 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantHDR: Single-forward Gaussian Splatting for High Dynamic Range 3D Reconstruction
Mar 11, 2026High dynamic range (HDR) novel view synthesis (NVS) aims to reconstruct HDR scenes from multi-exposure low dynamic range (LDR) images. Existing HDR pipelines heavily rely on known camera poses, well-initialized dense point clouds, and time-consuming per-scene optimization. Current feed-forward alternatives overlook the HDR problem by assuming exposure-invariant appearance. To bridge this gap, we propose InstantHDR, a feed-forward network that reconstructs 3D HDR scenes from uncalibrated multi-exposure LDR collections in a single forward pass. Specifically, we design a geometry-guided appearance modeling for multi-exposure fusion, and a meta-network for generalizable scene-specific tone mapping. Due to the lack of HDR scene data, we build a pre-training dataset, called HDR-Pretrain, for generalizable feed-forward HDR models, featuring 168 Blender-rendered scenes, diverse lighting types, and multiple camera response functions. Comprehensive experiments show that our InstantHDR delivers comparable synthesis performance to the state-of-the-art optimization-based HDR methods while enjoying $\sim700\times$ and $\sim20\times$ reconstruction speed improvement with our single-forward and post-optimization settings. All code, models, and datasets will be released after the review process.
Endless World: Real-Time 3D-Aware Long Video Generation
Dec 13, 2025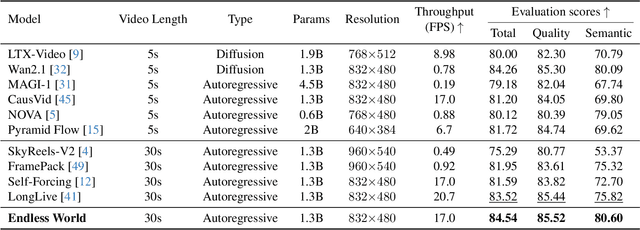
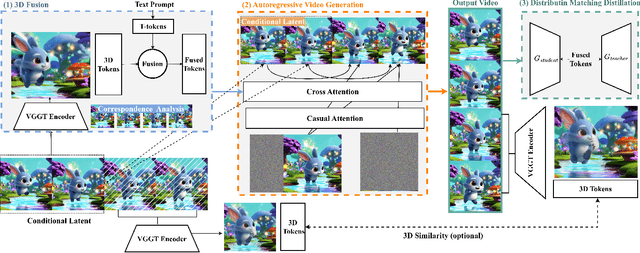
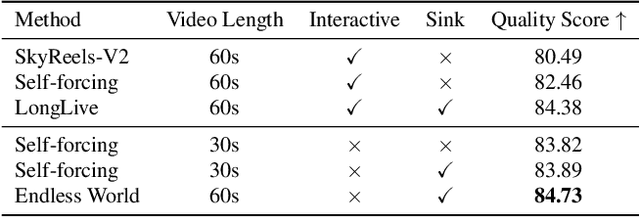

Producing long, coherent video sequences with stable 3D structure remains a major challenge, particularly in streaming scenarios. Motivated by this, we introduce Endless World, a real-time framework for infinite, 3D-consistent video generation.To support infinite video generation, we introduce a conditional autoregressive training strategy that aligns newly generated content with existing video frames. This design preserves long-range dependencies while remaining computationally efficient, enabling real-time inference on a single GPU without additional training overhead.Moreover, our Endless World integrates global 3D-aware attention to provide continuous geometric guidance across time. Our 3D injection mechanism enforces physical plausibility and geometric consistency throughout extended sequences, addressing key challenges in long-horizon and dynamic scene synthesis.Extensive experiments demonstrate that Endless World produces long, stable, and visually coherent videos, achieving competitive or superior performance to existing methods in both visual fidelity and spatial consistency. Our project has been available on https://bwgzk-keke.github.io/EndlessWorld/.
FreeViS: Training-free Video Stylization with Inconsistent References
Oct 02, 2025Video stylization plays a key role in content creation, but it remains a challenging problem. Na\"ively applying image stylization frame-by-frame hurts temporal consistency and reduces style richness. Alternatively, training a dedicated video stylization model typically requires paired video data and is computationally expensive. In this paper, we propose FreeViS, a training-free video stylization framework that generates stylized videos with rich style details and strong temporal coherence. Our method integrates multiple stylized references to a pretrained image-to-video (I2V) model, effectively mitigating the propagation errors observed in prior works, without introducing flickers and stutters. In addition, it leverages high-frequency compensation to constrain the content layout and motion, together with flow-based motion cues to preserve style textures in low-saliency regions. Through extensive evaluations, FreeViS delivers higher stylization fidelity and superior temporal consistency, outperforming recent baselines and achieving strong human preference. Our training-free pipeline offers a practical and economic solution for high-quality, temporally coherent video stylization. The code and videos can be accessed via https://xujiacong.github.io/FreeViS/
Think Before You Diffuse: LLMs-Guided Physics-Aware Video Generation
May 27, 2025Recent video diffusion models have demonstrated their great capability in generating visually-pleasing results, while synthesizing the correct physical effects in generated videos remains challenging. The complexity of real-world motions, interactions, and dynamics introduce great difficulties when learning physics from data. In this work, we propose DiffPhy, a generic framework that enables physically-correct and photo-realistic video generation by fine-tuning a pre-trained video diffusion model. Our method leverages large language models (LLMs) to explicitly reason a comprehensive physical context from the text prompt and use it to guide the generation. To incorporate physical context into the diffusion model, we leverage a Multimodal large language model (MLLM) as a supervisory signal and introduce a set of novel training objectives that jointly enforce physical correctness and semantic consistency with the input text. We also establish a high-quality physical video dataset containing diverse phyiscal actions and events to facilitate effective finetuning. Extensive experiments on public benchmarks demonstrate that DiffPhy is able to produce state-of-the-art results across diverse physics-related scenarios. Our project page is available at https://bwgzk-keke.github.io/DiffPhy/
Filter Images First, Generate Instructions Later: Pre-Instruction Data Selection for Visual Instruction Tuning
Mar 10, 2025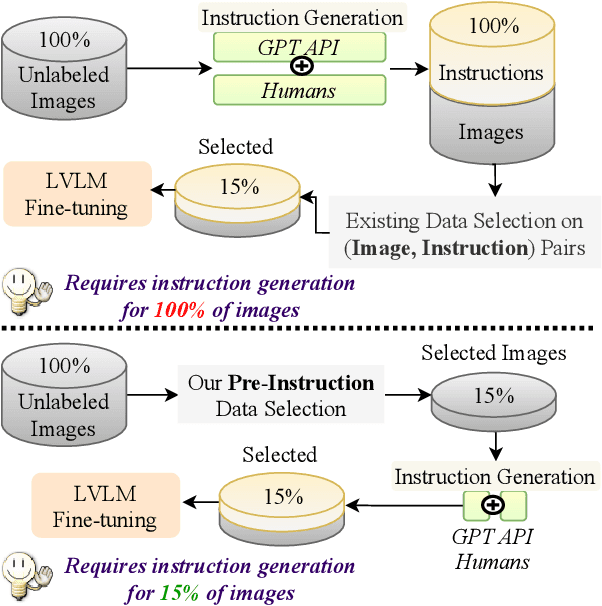



Visual instruction tuning (VIT) for large vision-language models (LVLMs) requires training on expansive datasets of image-instruction pairs, which can be costly. Recent efforts in VIT data selection aim to select a small subset of high-quality image-instruction pairs, reducing VIT runtime while maintaining performance comparable to full-scale training. However, a major challenge often overlooked is that generating instructions from unlabeled images for VIT is highly expensive. Most existing VIT datasets rely heavily on human annotations or paid services like the GPT API, which limits users with constrained resources from creating VIT datasets for custom applications. To address this, we introduce Pre-Instruction Data Selection (PreSel), a more practical data selection paradigm that directly selects the most beneficial unlabeled images and generates instructions only for the selected images. PreSel first estimates the relative importance of each vision task within VIT datasets to derive task-wise sampling budgets. It then clusters image features within each task, selecting the most representative images with the budget. This approach reduces computational overhead for both instruction generation during VIT data formation and LVLM fine-tuning. By generating instructions for only 15% of the images, PreSel achieves performance comparable to full-data VIT on the LLaVA-1.5 and Vision-Flan datasets. The link to our project page: https://bardisafa.github.io/PreSel
Towards Zero-Shot Anomaly Detection and Reasoning with Multimodal Large Language Models
Feb 11, 2025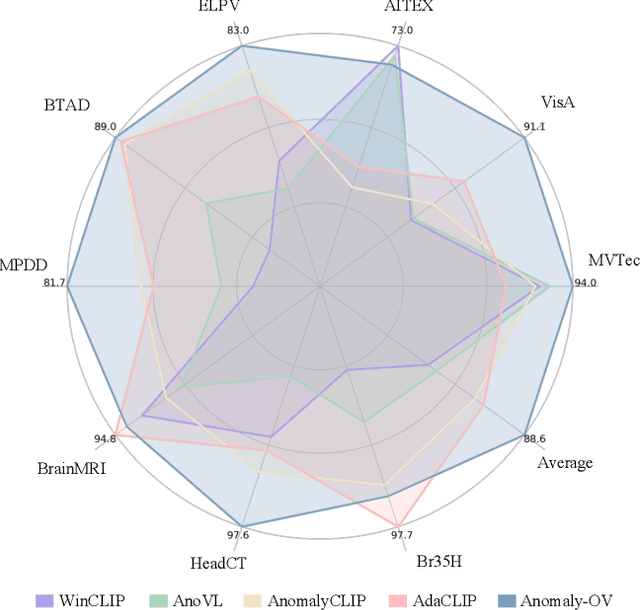
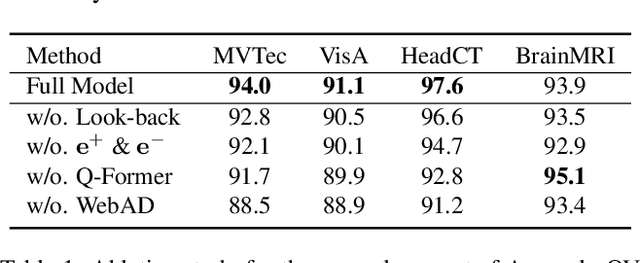

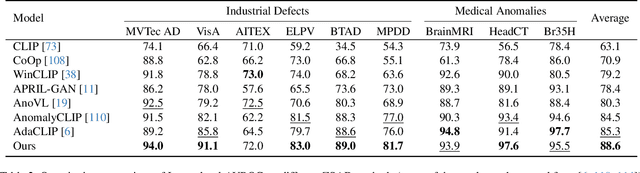
Zero-Shot Anomaly Detection (ZSAD) is an emerging AD paradigm. Unlike the traditional unsupervised AD setting that requires a large number of normal samples to train a model, ZSAD is more practical for handling data-restricted real-world scenarios. Recently, Multimodal Large Language Models (MLLMs) have shown revolutionary reasoning capabilities in various vision tasks. However, the reasoning of image abnormalities remains underexplored due to the lack of corresponding datasets and benchmarks. To facilitate research in AD & reasoning, we establish the first visual instruction tuning dataset, Anomaly-Instruct-125k, and the evaluation benchmark, VisA-D&R. Through investigation with our benchmark, we reveal that current MLLMs like GPT-4o cannot accurately detect and describe fine-grained anomalous details in images. To address this, we propose Anomaly-OneVision (Anomaly-OV), the first specialist visual assistant for ZSAD and reasoning. Inspired by human behavior in visual inspection, Anomaly-OV leverages a Look-Twice Feature Matching (LTFM) mechanism to adaptively select and emphasize abnormal visual tokens. Extensive experiments demonstrate that Anomaly-OV achieves significant improvements over advanced generalist models in both detection and reasoning. Extensions to medical and 3D AD are provided for future study. The link to our project page: https://xujiacong.github.io/Anomaly-OV/
XYScanNet: An Interpretable State Space Model for Perceptual Image Deblurring
Dec 13, 2024



Deep state-space models (SSMs), like recent Mamba architectures, are emerging as a promising alternative to CNN and Transformer networks. Existing Mamba-based restoration methods process the visual data by leveraging a flatten-and-scan strategy that converts image patches into a 1D sequence before scanning. However, this scanning paradigm ignores local pixel dependencies and introduces spatial misalignment by positioning distant pixels incorrectly adjacent, which reduces local noise-awareness and degrades image sharpness in low-level vision tasks. To overcome these issues, we propose a novel slice-and-scan strategy that alternates scanning along intra- and inter-slices. We further design a new Vision State Space Module (VSSM) for image deblurring, and tackle the inefficiency challenges of the current Mamba-based vision module. Building upon this, we develop XYScanNet, an SSM architecture integrated with a lightweight feature fusion module for enhanced image deblurring. XYScanNet, maintains competitive distortion metrics and significantly improves perceptual performance. Experimental results show that XYScanNet enhances KID by $17\%$ compared to the nearest competitor. Our code will be released soon.
Reference-based Controllable Scene Stylization with Gaussian Splatting
Jul 09, 2024



Referenced-based scene stylization that edits the appearance based on a content-aligned reference image is an emerging research area. Starting with a pretrained neural radiance field (NeRF), existing methods typically learn a novel appearance that matches the given style. Despite their effectiveness, they inherently suffer from time-consuming volume rendering, and thus are impractical for many real-time applications. In this work, we propose ReGS, which adapts 3D Gaussian Splatting (3DGS) for reference-based stylization to enable real-time stylized view synthesis. Editing the appearance of a pretrained 3DGS is challenging as it uses discrete Gaussians as 3D representation, which tightly bind appearance with geometry. Simply optimizing the appearance as prior methods do is often insufficient for modeling continuous textures in the given reference image. To address this challenge, we propose a novel texture-guided control mechanism that adaptively adjusts local responsible Gaussians to a new geometric arrangement, serving for desired texture details. The proposed process is guided by texture clues for effective appearance editing, and regularized by scene depth for preserving original geometric structure. With these novel designs, we show ReGs can produce state-of-the-art stylization results that respect the reference texture while embracing real-time rendering speed for free-view navigation.
Wild-GS: Real-Time Novel View Synthesis from Unconstrained Photo Collections
Jun 14, 2024
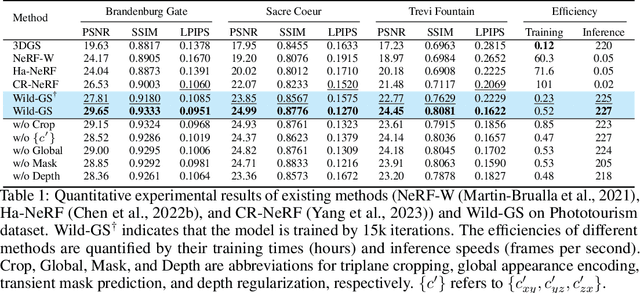
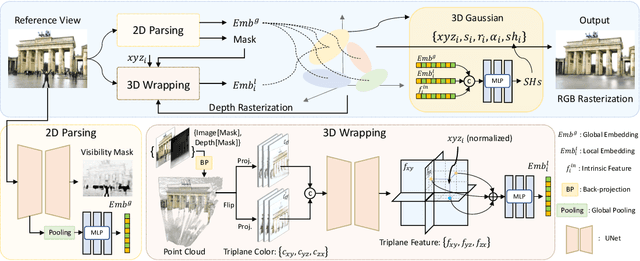
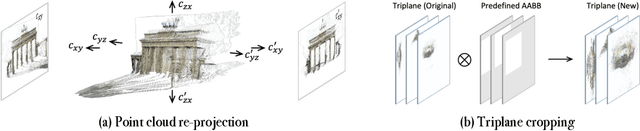
Photographs captured in unstructured tourist environments frequently exhibit variable appearances and transient occlusions, challenging accurate scene reconstruction and inducing artifacts in novel view synthesis. Although prior approaches have integrated the Neural Radiance Field (NeRF) with additional learnable modules to handle the dynamic appearances and eliminate transient objects, their extensive training demands and slow rendering speeds limit practical deployments. Recently, 3D Gaussian Splatting (3DGS) has emerged as a promising alternative to NeRF, offering superior training and inference efficiency along with better rendering quality. This paper presents Wild-GS, an innovative adaptation of 3DGS optimized for unconstrained photo collections while preserving its efficiency benefits. Wild-GS determines the appearance of each 3D Gaussian by their inherent material attributes, global illumination and camera properties per image, and point-level local variance of reflectance. Unlike previous methods that model reference features in image space, Wild-GS explicitly aligns the pixel appearance features to the corresponding local Gaussians by sampling the triplane extracted from the reference image. This novel design effectively transfers the high-frequency detailed appearance of the reference view to 3D space and significantly expedites the training process. Furthermore, 2D visibility maps and depth regularization are leveraged to mitigate the transient effects and constrain the geometry, respectively. Extensive experiments demonstrate that Wild-GS achieves state-of-the-art rendering performance and the highest efficiency in both training and inference among all the existing techniques.
Leveraging Thermal Modality to Enhance Reconstruction in Low-Light Conditions
Mar 21, 2024



Neural Radiance Fields (NeRF) accomplishes photo-realistic novel view synthesis by learning the implicit volumetric representation of a scene from multi-view images, which faithfully convey the colorimetric information. However, sensor noises will contaminate low-value pixel signals, and the lossy camera image signal processor will further remove near-zero intensities in extremely dark situations, deteriorating the synthesis performance. Existing approaches reconstruct low-light scenes from raw images but struggle to recover texture and boundary details in dark regions. Additionally, they are unsuitable for high-speed models relying on explicit representations. To address these issues, we present Thermal-NeRF, which takes thermal and visible raw images as inputs, considering the thermal camera is robust to the illumination variation and raw images preserve any possible clues in the dark, to accomplish visible and thermal view synthesis simultaneously. Also, the first multi-view thermal and visible dataset (MVTV) is established to support the research on multimodal NeRF. Thermal-NeRF achieves the best trade-off between detail preservation and noise smoothing and provides better synthesis performance than previous work. Finally, we demonstrate that both modalities are beneficial to each other in 3D reconstruction.