 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransolver-3: Scaling Up Transformer Solvers to Industrial-Scale Geometries
Feb 04, 2026Deep learning has emerged as a transformative tool for the neural surrogate modeling of partial differential equations (PDEs), known as neural PDE solvers. However, scaling these solvers to industrial-scale geometries with over $10^8$ cells remains a fundamental challenge due to the prohibitive memory complexity of processing high-resolution meshes. We present Transolver-3, a new member of the Transolver family as a highly scalable framework designed for high-fidelity physics simulations. To bridge the gap between limited GPU capacity and the resolution requirements of complex engineering tasks, we introduce two key architectural optimizations: faster slice and deslice by exploiting matrix multiplication associative property and geometry slice tiling to partition the computation of physical states. Combined with an amortized training strategy by learning on random subsets of original high-resolution meshes and a physical state caching technique during inference, Transolver-3 enables high-fidelity field prediction on industrial-scale meshes. Extensive experiments demonstrate that Transolver-3 is capable of handling meshes with over 160 million cells, achieving impressive performance across three challenging simulation benchmarks, including aircraft and automotive design tasks.
An Empirical Study of World Model Quantization
Feb 02, 2026World models learn an internal representation of environment dynamics, enabling agents to simulate and reason about future states within a compact latent space for tasks such as planning, prediction, and inference. However, running world models rely on hevay computational cost and memory footprint, making model quantization essential for efficient deployment. To date, the effects of post-training quantization (PTQ) on world models remain largely unexamined. In this work, we present a systematic empirical study of world model quantization using DINO-WM as a representative case, evaluating diverse PTQ methods under both weight-only and joint weight-activation settings. We conduct extensive experiments on different visual planning tasks across a wide range of bit-widths, quantization granularities, and planning horizons up to 50 iterations. Our results show that quantization effects in world models extend beyond standard accuracy and bit-width trade-offs: group-wise weight quantization can stabilize low-bit rollouts, activation quantization granularity yields inconsistent benefits, and quantization sensitivity is highly asymmetric between encoder and predictor modules. Moreover, aggressive low-bit quantization significantly degrades the alignment between the planning objective and task success, leading to failures that cannot be remedied by additional optimization. These findings reveal distinct quantization-induced failure modes in world model-based planning and provide practical guidance for deploying quantized world models under strict computational constraints. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/QuantWM.
Physics-informed Diffusion Mamba Transformer for Real-world Driving
Jan 31, 2026Autonomous driving systems demand trajectory planners that not only model the inherent uncertainty of future motions but also respect complex temporal dependencies and underlying physical laws. While diffusion-based generative models excel at capturing multi-modal distributions, they often fail to incorporate long-term sequential contexts and domain-specific physical priors. In this work, we bridge these gaps with two key innovations. First, we introduce a Diffusion Mamba Transformer architecture that embeds mamba and attention into the diffusion process, enabling more effective aggregation of sequential input contexts from sensor streams and past motion histories. Second, we design a Port-Hamiltonian Neural Network module that seamlessly integrates energy-based physical constraints into the diffusion model, thereby enhancing trajectory predictions with both consistency and interpretability. Extensive evaluations on standard autonomous driving benchmarks demonstrate that our unified framework significantly outperforms state-of-the-art baselines in predictive accuracy, physical plausibility, and robustness, thereby advancing safe and reliable motion planning.
Theoretically Optimal Attention/FFN Ratios in Disaggregated LLM Serving
Jan 29, 2026Attention-FFN disaggregation (AFD) is an emerging architecture for LLM decoding that separates state-heavy, KV-cache-dominated Attention computation from stateless, compute-intensive FFN computation, connected by per-step communication. While AFD enables independent scaling of memory and compute resources, its performance is highly sensitive to the Attention/FFN provisioning ratio: mis-sizing induces step-level blocking and costly device idle time. We develop a tractable analytical framework for sizing AFD bundles in an $r$A-$1$F topology, where the key difficulty is that Attention-side work is nonstationary-token context grows and requests are continuously replenished with random lengths-while FFN work is stable given the aggregated batch. Using a probabilistic workload model, we derive closed-form rules for the optimal A/F ratio that maximize average throughput per instance across the system. A trace-calibrated AFD simulator validates the theory: across workloads, the theoretical optimal A/F ratio matches the simulation-optimal within 10%, and consistently reduces idle time.
On the static and small signal analysis of DAB converter
Jan 19, 2026This document develops a method to solve the periodic operating point of Dual-Active-Bridge (DAB).
Developing a Fundamental Diagram for Urban Air Mobility Based on Physical Experiments
Dec 24, 2025Urban Air Mobility (UAM) is an emerging application of unmanned aerial vehicles (UAVs) that promises to reduce travel time and alleviate congestion in urban transportation systems. As drone density increases, UAM operations are expected to experience congestion similar to that in ground traffic. However, the fundamental characteristics of UAM traffic flow, particularly under real-world operating conditions, remain poorly understood. This study proposes a general framework for constructing the fundamental diagram (FD) of UAM traffic by integrating theoretical analysis with physical experiments. To the best of our knowledge, this is the first study to derive a UAM FD using real-world physical test data. On the theoretical side, we design two drone control laws for collision avoidance and develop simulation-based traffic generation methods to produce diverse UAM traffic scenarios. Based on Edie's definition, traffic flow theory is then applied to construct the FD and characterize the macroscopic properties of UAM traffic. To account for real-world disturbances and modeling uncertainties, we further conduct physical experiments on a reduced-scale testbed using Bitcraze Crazyflie drones. Both simulation and physical test trajectory data are collected and organized into the UAMTra2Flow dataset, which is analyzed using the proposed framework. Preliminary results indicate that classical FD structures for ground transportation are also applicable to UAM systems. Notably, FD curves obtained from physical experiments exhibit deviations from simulation-based results, highlighting the importance of experimental validation. Finally, results from the reduced-scale testbed are scaled to realistic operating conditions to provide practical insights for future UAM traffic systems. The dataset and code for this paper are publicly available at https://github.com/CATS-Lab/UAM-FD.
VersatileFFN: Achieving Parameter Efficiency in LLMs via Adaptive Wide-and-Deep Reuse
Dec 16, 2025The rapid scaling of Large Language Models (LLMs) has achieved remarkable performance, but it also leads to prohibitive memory costs. Existing parameter-efficient approaches such as pruning and quantization mainly compress pretrained models without enhancing architectural capacity, thereby hitting the representational ceiling of the base model. In this work, we propose VersatileFFN, a novel feed-forward network (FFN) that enables flexible reuse of parameters in both width and depth dimensions within a fixed parameter budget. Inspired by the dual-process theory of cognition, VersatileFFN comprises two adaptive pathways: a width-versatile path that generates a mixture of sub-experts from a single shared FFN, mimicking sparse expert routing without increasing parameters, and a depth-versatile path that recursively applies the same FFN to emulate deeper processing for complex tokens. A difficulty-aware gating dynamically balances the two pathways, steering "easy" tokens through the efficient width-wise route and allocating deeper iterative refinement to "hard" tokens. Crucially, both pathways reuse the same parameters, so all additional capacity comes from computation rather than memory. Experiments across diverse benchmarks and model scales demonstrate the effectiveness of the method. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/VersatileFFN.
CATS-V2V: A Real-World Vehicle-to-Vehicle Cooperative Perception Dataset with Complex Adverse Traffic Scenarios
Nov 14, 2025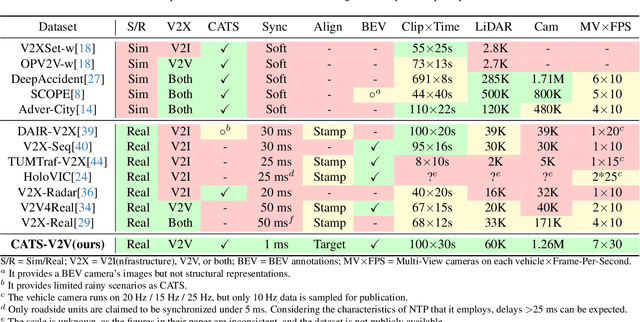


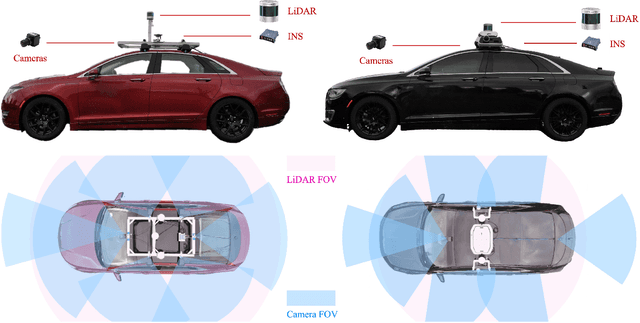
Vehicle-to-Vehicle (V2V) cooperative perception has great potential to enhance autonomous driving performance by overcoming perception limitations in complex adverse traffic scenarios (CATS). Meanwhile, data serves as the fundamental infrastructure for modern autonomous driving AI. However, due to stringent data collection requirements, existing datasets focus primarily on ordinary traffic scenarios, constraining the benefits of cooperative perception. To address this challenge, we introduce CATS-V2V, the first-of-its-kind real-world dataset for V2V cooperative perception under complex adverse traffic scenarios. The dataset was collected by two hardware time-synchronized vehicles, covering 10 weather and lighting conditions across 10 diverse locations. The 100-clip dataset includes 60K frames of 10 Hz LiDAR point clouds and 1.26M multi-view 30 Hz camera images, along with 750K anonymized yet high-precision RTK-fixed GNSS and IMU records. Correspondingly, we provide time-consistent 3D bounding box annotations for objects, as well as static scenes to construct a 4D BEV representation. On this basis, we propose a target-based temporal alignment method, ensuring that all objects are precisely aligned across all sensor modalities. We hope that CATS-V2V, the largest-scale, most supportive, and highest-quality dataset of its kind to date, will benefit the autonomous driving community in related tasks.
MRO: Enhancing Reasoning in Diffusion Language Models via Multi-Reward Optimization
Oct 24, 2025


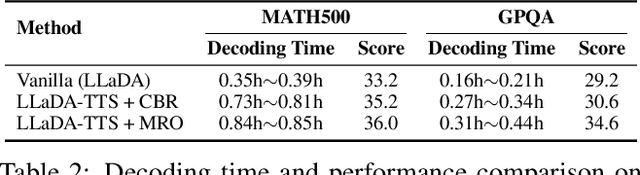
Recent advances in diffusion language models (DLMs) have presented a promising alternative to traditional autoregressive large language models (LLMs). However, DLMs still lag behind LLMs in reasoning performance, especially as the number of denoising steps decreases. Our analysis reveals that this shortcoming arises primarily from the independent generation of masked tokens across denoising steps, which fails to capture the token correlation. In this paper, we define two types of token correlation: intra-sequence correlation and inter-sequence correlation, and demonstrate that enhancing these correlations improves reasoning performance. To this end, we propose a Multi-Reward Optimization (MRO) approach, which encourages DLMs to consider the token correlation during the denoising process. More specifically, our MRO approach leverages test-time scaling, reject sampling, and reinforcement learning to directly optimize the token correlation with multiple elaborate rewards. Additionally, we introduce group step and importance sampling strategies to mitigate reward variance and enhance sampling efficiency. Through extensive experiments, we demonstrate that MRO not only improves reasoning performance but also achieves significant sampling speedups while maintaining high performance on reasoning benchmarks.
Revealing the Power of Post-Training for Small Language Models via Knowledge Distillation
Sep 30, 2025The rapid advancement of large language models (LLMs) has significantly advanced the capabilities of artificial intelligence across various domains. However, their massive scale and high computational costs render them unsuitable for direct deployment in resource-constrained edge environments. This creates a critical need for high-performance small models that can operate efficiently at the edge. Yet, after pre-training alone, these smaller models often fail to meet the performance requirements of complex tasks. To bridge this gap, we introduce a systematic post-training pipeline that efficiently enhances small model accuracy. Our post training pipeline consists of curriculum-based supervised fine-tuning (SFT) and offline on-policy knowledge distillation. The resulting instruction-tuned model achieves state-of-the-art performance among billion-parameter models, demonstrating strong generalization under strict hardware constraints while maintaining competitive accuracy across a variety of tasks. This work provides a practical and efficient solution for developing high-performance language models on Ascend edge devices.