 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Anomaly Detection with Motion and Appearance Guided Patch Diffusion Model
Dec 12, 2024



A recent endeavor in one class of video anomaly detection is to leverage diffusion models and posit the task as a generation problem, where the diffusion model is trained to recover normal patterns exclusively, thus reporting abnormal patterns as outliers. Yet, existing attempts neglect the various formations of anomaly and predict normal samples at the feature level regardless that abnormal objects in surveillance videos are often relatively small. To address this, a novel patch-based diffusion model is proposed, specifically engineered to capture fine-grained local information. We further observe that anomalies in videos manifest themselves as deviations in both appearance and motion. Therefore, we argue that a comprehensive solution must consider both of these aspects simultaneously to achieve accurate frame prediction. To address this, we introduce innovative motion and appearance conditions that are seamlessly integrated into our patch diffusion model. These conditions are designed to guide the model in generating coherent and contextually appropriate predictions for both semantic content and motion relations. Experimental results in four challenging video anomaly detection datasets empirically substantiate the efficacy of our proposed approach, demonstrating that it consistently outperforms most existing methods in detecting abnormal behaviors.
Attacking Transformers with Feature Diversity Adversarial Perturbation
Mar 10, 2024Understanding the mechanisms behind Vision Transformer (ViT), particularly its vulnerability to adversarial perturba tions, is crucial for addressing challenges in its real-world applications. Existing ViT adversarial attackers rely on la bels to calculate the gradient for perturbation, and exhibit low transferability to other structures and tasks. In this paper, we present a label-free white-box attack approach for ViT-based models that exhibits strong transferability to various black box models, including most ViT variants, CNNs, and MLPs, even for models developed for other modalities. Our inspira tion comes from the feature collapse phenomenon in ViTs, where the critical attention mechanism overly depends on the low-frequency component of features, causing the features in middle-to-end layers to become increasingly similar and eventually collapse. We propose the feature diversity attacker to naturally accelerate this process and achieve remarkable performance and transferability.
Progressive Text-to-Image Diffusion with Soft Latent Direction
Sep 18, 2023



In spite of the rapidly evolving landscape of text-to-image generation, the synthesis and manipulation of multiple entities while adhering to specific relational constraints pose enduring challenges. This paper introduces an innovative progressive synthesis and editing operation that systematically incorporates entities into the target image, ensuring their adherence to spatial and relational constraints at each sequential step. Our key insight stems from the observation that while a pre-trained text-to-image diffusion model adeptly handles one or two entities, it often falters when dealing with a greater number. To address this limitation, we propose harnessing the capabilities of a Large Language Model (LLM) to decompose intricate and protracted text descriptions into coherent directives adhering to stringent formats. To facilitate the execution of directives involving distinct semantic operations-namely insertion, editing, and erasing-we formulate the Stimulus, Response, and Fusion (SRF) framework. Within this framework, latent regions are gently stimulated in alignment with each operation, followed by the fusion of the responsive latent components to achieve cohesive entity manipulation. Our proposed framework yields notable advancements in object synthesis, particularly when confronted with intricate and lengthy textual inputs. Consequently, it establishes a new benchmark for text-to-image generation tasks, further elevating the field's performance standards.
Multi-level Memory-augmented Appearance-Motion Correspondence Framework for Video Anomaly Detection
Mar 09, 2023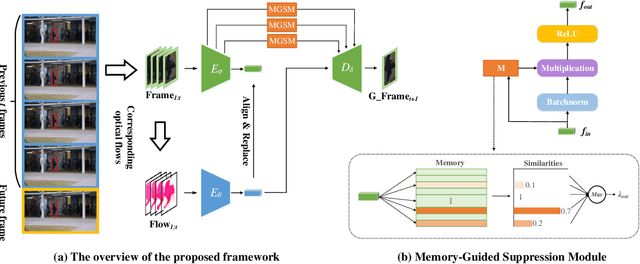



Frame prediction based on AutoEncoder plays a significant role in unsupervised video anomaly detection. Ideally, the models trained on the normal data could generate larger prediction errors of anomalies. However, the correlation between appearance and motion information is underutilized, which makes the models lack an understanding of normal patterns. Moreover, the models do not work well due to the uncontrollable generalizability of deep AutoEncoder. To tackle these problems, we propose a multi-level memory-augmented appearance-motion correspondence framework. The latent correspondence between appearance and motion is explored via appearance-motion semantics alignment and semantics replacement training. Besides, we also introduce a Memory-Guided Suppression Module, which utilizes the difference from normal prototype features to suppress the reconstruction capacity caused by skip-connection, achieving the tradeoff between the good reconstruction of normal data and the poor reconstruction of abnormal data. Experimental results show that our framework outperforms the state-of-the-art methods, achieving AUCs of 99.6\%, 93.8\%, and 76.3\% on UCSD Ped2, CUHK Avenue, and ShanghaiTech datasets.
Synthetic Pseudo Anomalies for Unsupervised Video Anomaly Detection: A Simple yet Efficient Framework based on Masked Autoencoder
Mar 09, 2023



Due to the limited availability of anomalous samples for training, video anomaly detection is commonly viewed as a one-class classification problem. Many prevalent methods investigate the reconstruction difference produced by AutoEncoders (AEs) under the assumption that the AEs would reconstruct the normal data well while reconstructing anomalies poorly. However, even with only normal data training, the AEs often reconstruct anomalies well, which depletes their anomaly detection performance. To alleviate this issue, we propose a simple yet efficient framework for video anomaly detection. The pseudo anomaly samples are introduced, which are synthesized from only normal data by embedding random mask tokens without extra data processing. We also propose a normalcy consistency training strategy that encourages the AEs to better learn the regular knowledge from normal and corresponding pseudo anomaly data. This way, the AEs learn more distinct reconstruction boundaries between normal and abnormal data, resulting in superior anomaly discrimination capability. Experimental results demonstrate the effectiveness of the proposed method.