 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Memory-augmented Appearance-Motion Correspondence Framework for Video Anomaly Detection
Mar 09, 2023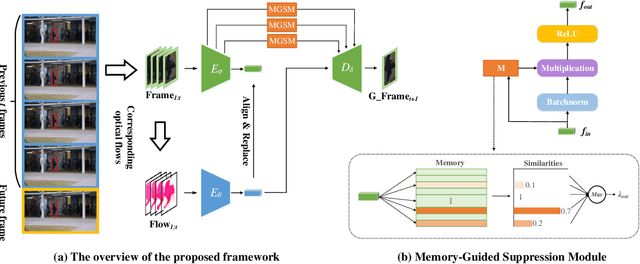



Frame prediction based on AutoEncoder plays a significant role in unsupervised video anomaly detection. Ideally, the models trained on the normal data could generate larger prediction errors of anomalies. However, the correlation between appearance and motion information is underutilized, which makes the models lack an understanding of normal patterns. Moreover, the models do not work well due to the uncontrollable generalizability of deep AutoEncoder. To tackle these problems, we propose a multi-level memory-augmented appearance-motion correspondence framework. The latent correspondence between appearance and motion is explored via appearance-motion semantics alignment and semantics replacement training. Besides, we also introduce a Memory-Guided Suppression Module, which utilizes the difference from normal prototype features to suppress the reconstruction capacity caused by skip-connection, achieving the tradeoff between the good reconstruction of normal data and the poor reconstruction of abnormal data. Experimental results show that our framework outperforms the state-of-the-art methods, achieving AUCs of 99.6\%, 93.8\%, and 76.3\% on UCSD Ped2, CUHK Avenue, and ShanghaiTech datasets.
Updated version: A Video Anomaly Detection Framework based on Appearance-Motion Semantics Representation Consistency
Mar 09, 2023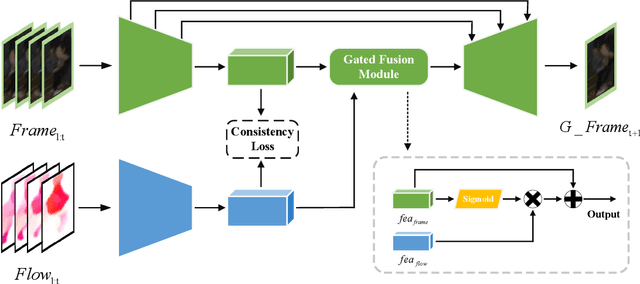
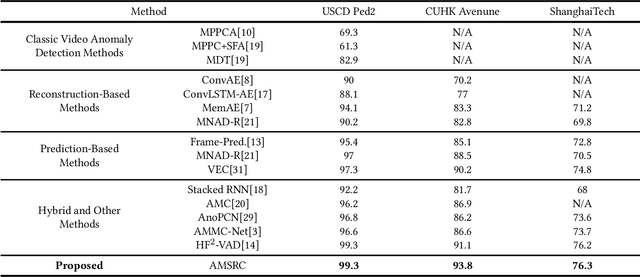
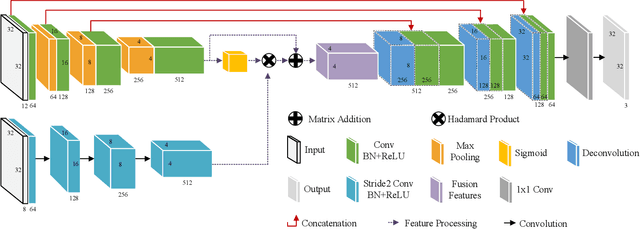
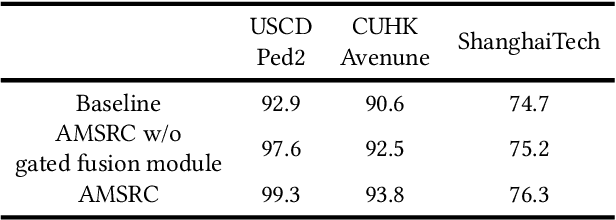
Video anomaly detection is an essential but challenging task. The prevalent methods mainly investigate the reconstruction difference between normal and abnormal patterns but ignore the semantics consistency between appearance and motion information of behavior patterns, making the results highly dependent on the local context of frame sequences and lacking the understanding of behavior semantics. To address this issue, we propose a framework of Appearance-Motion Semantics Representation Consistency that uses the gap of appearance and motion semantic representation consistency between normal and abnormal data. The two-stream structure is designed to encode the appearance and motion information representation of normal samples, and a novel consistency loss is proposed to enhance the consistency of feature semantics so that anomalies with low consistency can be identified. Moreover, the lower consistency features of anomalies can be used to deteriorate the quality of the predicted frame, which makes anomalies easier to spot. Experimental results demonstrate the effectiveness of the proposed method.
Synthetic Pseudo Anomalies for Unsupervised Video Anomaly Detection: A Simple yet Efficient Framework based on Masked Autoencoder
Mar 09, 2023



Due to the limited availability of anomalous samples for training, video anomaly detection is commonly viewed as a one-class classification problem. Many prevalent methods investigate the reconstruction difference produced by AutoEncoders (AEs) under the assumption that the AEs would reconstruct the normal data well while reconstructing anomalies poorly. However, even with only normal data training, the AEs often reconstruct anomalies well, which depletes their anomaly detection performance. To alleviate this issue, we propose a simple yet efficient framework for video anomaly detection. The pseudo anomaly samples are introduced, which are synthesized from only normal data by embedding random mask tokens without extra data processing. We also propose a normalcy consistency training strategy that encourages the AEs to better learn the regular knowledge from normal and corresponding pseudo anomaly data. This way, the AEs learn more distinct reconstruction boundaries between normal and abnormal data, resulting in superior anomaly discrimination capability. Experimental results demonstrate the effectiveness of the proposed method.
A Video Anomaly Detection Framework based on Appearance-Motion Semantics Representation Consistency
Apr 08, 2022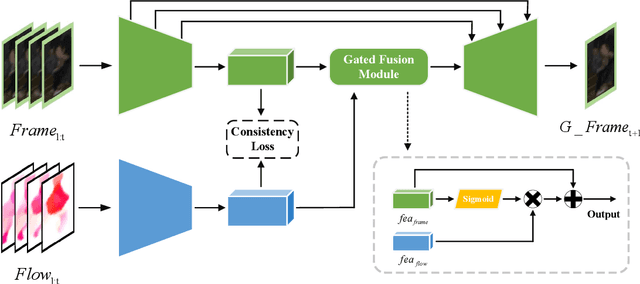
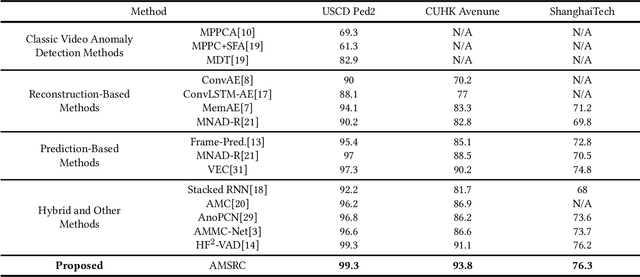
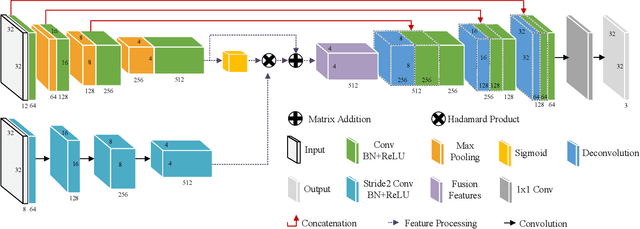
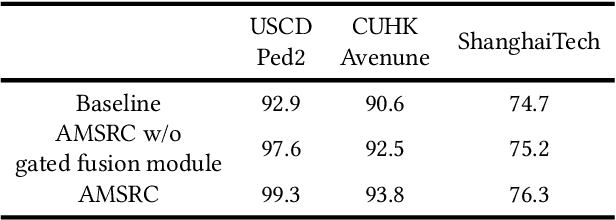
Video anomaly detection refers to the identification of events that deviate from the expected behavior. Due to the lack of anomalous samples in training, video anomaly detection becomes a very challenging task. Existing methods almost follow a reconstruction or future frame prediction mode. However, these methods ignore the consistency between appearance and motion information of samples, which limits their anomaly detection performance. Anomalies only occur in the moving foreground of surveillance videos, so the semantics expressed by video frame sequences and optical flow without background information in anomaly detection should be highly consistent and significant for anomaly detection. Based on this idea, we propose Appearance-Motion Semantics Representation Consistency (AMSRC), a framework that uses normal data's appearance and motion semantic representation consistency to handle anomaly detection. Firstly, we design a two-stream encoder to encode the appearance and motion information representations of normal samples and introduce constraints to further enhance the consistency of the feature semantics between appearance and motion information of normal samples so that abnormal samples with low consistency appearance and motion feature representation can be identified. Moreover, the lower consistency of appearance and motion features of anomalous samples can be used to generate predicted frames with larger reconstruction error, which makes anomalies easier to spot. Experimental results demonstrate the effectiveness of the proposed method.