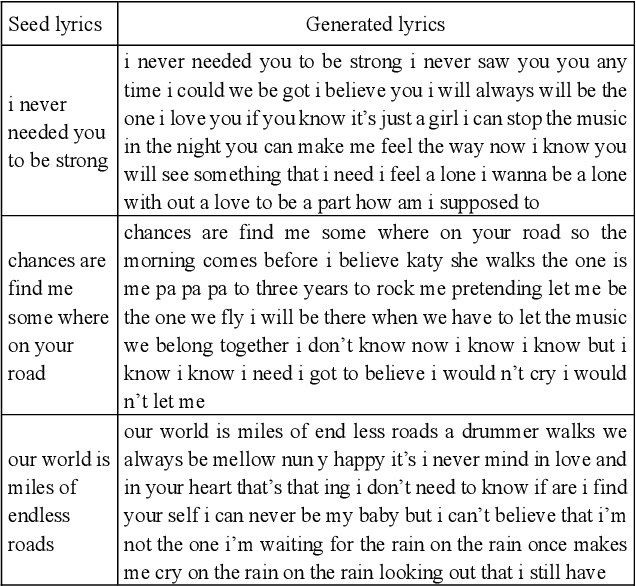
We propose a deep attention-based alignment network, which aims to automatically predict lyrics and melody with given incomplete lyrics as input in a way similar to the music creation of humans. Most importantly, a deep neural lyrics-to-melody net is trained in an encoder-decoder way to predict possible pairs of lyrics-melody when given incomplete lyrics (few keywords). The attention mechanism is exploited to align the predicted lyrics with the melody during the lyrics-to-melody generation. The qualitative and quantitative evaluation metrics reveal that the proposed method is indeed capable of generating proper lyrics and corresponding melody for composing new songs given a piece of incomplete seed lyrics.
Melody Extraction from Polyphonic Music by Deep Learning Approaches: A Review
Feb 02, 2022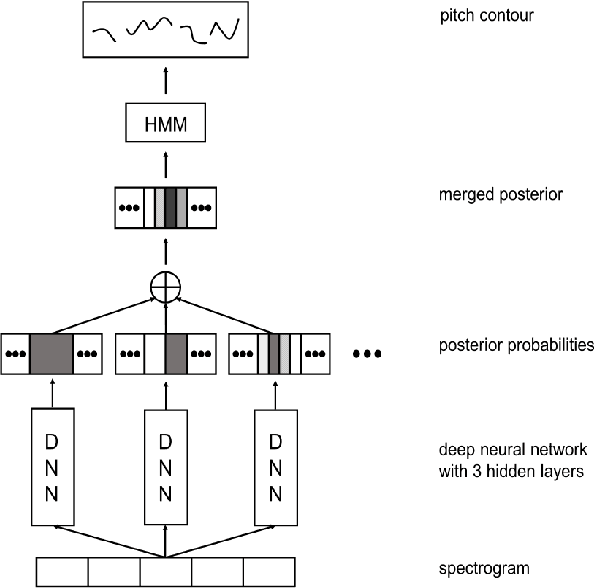
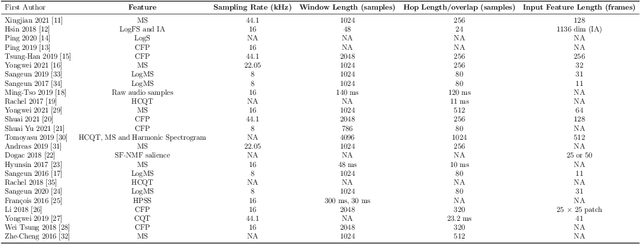
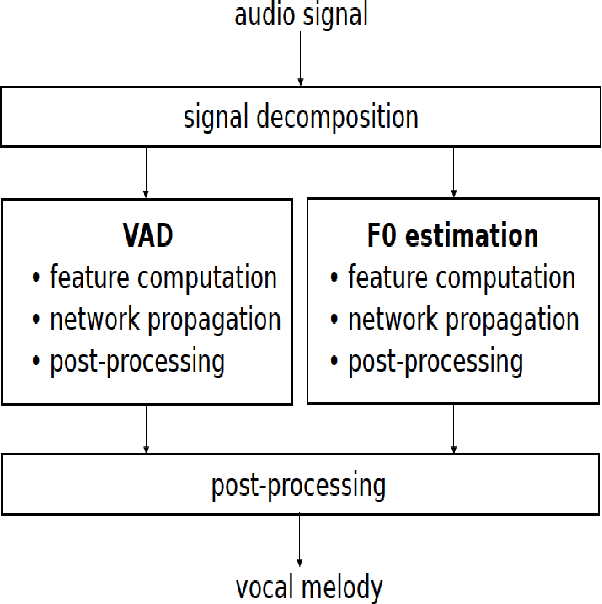
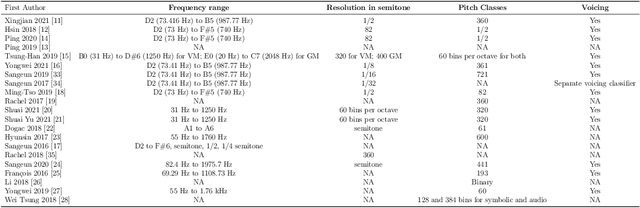
Melody extraction is a vital music information retrieval task among music researchers for its potential applications in education pedagogy and the music industry. Melody extraction is a notoriously challenging task due to the presence of background instruments. Also, often melodic source exhibits similar characteristics to that of the other instruments. The interfering background accompaniment with the vocals makes extracting the melody from the mixture signal much more challenging. Until recently, classical signal processing-based melody extraction methods were quite popular among melody extraction researchers. The ability of the deep learning models to model large-scale data and the ability of the models to learn automatic features by exploiting spatial and temporal dependencies inspired many researchers to adopt deep learning models for melody extraction. In this paper, an attempt has been made to review the up-to-date data-driven deep learning approaches for melody extraction from polyphonic music. The available deep models have been categorized based on the type of neural network used and the output representation they use for predicting melody. Further, the architectures of the 25 melody extraction models are briefly presented. The loss functions used to optimize the model parameters of the melody extraction models are broadly categorized into four categories and briefly describe the loss functions used by various melody extraction models. Also, the various input representations adopted by the melody extraction models and the parameter settings are deeply described. A section describing the explainability of the block-box melody extraction deep neural networks is included. The performance of 25 melody extraction methods is compared. The possible future directions to explore/improve the melody extraction methods are also presented in the paper.
Knowledge Distillation for Singing Voice Detection
Nov 09, 2020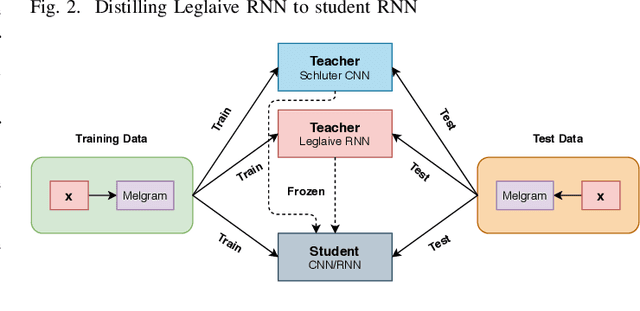
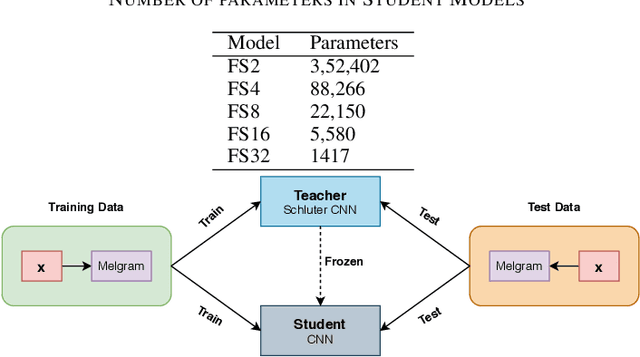
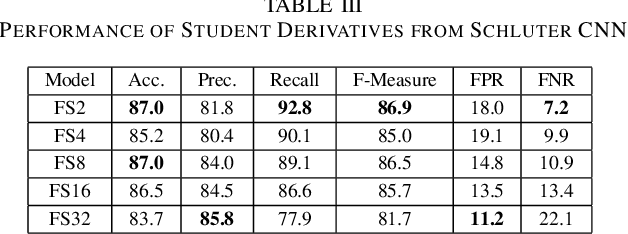
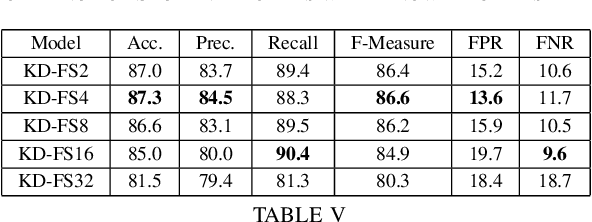
Singing Voice Detection (SVD) has been an active area of research in music information retrieval (MIR). Currently, two deep neural network-based methods, one based on CNN and the other on RNN, exist in literature that learn optimized features for the voice detection (VD) task and achieve state-of-the-art performance on common datasets. Both these models have a huge number of parameters (1.4M for CNN and 65.7K for RNN) and hence not suitable for deployment on devices like smartphones or embedded sensors with limited capacity in terms of memory and computation power. The most popular method to address this issue is known as knowledge distillation in deep learning literature (in addition to model compression) where a large pretrained network known as the teacher is used to train a smaller student network. However, to the best of our knowledge, such methods have not been explored yet in the domain of SVD. In this paper, efforts have been made to investigate this issue using both conventional as well as ensemble knowledge distillation techniques. Through extensive experimentation on the publicly available Jamendo dataset, we show that, not only it's possible to achieve comparable accuracies with far smaller models (upto 1000x smaller in terms of parameters), but fascinatingly, in some cases, smaller models trained with distillation, even surpass the current state-of-the-art models on voice detection performance.
Learning to Recognize Code-switched Speech Without Forgetting Monolingual Speech Recognition
Jun 01, 2020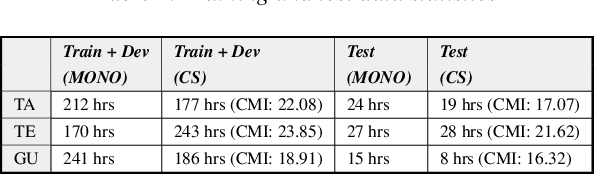
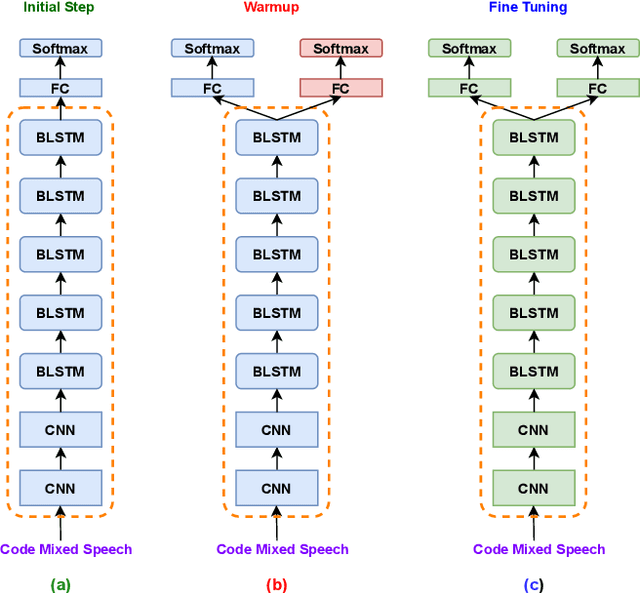
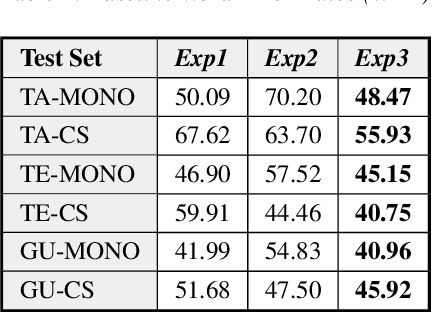
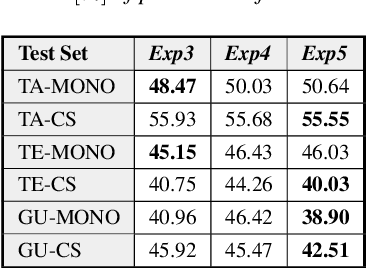
Recently, there has been significant progress made in Automatic Speech Recognition (ASR) of code-switched speech, leading to gains in accuracy on code-switched datasets in many language pairs. Code-switched speech co-occurs with monolingual speech in one or both languages being mixed. In this work, we show that fine-tuning ASR models on code-switched speech harms performance on monolingual speech. We point out the need to optimize models for code-switching while also ensuring that monolingual performance is not sacrificed. Monolingual models may be trained on thousands of hours of speech which may not be available for re-training a new model. We propose using the Learning Without Forgetting (LWF) framework for code-switched ASR when we only have access to a monolingual model and do not have the data it was trained on. We show that it is possible to train models using this framework that perform well on both code-switched and monolingual test sets. In cases where we have access to monolingual training data as well, we propose regularization strategies for fine-tuning models for code-switching without sacrificing monolingual accuracy. We report improvements in Word Error Rate (WER) in monolingual and code-switched test sets compared to baselines that use pooled data and simple fine-tuning.
hf0: A hybrid pitch extraction method for multimodal voice
Apr 22, 2019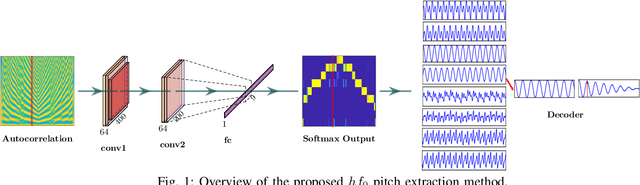
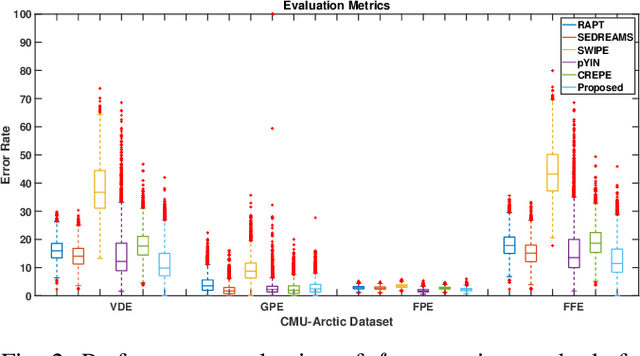
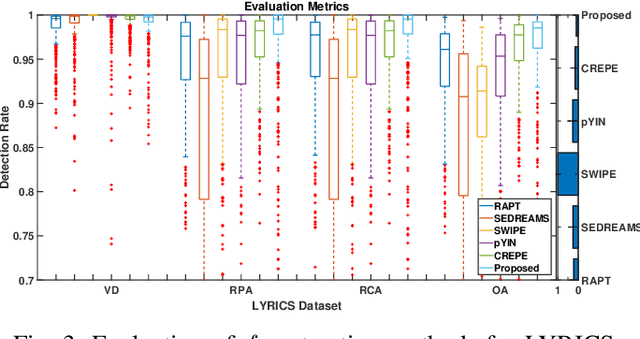

Pitch or fundamental frequency (f0) extraction is a fundamental problem studied extensively for its potential applications in speech and clinical applications. In literature, explicit mode specific (modal speech or singing voice or emotional/ expressive speech or noisy speech) signal processing and deep learning f0 extraction methods that exploit the quasi periodic nature of the signal in time, harmonic property in spectral or combined form to extract the pitch is developed. Hence, there is no single unified method which can reliably extract the pitch from various modes of the acoustic signal. In this work, we propose a hybrid f0 extraction method which seamlessly extracts the pitch across modes of speech production with very high accuracy required for many applications. The proposed hybrid model exploits the advantages of deep learning and signal processing methods to minimize the pitch detection error and adopts to various modes of acoustic signal. Specifically, we propose an ordinal regression convolutional neural networks to map the periodicity rich input representation to obtain the nominal pitch classes which drastically reduces the number of classes required for pitch detection unlike other deep learning approaches. Further, the accurate f0 is estimated from the nominal pitch class labels by filtering and autocorrelation. We show that the proposed method generalizes to the unseen modes of voice production and various noises for large scale datasets. Also, the proposed hybrid model significantly reduces the learning parameters required to train the deep model compared to other methods. Furthermore,the evaluation measures showed that the proposed method is significantly better than the state-of-the-art signal processing and deep learning approaches.
Glottal Closure Instants Detection From Pathological Acoustic Speech Signal Using Deep Learning
Nov 25, 2018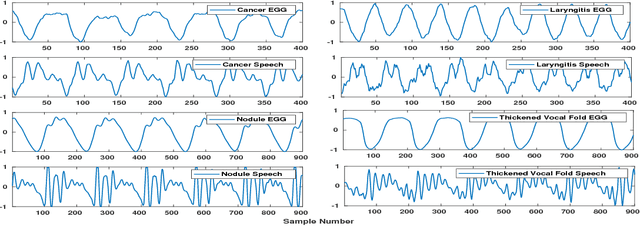

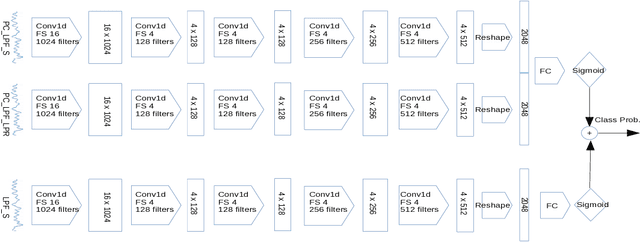
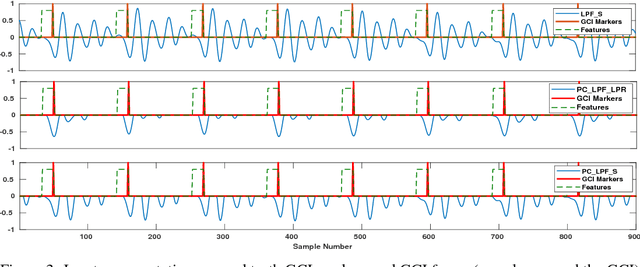
In this paper, we propose a classification based glottal closure instants (GCI) detection from pathological acoustic speech signal, which finds many applications in vocal disorder analysis. Till date, GCI for pathological disorder is extracted from laryngeal (glottal source) signal recorded from Electroglottograph, a dedicated device designed to measure the vocal folds vibration around the larynx. We have created a pathological dataset which consists of simultaneous recordings of glottal source and acoustic speech signal of six different disorders from vocal disordered patients. The GCI locations are manually annotated for disorder analysis and supervised learning. We have proposed convolutional neural network based GCI detection method by fusing deep acoustic speech and linear prediction residual features for robust GCI detection. The experimental results showed that the proposed method is significantly better than the state-of-the-art GCI detection methods.