 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTail-Aware Information-Theoretic Generalization for RLHF and SGLD
Apr 12, 2026Classical information-theoretic generalization bounds typically control the generalization gap through KL-based mutual information and therefore rely on boundedness or sub-Gaussian tails via the moment generating function (MGF). In many modern pipelines, such as robust learning, RLHF, and stochastic optimization, losses and rewards can be heavy-tailed, and MGFs may not exist, rendering KL-based tools ineffective. We develop a tail-dependent information-theoretic framework for sub-Weibull data, where the tail parameter $θ$ controls the tail heaviness: $θ=2$ corresponds to sub-Gaussian, $θ=1$ to sub-exponential, and $0<θ<1$ to genuinely heavy tails. Our key technical ingredient is a decorrelation lemma that bounds change-of-measure expectations using a shifted-log $f_θ$-divergence, which admits explicit comparisons to Rényi divergence without MGF arguments. On the empirical-process side, we establish sharp maximal inequalities and a Dudley-type chaining bound for sub-Weibull processes with tail index $θ$, with complexity scaling as $\log^{1/θ}$ and entropy$^{1/θ}$. These tools yield expected and high-probability PAC-Bayes generalization bounds, as well as an information-theoretic chaining inequality based on multiscale Rényi mutual information. We illustrate the consequences in Rényi-regularized RLHF under heavy-tailed rewards and in stochastic gradient Langevin dynamics with heavy-tailed gradient noise.
DiNAT-IR: Exploring Dilated Neighborhood Attention for High-Quality Image Restoration
Jul 23, 2025Transformers, with their self-attention mechanisms for modeling long-range dependencies, have become a dominant paradigm in image restoration tasks. However, the high computational cost of self-attention limits scalability to high-resolution images, making efficiency-quality trade-offs a key research focus. To address this, Restormer employs channel-wise self-attention, which computes attention across channels instead of spatial dimensions. While effective, this approach may overlook localized artifacts that are crucial for high-quality image restoration. To bridge this gap, we explore Dilated Neighborhood Attention (DiNA) as a promising alternative, inspired by its success in high-level vision tasks. DiNA balances global context and local precision by integrating sliding-window attention with mixed dilation factors, effectively expanding the receptive field without excessive overhead. However, our preliminary experiments indicate that directly applying this global-local design to the classic deblurring task hinders accurate visual restoration, primarily due to the constrained global context understanding within local attention. To address this, we introduce a channel-aware module that complements local attention, effectively integrating global context without sacrificing pixel-level precision. The proposed DiNAT-IR, a Transformer-based architecture specifically designed for image restoration, achieves competitive results across multiple benchmarks, offering a high-quality solution for diverse low-level computer vision problems.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
DeblurDiNAT: A Lightweight and Effective Transformer for Image Deblurring
Mar 19, 2024



Blurry images may contain local and global non-uniform artifacts, which complicate the deblurring process and make it more challenging to achieve satisfactory results. Recently, Transformers generate improved deblurring outcomes than existing CNN architectures. However, the large model size and long inference time are still two bothersome issues which have not been fully explored. To this end, we propose DeblurDiNAT, a compact encoder-decoder Transformer which efficiently restores clean images from real-world blurry ones. We adopt an alternating dilation factor structure with the aim of global-local feature learning. Also, we observe that simply using self-attention layers in networks does not always produce good deblurred results. To solve this problem, we propose a channel modulation self-attention (CMSA) block, where a cross-channel learner (CCL) is utilized to capture channel relationships. In addition, we present a divide and multiply feed-forward network (DMFN) allowing fast feature propagation. Moreover, we design a lightweight gated feature fusion (LGFF) module, which performs controlled feature merging. Comprehensive experimental results show that the proposed model, named DeblurDiNAT, provides a favorable performance boost without introducing noticeable computational costs over the baseline, and achieves state-of-the-art (SOTA) performance on several image deblurring datasets. Compared to nearest competitors, our space-efficient and time-saving method demonstrates a stronger generalization ability with 3%-68% fewer parameters and produces deblurred images that are visually closer to the ground truth.
Dilated Fully Convolutional Neural Network for Depth Estimation from a Single Image
Mar 12, 2021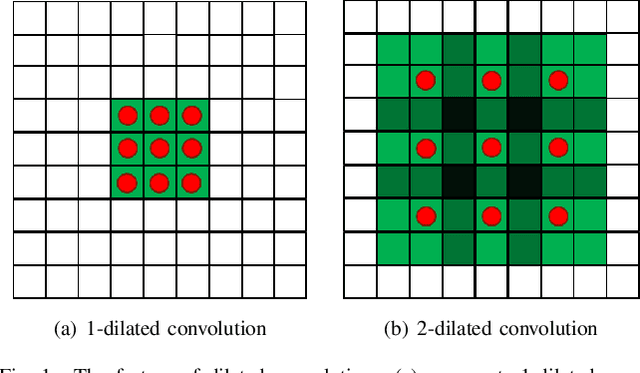
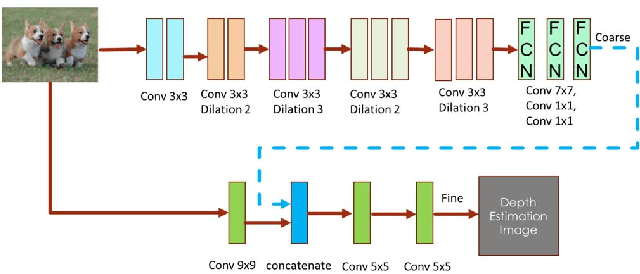


Depth prediction plays a key role in understanding a 3D scene. Several techniques have been developed throughout the years, among which Convolutional Neural Network has recently achieved state-of-the-art performance on estimating depth from a single image. However, traditional CNNs suffer from the lower resolution and information loss caused by the pooling layers. And oversized parameters generated from fully connected layers often lead to a exploded memory usage problem. In this paper, we present an advanced Dilated Fully Convolutional Neural Network to address the deficiencies. Taking advantages of the exponential expansion of the receptive field in dilated convolutions, our model can minimize the loss of resolution. It also reduces the amount of parameters significantly by replacing the fully connected layers with the fully convolutional layers. We show experimentally on NYU Depth V2 datasets that the depth prediction obtained from our model is considerably closer to ground truth than that from traditional CNNs techniques.
Advanced Multiple Linear Regression Based Dark Channel Prior Applied on Dehazing Image and Generating Synthetic Haze
Mar 12, 2021


Haze removal is an extremely challenging task, and object detection in the hazy environment has recently gained much attention due to the popularity of autonomous driving and traffic surveillance. In this work, the authors propose a multiple linear regression haze removal model based on a widely adopted dehazing algorithm named Dark Channel Prior. Training this model with a synthetic hazy dataset, the proposed model can reduce the unanticipated deviations generated from the rough estimations of transmission map and atmospheric light in Dark Channel Prior. To increase object detection accuracy in the hazy environment, the authors further present an algorithm to build a synthetic hazy COCO training dataset by generating the artificial haze to the MS COCO training dataset. The experimental results demonstrate that the proposed model obtains higher image quality and shares more similarity with ground truth images than most conventional pixel-based dehazing algorithms and neural network based haze-removal models. The authors also evaluate the mean average precision of Mask R-CNN when training the network with synthetic hazy COCO training dataset and preprocessing test hazy dataset by removing the haze with the proposed dehazing model. It turns out that both approaches can increase the object detection accuracy significantly and outperform most existing object detection models over hazy images.
Multiple Linear Regression Haze-removal Model Based on Dark Channel Prior
Apr 25, 2019



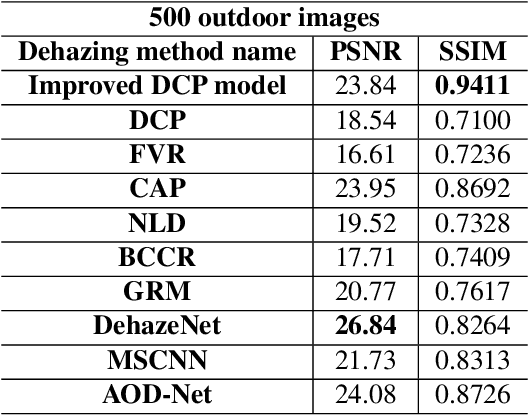
Dark Channel Prior (DCP) is a widely recognized traditional dehazing algorithm. However, it may fail in bright region and the brightness of the restored image is darker than hazy image. In this paper, we propose an effective method to optimize DCP. We build a multiple linear regression haze-removal model based on DCP atmospheric scattering model and train this model with RESIDE dataset, which aims to reduce the unexpected errors caused by the rough estimations of transmission map t(x) and atmospheric light A. The RESIDE dataset provides enough synthetic hazy images and their corresponding groundtruth images to train and test. We compare the performances of different dehazing algorithms in terms of two important full-reference metrics, the peak-signal-to-noise ratio (PSNR) as well as the structural similarity index measure (SSIM). The experiment results show that our model gets highest SSIM value and its PSNR value is also higher than most of state-of-the-art dehazing algorithms. Our results also overcome the weakness of DCP on real-world hazy images