 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV2UV: Generating High-quality UV Texture Maps with Multiview Prompts
Mar 16, 2026Generating high-quality textures for 3D assets is a challenging task. Existing multiview texture generation methods suffer from the multiview inconsistency and missing textures on unseen parts, while UV inpainting texture methods do not generalize well due to insufficient UV data and cannot well utilize 2D image diffusion priors. In this paper, we propose a new method called MV2UV that combines 2D generative priors from multiview generation and the inpainting ability of UV refinement to get high-quality texture maps. Our key idea is to adopt a UV space generative model that simultaneously inpaints unseen parts of multiview images while resolving the inconsistency of multiview images. Experiments show that our method enables a better texture generation quality than existing methods, especially in unseen occluded and multiview-inconsistent parts.
Video Anomaly Detection with Motion and Appearance Guided Patch Diffusion Model
Dec 12, 2024



A recent endeavor in one class of video anomaly detection is to leverage diffusion models and posit the task as a generation problem, where the diffusion model is trained to recover normal patterns exclusively, thus reporting abnormal patterns as outliers. Yet, existing attempts neglect the various formations of anomaly and predict normal samples at the feature level regardless that abnormal objects in surveillance videos are often relatively small. To address this, a novel patch-based diffusion model is proposed, specifically engineered to capture fine-grained local information. We further observe that anomalies in videos manifest themselves as deviations in both appearance and motion. Therefore, we argue that a comprehensive solution must consider both of these aspects simultaneously to achieve accurate frame prediction. To address this, we introduce innovative motion and appearance conditions that are seamlessly integrated into our patch diffusion model. These conditions are designed to guide the model in generating coherent and contextually appropriate predictions for both semantic content and motion relations. Experimental results in four challenging video anomaly detection datasets empirically substantiate the efficacy of our proposed approach, demonstrating that it consistently outperforms most existing methods in detecting abnormal behaviors.
Fine-grained Appearance Transfer with Diffusion Models
Nov 27, 2023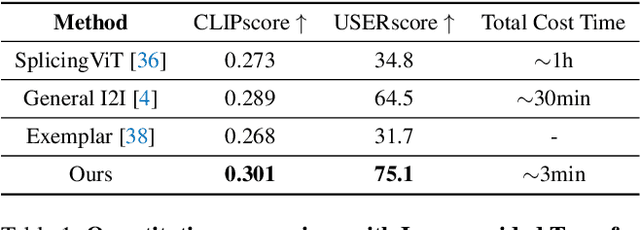

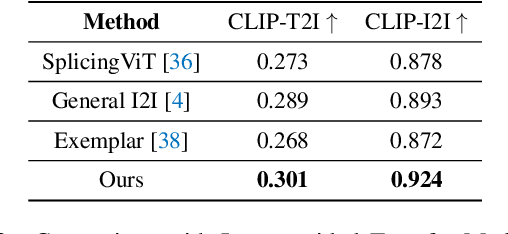
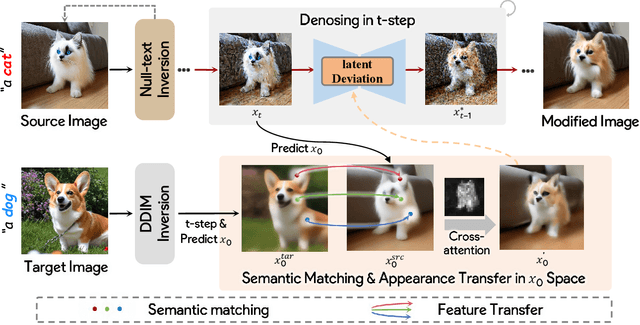
Image-to-image translation (I2I), and particularly its subfield of appearance transfer, which seeks to alter the visual appearance between images while maintaining structural coherence, presents formidable challenges. Despite significant advancements brought by diffusion models, achieving fine-grained transfer remains complex, particularly in terms of retaining detailed structural elements and ensuring information fidelity. This paper proposes an innovative framework designed to surmount these challenges by integrating various aspects of semantic matching, appearance transfer, and latent deviation. A pivotal aspect of our approach is the strategic use of the predicted $x_0$ space by diffusion models within the latent space of diffusion processes. This is identified as a crucial element for the precise and natural transfer of fine-grained details. Our framework exploits this space to accomplish semantic alignment between source and target images, facilitating mask-wise appearance transfer for improved feature acquisition. A significant advancement of our method is the seamless integration of these features into the latent space, enabling more nuanced latent deviations without necessitating extensive model retraining or fine-tuning. The effectiveness of our approach is demonstrated through extensive experiments, which showcase its ability to adeptly handle fine-grained appearance transfers across a wide range of categories and domains. We provide our code at https://github.com/babahui/Fine-grained-Appearance-Transfer
NeMF: Inverse Volume Rendering with Neural Microflake Field
Apr 04, 2023



Recovering the physical attributes of an object's appearance from its images captured under an unknown illumination is challenging yet essential for photo-realistic rendering. Recent approaches adopt the emerging implicit scene representations and have shown impressive results.However, they unanimously adopt a surface-based representation,and hence can not well handle scenes with very complex geometry, translucent object and etc. In this paper, we propose to conduct inverse volume rendering, in contrast to surface-based, by representing a scene using microflake volume, which assumes the space is filled with infinite small flakes and light reflects or scatters at each spatial location according to microflake distributions. We further adopt the coordinate networks to implicitly encode the microflake volume, and develop a differentiable microflake volume renderer to train the network in an end-to-end way in principle.Our NeMF enables effective recovery of appearance attributes for highly complex geometry and scattering object, enables high-quality relighting, material editing, and especially simulates volume rendering effects, such as scattering, which is infeasible for surface-based approaches.
Dynamic Feature Pruning and Consolidation for Occluded Person Re-Identification
Nov 27, 2022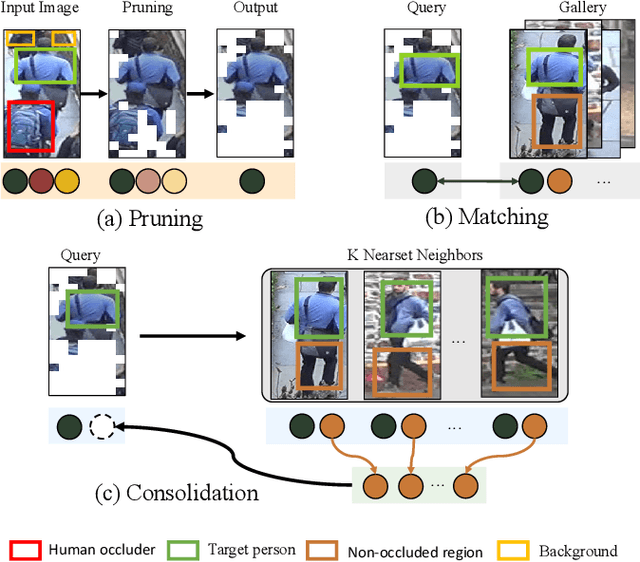
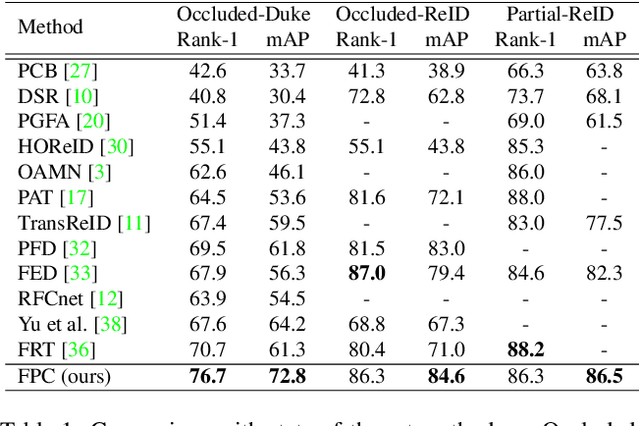
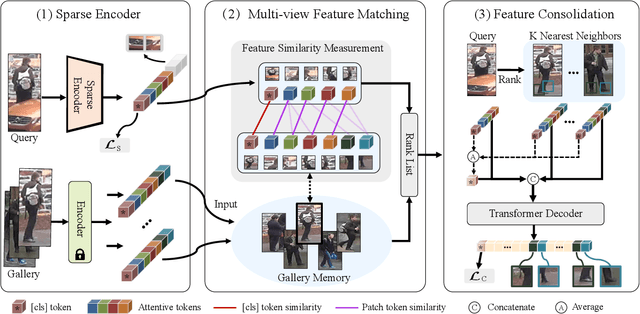
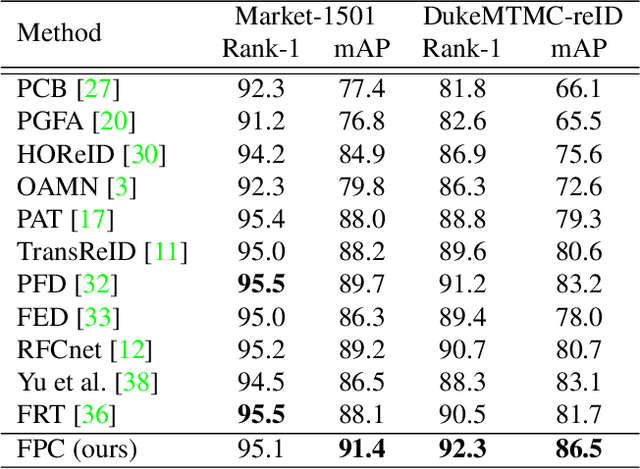
Occluded person re-identification (ReID) is a challenging problem due to contamination from occluders, and existing approaches address the issue with prior knowledge cues, eg human body key points, semantic segmentations and etc, which easily fails in the presents of heavy occlusion and other humans as occluders. In this paper, we propose a feature pruning and consolidation (FPC) framework to circumvent explicit human structure parse, which mainly consists of a sparse encoder, a global and local feature ranking module, and a feature consolidation decoder. Specifically, the sparse encoder drops less important image tokens (mostly related to background noise and occluders) solely according to correlation within the class token attention instead of relying on prior human shape information. Subsequently, the ranking stage relies on the preserved tokens produced by the sparse encoder to identify k-nearest neighbors from a pre-trained gallery memory by measuring the image and patch-level combined similarity. Finally, we use the feature consolidation module to compensate pruned features using identified neighbors for recovering essential information while disregarding disturbance from noise and occlusion. Experimental results demonstrate the effectiveness of our proposed framework on occluded, partial and holistic Re-ID datasets. In particular, our method outperforms state-of-the-art results by at least 8.6% mAP and 6.0% Rank-1 accuracy on the challenging Occluded-Duke dataset.