 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeName That Part: 3D Part Segmentation and Naming
Dec 19, 2025
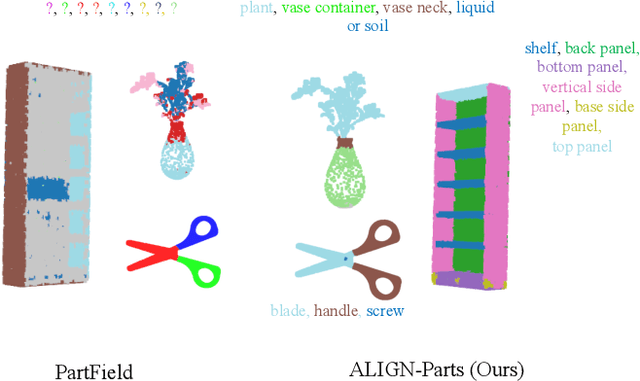

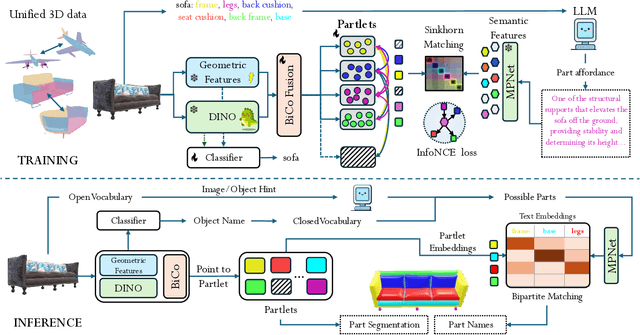
We address semantic 3D part segmentation: decomposing objects into parts with meaningful names. While datasets exist with part annotations, their definitions are inconsistent across datasets, limiting robust training. Previous methods produce unlabeled decompositions or retrieve single parts without complete shape annotations. We propose ALIGN-Parts, which formulates part naming as a direct set alignment task. Our method decomposes shapes into partlets - implicit 3D part representations - matched to part descriptions via bipartite assignment. We combine geometric cues from 3D part fields, appearance from multi-view vision features, and semantic knowledge from language-model-generated affordance descriptions. Text-alignment loss ensures partlets share embedding space with text, enabling a theoretically open-vocabulary matching setup, given sufficient data. Our efficient and novel, one-shot, 3D part segmentation and naming method finds applications in several downstream tasks, including serving as a scalable annotation engine. As our model supports zero-shot matching to arbitrary descriptions and confidence-calibrated predictions for known categories, with human verification, we create a unified ontology that aligns PartNet, 3DCoMPaT++, and Find3D, consisting of 1,794 unique 3D parts. We also show examples from our newly created Tex-Parts dataset. We also introduce 2 novel metrics appropriate for the named 3D part segmentation task.
Gaussian Scenes: Pose-Free Sparse-View Scene Reconstruction using Depth-Enhanced Diffusion Priors
Nov 24, 2024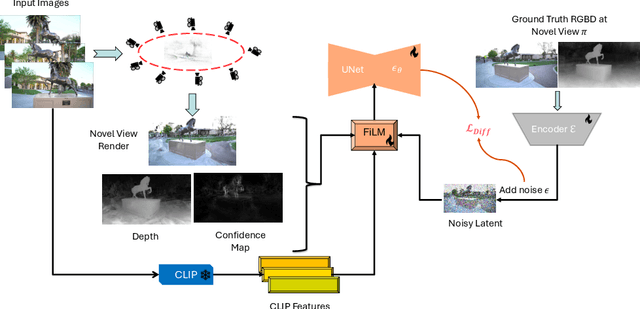
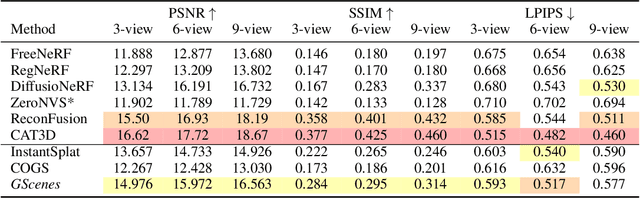

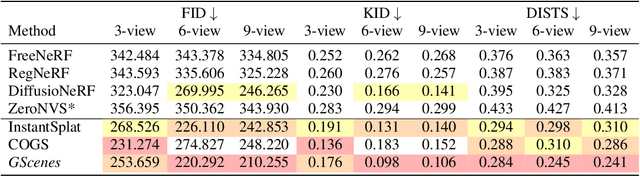
In this work, we introduce a generative approach for pose-free reconstruction of $360^{\circ}$ scenes from a limited number of uncalibrated 2D images. Pose-free scene reconstruction from incomplete, unposed observations is usually regularized with depth estimation or 3D foundational priors. While recent advances have enabled sparse-view reconstruction of unbounded scenes with known camera poses using diffusion priors, these methods rely on explicit camera embeddings for extrapolating unobserved regions. This reliance limits their application in pose-free settings, where view-specific data is only implicitly available. To address this, we propose an instruction-following RGBD diffusion model designed to inpaint missing details and remove artifacts in novel view renders and depth maps of a 3D scene. We also propose a novel confidence measure for Gaussian representations to allow for better detection of these artifacts. By progressively integrating these novel views in a Gaussian-SLAM-inspired process, we achieve a multi-view-consistent Gaussian representation. Evaluations on the MipNeRF360 dataset demonstrate that our method surpasses existing pose-free techniques and performs competitively with state-of-the-art posed reconstruction methods in complex $360^{\circ}$ scenes.
Sp2360: Sparse-view 360 Scene Reconstruction using Cascaded 2D Diffusion Priors
May 26, 2024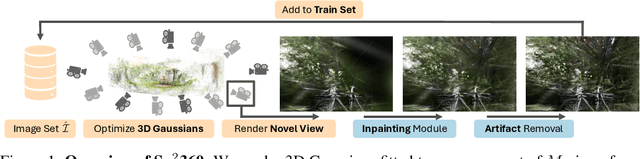



We aim to tackle sparse-view reconstruction of a 360 3D scene using priors from latent diffusion models (LDM). The sparse-view setting is ill-posed and underconstrained, especially for scenes where the camera rotates 360 degrees around a point, as no visual information is available beyond some frontal views focused on the central object(s) of interest. In this work, we show that pretrained 2D diffusion models can strongly improve the reconstruction of a scene with low-cost fine-tuning. Specifically, we present SparseSplat360 (Sp2360), a method that employs a cascade of in-painting and artifact removal models to fill in missing details and clean novel views. Due to superior training and rendering speeds, we use an explicit scene representation in the form of 3D Gaussians over NeRF-based implicit representations. We propose an iterative update strategy to fuse generated pseudo novel views with existing 3D Gaussians fitted to the initial sparse inputs. As a result, we obtain a multi-view consistent scene representation with details coherent with the observed inputs. Our evaluation on the challenging Mip-NeRF360 dataset shows that our proposed 2D to 3D distillation algorithm considerably improves the performance of a regularized version of 3DGS adapted to a sparse-view setting and outperforms existing sparse-view reconstruction methods in 360 scene reconstruction. Qualitatively, our method generates entire 360 scenes from as few as 9 input views, with a high degree of foreground and background detail.
TTT-UCDR: Test-time Training for Universal Cross-Domain Retrieval
Aug 19, 2022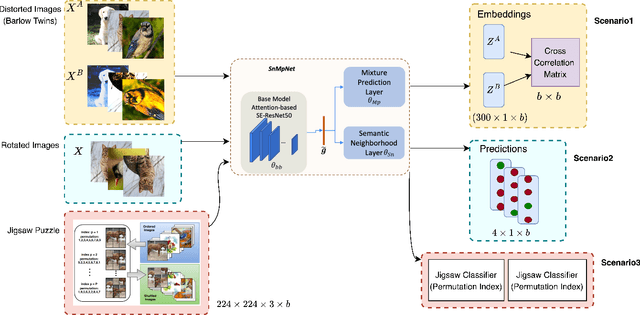
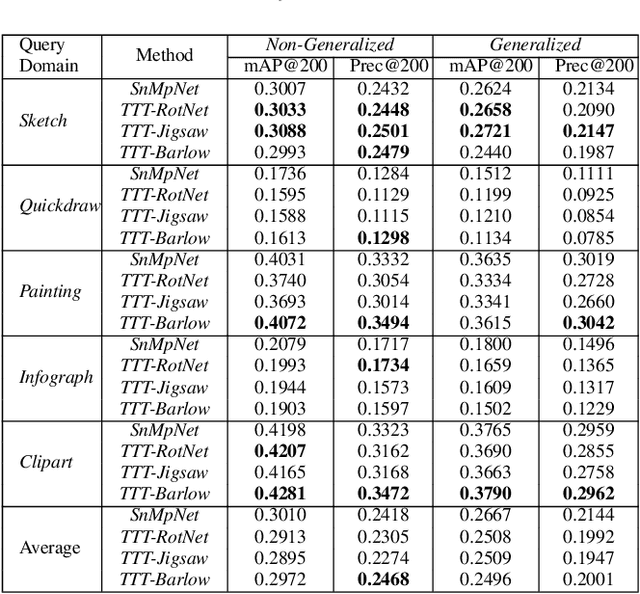

Image retrieval is a niche problem in computer vision curated towards finding similar images in a database using a query. In this work, for the first time in literature, we employ test-time training techniques for adapting to distribution shifts under Universal Cross-Domain Retrieval (UCDR). Test-time training has previously been shown to reduce generalization error for image classification, domain adaptation, semantic segmentation, and zero-shot sketch-based image retrieval (ZS-SBIR). In UCDR, in addition to the semantic shift of unknown categories present in ZS-SBIR, the presence of unknown domains leads to even higher distribution shifts. To bridge this domain gap, we use self-supervision through 3 different losses - Barlow Twins, Jigsaw Puzzle and RotNet on a pretrained network at test-time. This simple approach leads to improvements on UCDR benchmarks and also improves model robustness under a challenging cross-dataset generalization setting.
Universal Cross-Domain Retrieval: Generalizing Across Classes and Domains
Aug 18, 2021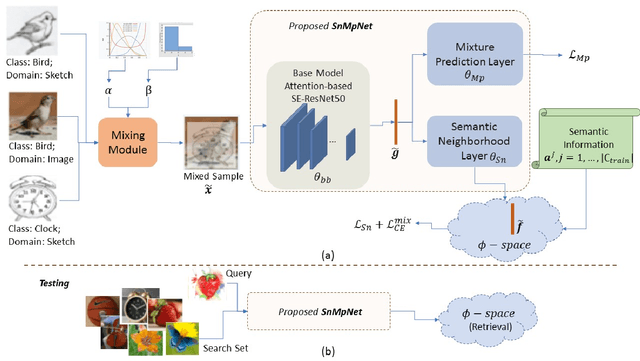



In this work, for the first time, we address the problem of universal cross-domain retrieval, where the test data can belong to classes or domains which are unseen during training. Due to dynamically increasing number of categories and practical constraint of training on every possible domain, which requires large amounts of data, generalizing to both unseen classes and domains is important. Towards that goal, we propose SnMpNet (Semantic Neighbourhood and Mixture Prediction Network), which incorporates two novel losses to account for the unseen classes and domains encountered during testing. Specifically, we introduce a novel Semantic Neighborhood loss to bridge the knowledge gap between seen and unseen classes and ensure that the latent space embedding of the unseen classes is semantically meaningful with respect to its neighboring classes. We also introduce a mix-up based supervision at image-level as well as semantic-level of the data for training with the Mixture Prediction loss, which helps in efficient retrieval when the query belongs to an unseen domain. These losses are incorporated on the SE-ResNet50 backbone to obtain SnMpNet. Extensive experiments on two large-scale datasets, Sketchy Extended and DomainNet, and thorough comparisons with state-of-the-art justify the effectiveness of the proposed model.
Knowledge Distillation for Singing Voice Detection
Nov 09, 2020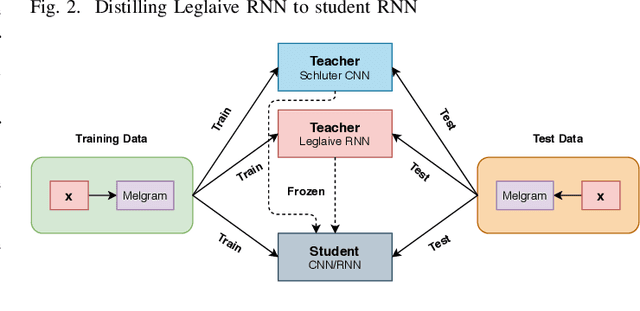
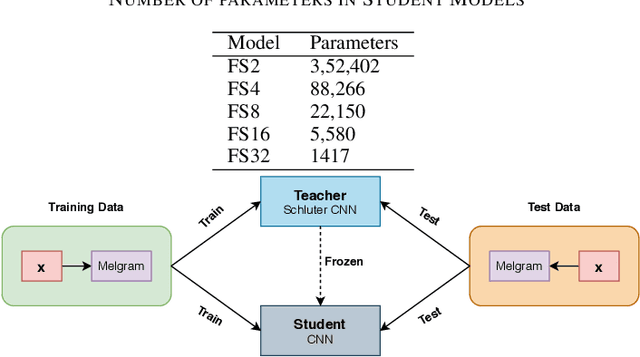
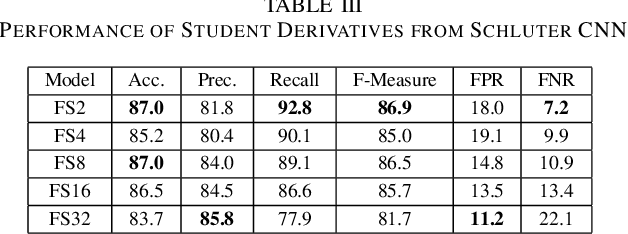
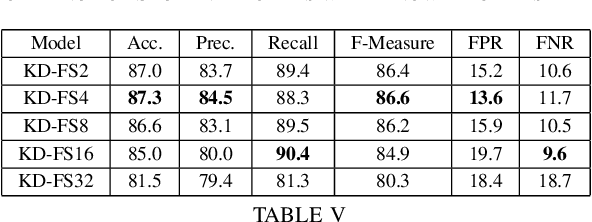
Singing Voice Detection (SVD) has been an active area of research in music information retrieval (MIR). Currently, two deep neural network-based methods, one based on CNN and the other on RNN, exist in literature that learn optimized features for the voice detection (VD) task and achieve state-of-the-art performance on common datasets. Both these models have a huge number of parameters (1.4M for CNN and 65.7K for RNN) and hence not suitable for deployment on devices like smartphones or embedded sensors with limited capacity in terms of memory and computation power. The most popular method to address this issue is known as knowledge distillation in deep learning literature (in addition to model compression) where a large pretrained network known as the teacher is used to train a smaller student network. However, to the best of our knowledge, such methods have not been explored yet in the domain of SVD. In this paper, efforts have been made to investigate this issue using both conventional as well as ensemble knowledge distillation techniques. Through extensive experimentation on the publicly available Jamendo dataset, we show that, not only it's possible to achieve comparable accuracies with far smaller models (upto 1000x smaller in terms of parameters), but fascinatingly, in some cases, smaller models trained with distillation, even surpass the current state-of-the-art models on voice detection performance.
Addressing target shift in zero-shot learning using grouped adversarial learning
Mar 02, 2020
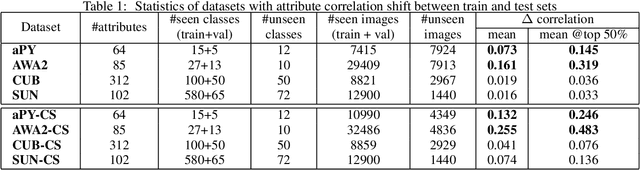
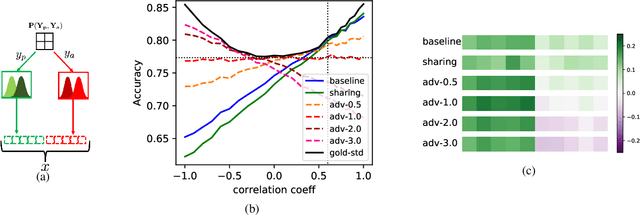
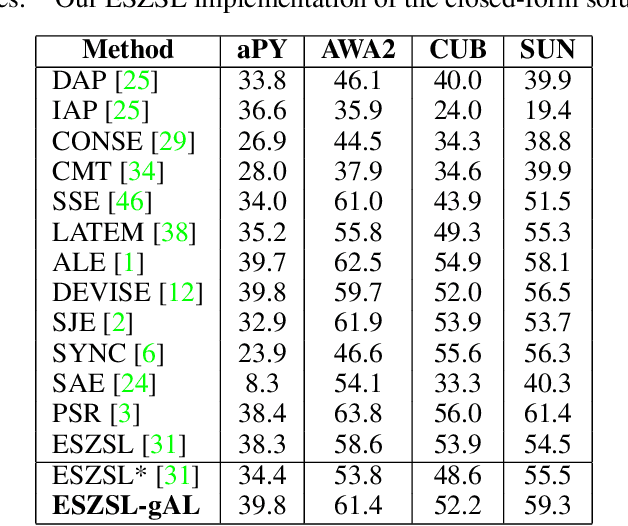
In this paper, we present a new paradigm to zero-shot learning (ZSL) that is trained by utilizing additional information (such as attribute-class mapping) for specific set of unseen classes. We conjecture that such additional information about unseen classes is more readily available than unsupervised image sets. Further, on close examination of the underlying attribute predictors of popular ZSL algorithms, we find that they often leverage attribute correlations to make predictions. While attribute correlations that remain intact in the unseen classes (test) benefit the prediction of difficult attributes, change in correlations can have an adverse effect on ZSL performance. For example, detecting an attribute 'brown' may be the same as detecting 'fur' over an animals' image dataset captured in the tropics. However, such a model might fail on unseen images of Arctic animals. To address this effect, termed target-shift in ZSL, we utilize our proposed framework to design grouped adversarial learning. We introduce grouping of attributes to enable the model to continue to benefit from useful correlations, while restricting cross-group correlations that may be harmful for generalization. Our analysis shows that it is possible to not only constrain the model from leveraging unwanted correlations, but also adjust them to specific test setting using only the additional information (the already available attribute-class mapping). We show empirical results for zero-shot predictions on standard benchmark datasets, namely, aPY, AwA2, SUN and CUB datasets. We further introduce to the research community, a new experimental train-test split that maximizes target-shift to further study its effects.