 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloodSQL-Bench: A Retrieval-Augmented Benchmark for Geospatially-Grounded Text-to-SQL
Dec 12, 2025Existing Text-to-SQL benchmarks primarily focus on single-table queries or limited joins in general-purpose domains, and thus fail to reflect the complexity of domain-specific, multi-table and geospatial reasoning, To address this limitation, we introduce FLOODSQL-BENCH, a geospatially grounded benchmark for the flood management domain that integrates heterogeneous datasets through key-based, spatial, and hybrid joins. The benchmark captures realistic flood-related information needs by combining social, infrastructural, and hazard data layers. We systematically evaluate recent large language models with the same retrieval-augmented generation settings and measure their performance across difficulty tiers. By providing a unified, open benchmark grounded in real-world disaster management data, FLOODSQL-BENCH establishes a practical testbed for advancing Text-to-SQL research in high-stakes application domains.
Lumos3D: A Single-Forward Framework for Low-Light 3D Scene Restoration
Nov 12, 2025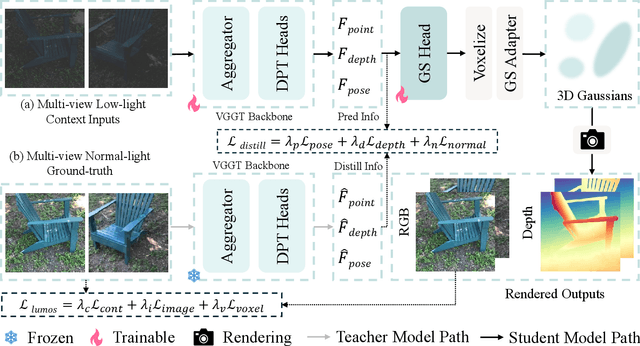

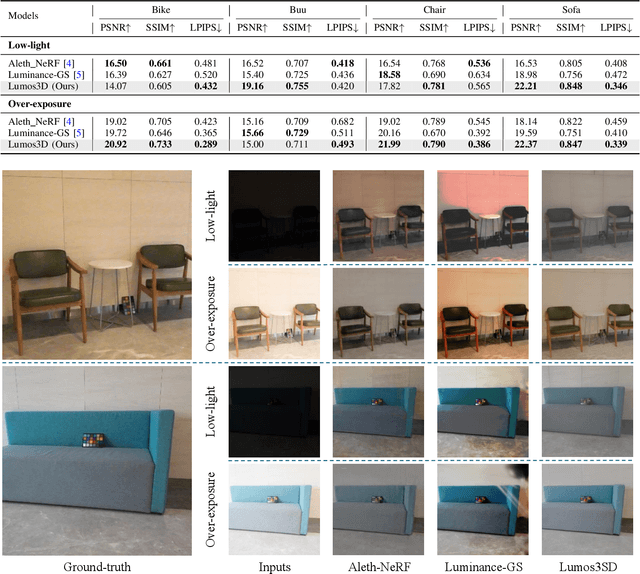
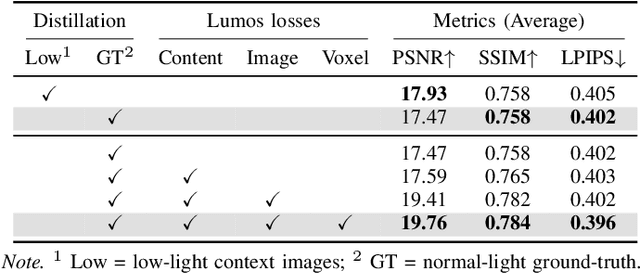
Restoring 3D scenes captured under low-light con- ditions remains a fundamental yet challenging problem. Most existing approaches depend on precomputed camera poses and scene-specific optimization, which greatly restricts their scala- bility to dynamic real-world environments. To overcome these limitations, we introduce Lumos3D, a generalizable pose-free framework for 3D low-light scene restoration. Trained once on a single dataset, Lumos3D performs inference in a purely feed- forward manner, directly restoring illumination and structure from unposed, low-light multi-view images without any per- scene training or optimization. Built upon a geometry-grounded backbone, Lumos3D reconstructs a normal-light 3D Gaussian representation that restores illumination while faithfully pre- serving structural details. During training, a cross-illumination distillation scheme is employed, where the teacher network is distilled on normal-light ground truth to transfer accurate geometric information, such as depth, to the student model. A dedicated Lumos loss is further introduced to promote photomet- ric consistency within the reconstructed 3D space. Experiments on real-world datasets demonstrate that Lumos3D achieves high- fidelity low-light 3D scene restoration with accurate geometry and strong generalization to unseen cases. Furthermore, the framework naturally extends to handle over-exposure correction, highlighting its versatility for diverse lighting restoration tasks.
Stylos: Multi-View 3D Stylization with Single-Forward Gaussian Splatting
Sep 30, 2025We present Stylos, a single-forward 3D Gaussian framework for 3D style transfer that operates on unposed content, from a single image to a multi-view collection, conditioned on a separate reference style image. Stylos synthesizes a stylized 3D Gaussian scene without per-scene optimization or precomputed poses, achieving geometry-aware, view-consistent stylization that generalizes to unseen categories, scenes, and styles. At its core, Stylos adopts a Transformer backbone with two pathways: geometry predictions retain self-attention to preserve geometric fidelity, while style is injected via global cross-attention to enforce visual consistency across views. With the addition of a voxel-based 3D style loss that aligns aggregated scene features to style statistics, Stylos enforces view-consistent stylization while preserving geometry. Experiments across multiple datasets demonstrate that Stylos delivers high-quality zero-shot stylization, highlighting the effectiveness of global style-content coupling, the proposed 3D style loss, and the scalability of our framework from single view to large-scale multi-view settings.
DiNAT-IR: Exploring Dilated Neighborhood Attention for High-Quality Image Restoration
Jul 23, 2025Transformers, with their self-attention mechanisms for modeling long-range dependencies, have become a dominant paradigm in image restoration tasks. However, the high computational cost of self-attention limits scalability to high-resolution images, making efficiency-quality trade-offs a key research focus. To address this, Restormer employs channel-wise self-attention, which computes attention across channels instead of spatial dimensions. While effective, this approach may overlook localized artifacts that are crucial for high-quality image restoration. To bridge this gap, we explore Dilated Neighborhood Attention (DiNA) as a promising alternative, inspired by its success in high-level vision tasks. DiNA balances global context and local precision by integrating sliding-window attention with mixed dilation factors, effectively expanding the receptive field without excessive overhead. However, our preliminary experiments indicate that directly applying this global-local design to the classic deblurring task hinders accurate visual restoration, primarily due to the constrained global context understanding within local attention. To address this, we introduce a channel-aware module that complements local attention, effectively integrating global context without sacrificing pixel-level precision. The proposed DiNAT-IR, a Transformer-based architecture specifically designed for image restoration, achieves competitive results across multiple benchmarks, offering a high-quality solution for diverse low-level computer vision problems.
XYScanNet: An Interpretable State Space Model for Perceptual Image Deblurring
Dec 13, 2024



Deep state-space models (SSMs), like recent Mamba architectures, are emerging as a promising alternative to CNN and Transformer networks. Existing Mamba-based restoration methods process the visual data by leveraging a flatten-and-scan strategy that converts image patches into a 1D sequence before scanning. However, this scanning paradigm ignores local pixel dependencies and introduces spatial misalignment by positioning distant pixels incorrectly adjacent, which reduces local noise-awareness and degrades image sharpness in low-level vision tasks. To overcome these issues, we propose a novel slice-and-scan strategy that alternates scanning along intra- and inter-slices. We further design a new Vision State Space Module (VSSM) for image deblurring, and tackle the inefficiency challenges of the current Mamba-based vision module. Building upon this, we develop XYScanNet, an SSM architecture integrated with a lightweight feature fusion module for enhanced image deblurring. XYScanNet, maintains competitive distortion metrics and significantly improves perceptual performance. Experimental results show that XYScanNet enhances KID by $17\%$ compared to the nearest competitor. Our code will be released soon.
Behavior-Dependent Linear Recurrent Units for Efficient Sequential Recommendation
Jun 18, 2024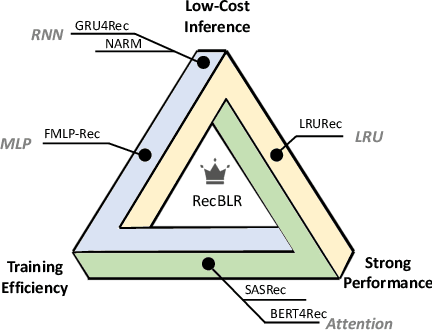
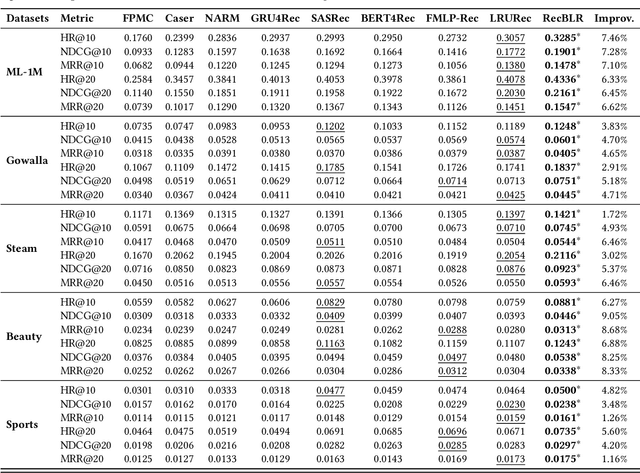
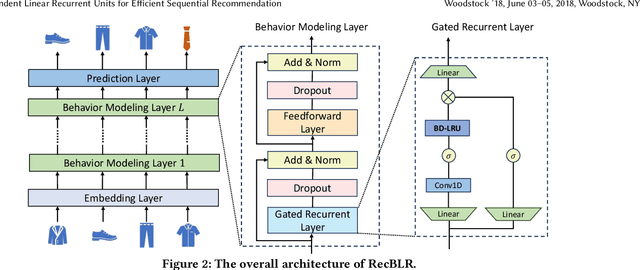
Sequential recommender systems aims to predict the users' next interaction through user behavior modeling with various operators like RNNs and attentions. However, existing models generally fail to achieve the three golden principles for sequential recommendation simultaneously, i.e., training efficiency, low-cost inference, and strong performance. To this end, we propose RecBLR, an Efficient Sequential Recommendation Model based on Behavior-Dependent Linear Recurrent Units to accomplish the impossible triangle of the three principles. By incorporating gating mechanisms and behavior-dependent designs into linear recurrent units, our model significantly enhances user behavior modeling and recommendation performance. Furthermore, we unlock the parallelizable training as well as inference efficiency for our model by designing a hardware-aware scanning acceleration algorithm with a customized CUDA kernel. Extensive experiments on real-world datasets with varying lengths of user behavior sequences demonstrate RecBLR's remarkable effectiveness in simultaneously achieving all three golden principles - strong recommendation performance, training efficiency, and low-cost inference, while exhibiting excellent scalability to datasets with long user interaction histories.
DeblurDiNAT: A Lightweight and Effective Transformer for Image Deblurring
Mar 19, 2024



Blurry images may contain local and global non-uniform artifacts, which complicate the deblurring process and make it more challenging to achieve satisfactory results. Recently, Transformers generate improved deblurring outcomes than existing CNN architectures. However, the large model size and long inference time are still two bothersome issues which have not been fully explored. To this end, we propose DeblurDiNAT, a compact encoder-decoder Transformer which efficiently restores clean images from real-world blurry ones. We adopt an alternating dilation factor structure with the aim of global-local feature learning. Also, we observe that simply using self-attention layers in networks does not always produce good deblurred results. To solve this problem, we propose a channel modulation self-attention (CMSA) block, where a cross-channel learner (CCL) is utilized to capture channel relationships. In addition, we present a divide and multiply feed-forward network (DMFN) allowing fast feature propagation. Moreover, we design a lightweight gated feature fusion (LGFF) module, which performs controlled feature merging. Comprehensive experimental results show that the proposed model, named DeblurDiNAT, provides a favorable performance boost without introducing noticeable computational costs over the baseline, and achieves state-of-the-art (SOTA) performance on several image deblurring datasets. Compared to nearest competitors, our space-efficient and time-saving method demonstrates a stronger generalization ability with 3%-68% fewer parameters and produces deblurred images that are visually closer to the ground truth.
Mamba4Rec: Towards Efficient Sequential Recommendation with Selective State Space Models
Mar 06, 2024



Sequential recommendation aims to estimate the dynamic user preferences and sequential dependencies among historical user behaviors. Although Transformer-based models have proven to be effective for sequential recommendation, they suffer from the inference inefficiency problem stemming from the quadratic computational complexity of attention operators, especially for long-range behavior sequences. Inspired by the recent success of state space models (SSMs), we propose Mamba4Rec, which is the first work to explore the potential of selective SSMs for efficient sequential recommendation. Built upon the basic Mamba block which is a selective SSM with an efficient hardware-aware parallel algorithm, we incorporate a series of sequential modeling techniques to further promote the model performance and meanwhile maintain the inference efficiency. Experiments on two public datasets demonstrate that Mamba4Rec is able to well address the effectiveness-efficiency dilemma, and defeat both RNN- and attention-based baselines in terms of both effectiveness and efficiency.