 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan These Views Be One Scene? Evaluating Multiview 3D Consistency when 3D Foundation Models Hallucinate
May 18, 2026Multiview 3D evaluation assumes that the images being scored are observations of one static 3D scene. This assumption can fail in NVS and sparse-view reconstruction: inputs or generated outputs may contain artifacts, outlier frames, repeated views, or noise, yet still receive high 3D consistency scores. Existing reference-based metrics require ground truth, while ground-truth-free metrics such as MEt3R depend on learned reconstruction backbones whose failure modes are poorly characterized. We study this reliability problem by comparing neural reconstruction priors with classical geometric verification. We introduce \benchmark, a controlled robustness benchmark for multiview 3D consistency, and a parametric family that decomposes neural metrics into backbone, residual, and aggregation components. This family recovers MEt3R and yields variants up to $3\times$ more robust. Our analysis shows that VGGT, MASt3R, DUSt3R, and Fast3R can hallucinate dense geometry and cross-view support for unrelated scenes, repeated images, and random noise. We introduce COLMAP-based metrics that use matches, registration, dense support, and reconstruction failure as failure-aware consistency signals. On real NVS outputs and a structured human study, these metrics achieve up to $4\times$ higher correlation with human judgments than MEt3R.
Shared LoRA Subspaces for almost Strict Continual Learning
Feb 05, 2026Adapting large pretrained models to new tasks efficiently and continually is crucial for real-world deployment but remains challenging due to catastrophic forgetting and the high cost of retraining. While parameter-efficient tuning methods like low rank adaptation (LoRA) reduce computational demands, they lack mechanisms for strict continual learning and knowledge integration, without relying on data replay, or multiple adapters. We propose Share, a novel approach to parameter efficient continual finetuning that learns and dynamically updates a single, shared low-rank subspace, enabling seamless adaptation across multiple tasks and modalities. Share constructs a foundational subspace that extracts core knowledge from past tasks and incrementally integrates new information by identifying essential subspace directions. Knowledge from each new task is incorporated into this evolving subspace, facilitating forward knowledge transfer, while minimizing catastrophic interference. This approach achieves up to 100x parameter reduction and 281x memory savings over traditional LoRA methods, maintaining performance comparable to jointly trained models. A single Share model can replace hundreds of task-specific LoRA adapters, supporting scalable, asynchronous continual learning. Experiments across image classification, natural language understanding, 3D pose estimation, and text-to-image generation validate its effectiveness, making Share a practical and scalable solution for lifelong learning in large-scale AI systems.
Name That Part: 3D Part Segmentation and Naming
Dec 19, 2025
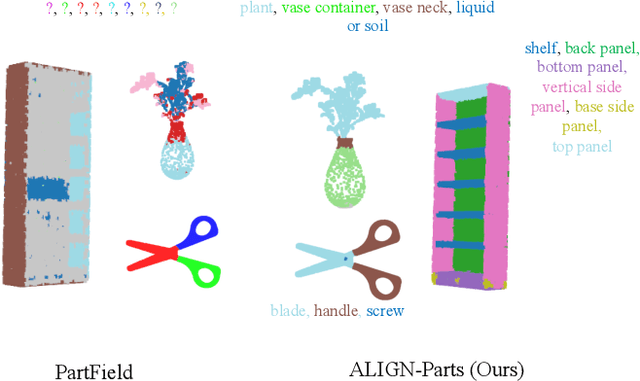

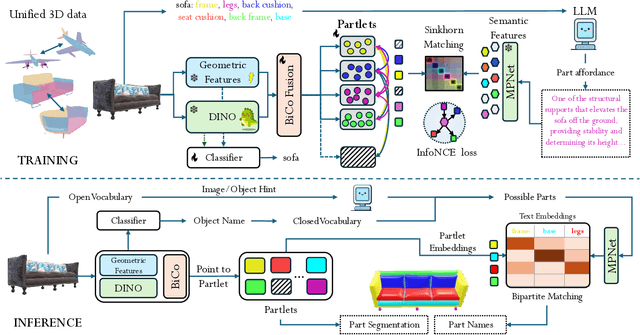
We address semantic 3D part segmentation: decomposing objects into parts with meaningful names. While datasets exist with part annotations, their definitions are inconsistent across datasets, limiting robust training. Previous methods produce unlabeled decompositions or retrieve single parts without complete shape annotations. We propose ALIGN-Parts, which formulates part naming as a direct set alignment task. Our method decomposes shapes into partlets - implicit 3D part representations - matched to part descriptions via bipartite assignment. We combine geometric cues from 3D part fields, appearance from multi-view vision features, and semantic knowledge from language-model-generated affordance descriptions. Text-alignment loss ensures partlets share embedding space with text, enabling a theoretically open-vocabulary matching setup, given sufficient data. Our efficient and novel, one-shot, 3D part segmentation and naming method finds applications in several downstream tasks, including serving as a scalable annotation engine. As our model supports zero-shot matching to arbitrary descriptions and confidence-calibrated predictions for known categories, with human verification, we create a unified ontology that aligns PartNet, 3DCoMPaT++, and Find3D, consisting of 1,794 unique 3D parts. We also show examples from our newly created Tex-Parts dataset. We also introduce 2 novel metrics appropriate for the named 3D part segmentation task.
EigenLoRAx: Recycling Adapters to Find Principal Subspaces for Resource-Efficient Adaptation and Inference
Feb 07, 2025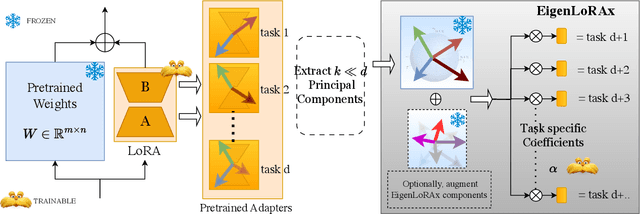
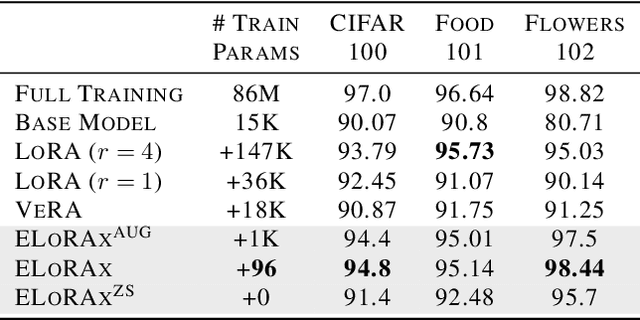
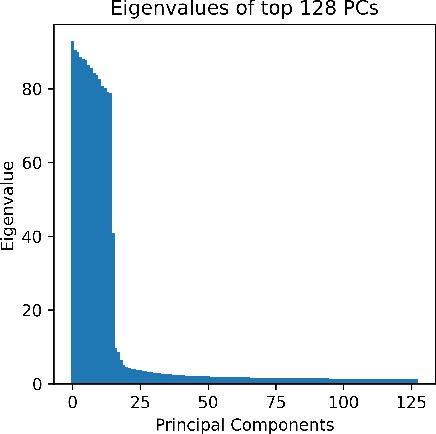
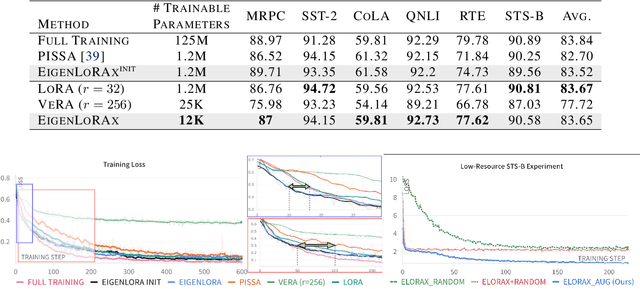
The rapid growth of large models has raised concerns about their environmental impact and equity in accessibility due to significant computational costs. Low-Rank Adapters (LoRA) offer a lightweight solution for finetuning large models, resulting in an abundance of publicly available adapters tailored to diverse domains. We ask: Can these pretrained adapters be leveraged to further streamline adaptation to new tasks while addressing these challenges? We introduce EigenLoRAx, a parameter-efficient finetuning method that recycles existing adapters to create a principal subspace aligned with their shared domain knowledge which can be further augmented with orthogonal basis vectors in low-resource scenarios. This enables rapid adaptation to new tasks by learning only lightweight coefficients on the principal components of the subspace - eliminating the need to finetune entire adapters. EigenLoRAx requires significantly fewer parameters and memory, improving efficiency for both training and inference. Our method demonstrates strong performance across diverse domains and tasks, offering a scalable for edge-based applications, personalization, and equitable deployment of large models in resource-constrained environments.
Gaussian Scenes: Pose-Free Sparse-View Scene Reconstruction using Depth-Enhanced Diffusion Priors
Nov 24, 2024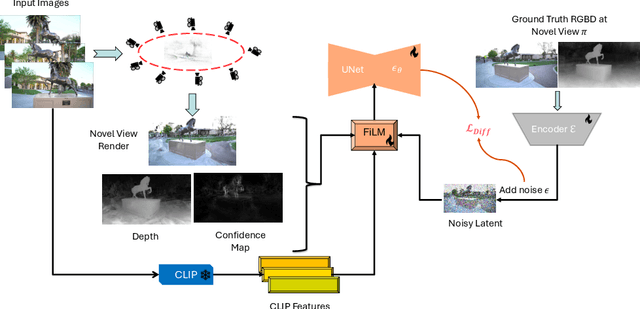
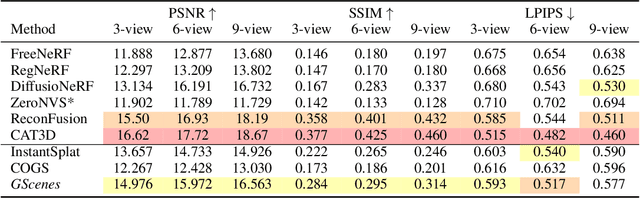

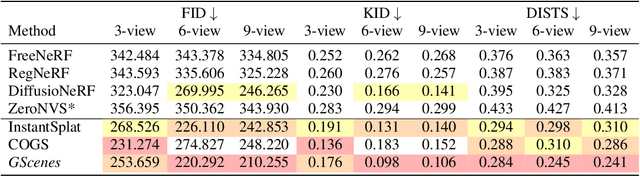
In this work, we introduce a generative approach for pose-free reconstruction of $360^{\circ}$ scenes from a limited number of uncalibrated 2D images. Pose-free scene reconstruction from incomplete, unposed observations is usually regularized with depth estimation or 3D foundational priors. While recent advances have enabled sparse-view reconstruction of unbounded scenes with known camera poses using diffusion priors, these methods rely on explicit camera embeddings for extrapolating unobserved regions. This reliance limits their application in pose-free settings, where view-specific data is only implicitly available. To address this, we propose an instruction-following RGBD diffusion model designed to inpaint missing details and remove artifacts in novel view renders and depth maps of a 3D scene. We also propose a novel confidence measure for Gaussian representations to allow for better detection of these artifacts. By progressively integrating these novel views in a Gaussian-SLAM-inspired process, we achieve a multi-view-consistent Gaussian representation. Evaluations on the MipNeRF360 dataset demonstrate that our method surpasses existing pose-free techniques and performs competitively with state-of-the-art posed reconstruction methods in complex $360^{\circ}$ scenes.
iNeMo: Incremental Neural Mesh Models for Robust Class-Incremental Learning
Jul 12, 2024Different from human nature, it is still common practice today for vision tasks to train deep learning models only initially and on fixed datasets. A variety of approaches have recently addressed handling continual data streams. However, extending these methods to manage out-of-distribution (OOD) scenarios has not effectively been investigated. On the other hand, it has recently been shown that non-continual neural mesh models exhibit strong performance in generalizing to such OOD scenarios. To leverage this decisive property in a continual learning setting, we propose incremental neural mesh models that can be extended with new meshes over time. In addition, we present a latent space initialization strategy that enables us to allocate feature space for future unseen classes in advance and a positional regularization term that forces the features of the different classes to consistently stay in respective latent space regions. We demonstrate the effectiveness of our method through extensive experiments on the Pascal3D and ObjectNet3D datasets and show that our approach outperforms the baselines for classification by $2-6\%$ in the in-domain and by $6-50\%$ in the OOD setting. Our work also presents the first incremental learning approach for pose estimation. Our code and model can be found at https://github.com/Fischer-Tom/iNeMo.
A Bayesian Approach to OOD Robustness in Image Classification
Mar 12, 2024



An important and unsolved problem in computer vision is to ensure that the algorithms are robust to changes in image domains. We address this problem in the scenario where we have access to images from the target domains but no annotations. Motivated by the challenges of the OOD-CV benchmark where we encounter real world Out-of-Domain (OOD) nuisances and occlusion, we introduce a novel Bayesian approach to OOD robustness for object classification. Our work extends Compositional Neural Networks (CompNets), which have been shown to be robust to occlusion but degrade badly when tested on OOD data. We exploit the fact that CompNets contain a generative head defined over feature vectors represented by von Mises-Fisher (vMF) kernels, which correspond roughly to object parts, and can be learned without supervision. We obverse that some vMF kernels are similar between different domains, while others are not. This enables us to learn a transitional dictionary of vMF kernels that are intermediate between the source and target domains and train the generative model on this dictionary using the annotations on the source domain, followed by iterative refinement. This approach, termed Unsupervised Generative Transition (UGT), performs very well in OOD scenarios even when occlusion is present. UGT is evaluated on different OOD benchmarks including the OOD-CV dataset, several popular datasets (e.g., ImageNet-C [9]), artificial image corruptions (including adding occluders), and synthetic-to-real domain transfer, and does well in all scenarios outperforming SOTA alternatives (e.g. up to 10% top-1 accuracy on Occluded OOD-CV dataset).
Source-Free and Image-Only Unsupervised Domain Adaptation for Category Level Object Pose Estimation
Jan 19, 2024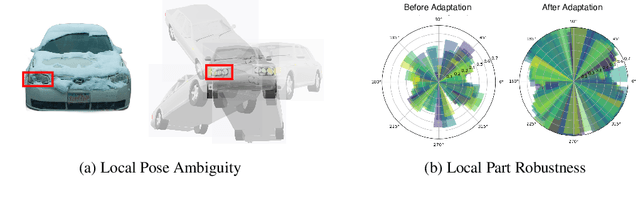
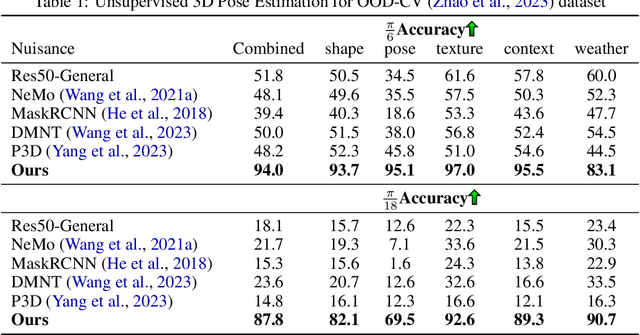
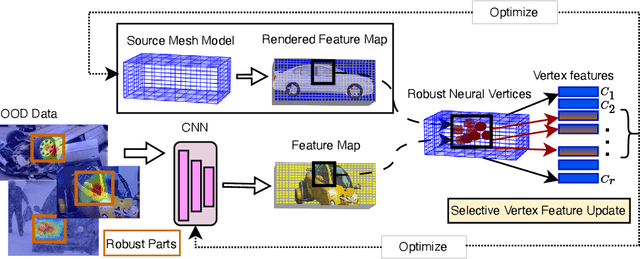
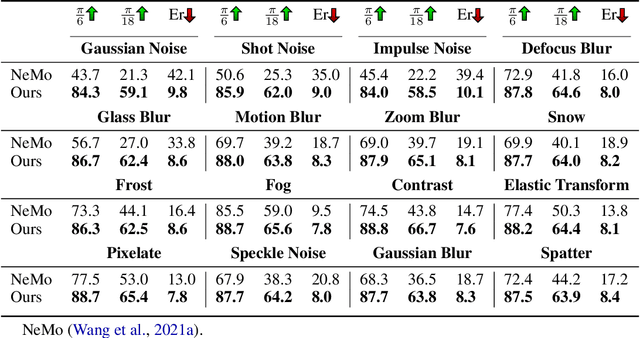
We consider the problem of source-free unsupervised category-level pose estimation from only RGB images to a target domain without any access to source domain data or 3D annotations during adaptation. Collecting and annotating real-world 3D data and corresponding images is laborious, expensive, yet unavoidable process, since even 3D pose domain adaptation methods require 3D data in the target domain. We introduce 3DUDA, a method capable of adapting to a nuisance-ridden target domain without 3D or depth data. Our key insight stems from the observation that specific object subparts remain stable across out-of-domain (OOD) scenarios, enabling strategic utilization of these invariant subcomponents for effective model updates. We represent object categories as simple cuboid meshes, and harness a generative model of neural feature activations modeled at each mesh vertex learnt using differential rendering. We focus on individual locally robust mesh vertex features and iteratively update them based on their proximity to corresponding features in the target domain even when the global pose is not correct. Our model is then trained in an EM fashion, alternating between updating the vertex features and the feature extractor. We show that our method simulates fine-tuning on a global pseudo-labeled dataset under mild assumptions, which converges to the target domain asymptotically. Through extensive empirical validation, including a complex extreme UDA setup which combines real nuisances, synthetic noise, and occlusion, we demonstrate the potency of our simple approach in addressing the domain shift challenge and significantly improving pose estimation accuracy.
Learning Part Segmentation from Synthetic Animals
Nov 30, 2023



Semantic part segmentation provides an intricate and interpretable understanding of an object, thereby benefiting numerous downstream tasks. However, the need for exhaustive annotations impedes its usage across diverse object types. This paper focuses on learning part segmentation from synthetic animals, leveraging the Skinned Multi-Animal Linear (SMAL) models to scale up existing synthetic data generated by computer-aided design (CAD) animal models. Compared to CAD models, SMAL models generate data with a wider range of poses observed in real-world scenarios. As a result, our first contribution is to construct a synthetic animal dataset of tigers and horses with more pose diversity, termed Synthetic Animal Parts (SAP). We then benchmark Syn-to-Real animal part segmentation from SAP to PartImageNet, namely SynRealPart, with existing semantic segmentation domain adaptation methods and further improve them as our second contribution. Concretely, we examine three Syn-to-Real adaptation methods but observe relative performance drop due to the innate difference between the two tasks. To address this, we propose a simple yet effective method called Class-Balanced Fourier Data Mixing (CB-FDM). Fourier Data Mixing aligns the spectral amplitudes of synthetic images with real images, thereby making the mixed images have more similar frequency content to real images. We further use Class-Balanced Pseudo-Label Re-Weighting to alleviate the imbalanced class distribution. We demonstrate the efficacy of CB-FDM on SynRealPart over previous methods with significant performance improvements. Remarkably, our third contribution is to reveal that the learned parts from synthetic tiger and horse are transferable across all quadrupeds in PartImageNet, further underscoring the utility and potential applications of animal part segmentation.
Animal3D: A Comprehensive Dataset of 3D Animal Pose and Shape
Aug 22, 2023



Accurately estimating the 3D pose and shape is an essential step towards understanding animal behavior, and can potentially benefit many downstream applications, such as wildlife conservation. However, research in this area is held back by the lack of a comprehensive and diverse dataset with high-quality 3D pose and shape annotations. In this paper, we propose Animal3D, the first comprehensive dataset for mammal animal 3D pose and shape estimation. Animal3D consists of 3379 images collected from 40 mammal species, high-quality annotations of 26 keypoints, and importantly the pose and shape parameters of the SMAL model. All annotations were labeled and checked manually in a multi-stage process to ensure highest quality results. Based on the Animal3D dataset, we benchmark representative shape and pose estimation models at: (1) supervised learning from only the Animal3D data, (2) synthetic to real transfer from synthetically generated images, and (3) fine-tuning human pose and shape estimation models. Our experimental results demonstrate that predicting the 3D shape and pose of animals across species remains a very challenging task, despite significant advances in human pose estimation. Our results further demonstrate that synthetic pre-training is a viable strategy to boost the model performance. Overall, Animal3D opens new directions for facilitating future research in animal 3D pose and shape estimation, and is publicly available.