 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Refiner: Boosting Feed-forward Novel View Synthesis via One-Step Diffusion
Jan 20, 2026We present a novel framework for high-fidelity novel view synthesis (NVS) from sparse images, addressing key limitations in recent feed-forward 3D Gaussian Splatting (3DGS) methods built on Vision Transformer (ViT) backbones. While ViT-based pipelines offer strong geometric priors, they are often constrained by low-resolution inputs due to computational costs. Moreover, existing generative enhancement methods tend to be 3D-agnostic, resulting in inconsistent structures across views, especially in unseen regions. To overcome these challenges, we design a Dual-Domain Detail Perception Module, which enables handling high-resolution images without being limited by the ViT backbone, and endows Gaussians with additional features to store high-frequency details. We develop a feature-guided diffusion network, which can preserve high-frequency details during the restoration process. We introduce a unified training strategy that enables joint optimization of the ViT-based geometric backbone and the diffusion-based refinement module. Experiments demonstrate that our method can maintain superior generation quality across multiple datasets.
OMGSR: You Only Need One Mid-timestep Guidance for Real-World Image Super-Resolution
Aug 11, 2025Denoising Diffusion Probabilistic Models (DDPM) and Flow Matching (FM) generative models show promising potential for one-step Real-World Image Super-Resolution (Real-ISR). Recent one-step Real-ISR models typically inject a Low-Quality (LQ) image latent distribution at the initial timestep. However, a fundamental gap exists between the LQ image latent distribution and the Gaussian noisy latent distribution, limiting the effective utilization of generative priors. We observe that the noisy latent distribution at DDPM/FM mid-timesteps aligns more closely with the LQ image latent distribution. Based on this insight, we present One Mid-timestep Guidance Real-ISR (OMGSR), a universal framework applicable to DDPM/FM-based generative models. OMGSR injects the LQ image latent distribution at a pre-computed mid-timestep, incorporating the proposed Latent Distribution Refinement loss to alleviate the latent distribution gap. We also design the Overlap-Chunked LPIPS/GAN loss to eliminate checkerboard artifacts in image generation. Within this framework, we instantiate OMGSR for DDPM/FM-based generative models with two variants: OMGSR-S (SD-Turbo) and OMGSR-F (FLUX.1-dev). Experimental results demonstrate that OMGSR-S/F achieves balanced/excellent performance across quantitative and qualitative metrics at 512-resolution. Notably, OMGSR-F establishes overwhelming dominance in all reference metrics. We further train a 1k-resolution OMGSR-F to match the default resolution of FLUX.1-dev, which yields excellent results, especially in the details of the image generation. We also generate 2k-resolution images by the 1k-resolution OMGSR-F using our two-stage Tiled VAE & Diffusion.
Relaxed Rotational Equivariance via $G$-Biases in Vision
Aug 25, 2024



Group Equivariant Convolution (GConv) can effectively handle rotational symmetry data. They assume uniform and strict rotational symmetry across all features, as the transformations under the specific group. However, real-world data rarely conforms to strict rotational symmetry commonly referred to as Rotational Symmetry-Breaking in the system or dataset, making GConv unable to adapt effectively to this phenomenon. Motivated by this, we propose a simple but highly effective method to address this problem, which utilizes a set of learnable biases called the $G$-Biases under the group order to break strict group constraints and achieve \textbf{R}elaxed \textbf{R}otational \textbf{E}quivarant \textbf{Conv}olution (RREConv). We conduct extensive experiments to validate Relaxed Rotational Equivariance on rotational symmetry groups $\mathcal{C}_n$ (e.g. $\mathcal{C}_2$, $\mathcal{C}_4$, and $\mathcal{C}_6$ groups). Further experiments demonstrate that our proposed RREConv-based methods achieve excellent performance, compared to existing GConv-based methods in classification and detection tasks on natural image datasets.
SBDet: A Symmetry-Breaking Object Detector via Relaxed Rotation-Equivariance
Aug 21, 2024



Introducing Group Equivariant Convolution (GConv) empowers models to explore symmetries hidden in visual data, improving their performance. However, in real-world scenarios, objects or scenes often exhibit perturbations of a symmetric system, specifically a deviation from a symmetric architecture, which can be characterized by a non-trivial action of a symmetry group, known as Symmetry-Breaking. Traditional GConv methods are limited by the strict operation rules in the group space, only ensuring features remain strictly equivariant under limited group transformations, making it difficult to adapt to Symmetry-Breaking or non-rigid transformations. Motivated by this, we introduce a novel Relaxed Rotation GConv (R2GConv) with our defined Relaxed Rotation-Equivariant group $\mathbf{R}_4$. Furthermore, we propose a Relaxed Rotation-Equivariant Network (R2Net) as the backbone and further develop the Symmetry-Breaking Object Detector (SBDet) for 2D object detection built upon it. Experiments demonstrate the effectiveness of our proposed R2GConv in natural image classification tasks, and SBDet achieves excellent performance in object detection tasks with improved generalization capabilities and robustness.
UC-NeRF: Neural Radiance Field for Under-Calibrated multi-view cameras in autonomous driving
Nov 28, 2023Multi-camera setups find widespread use across various applications, such as autonomous driving, as they greatly expand sensing capabilities. Despite the fast development of Neural radiance field (NeRF) techniques and their wide applications in both indoor and outdoor scenes, applying NeRF to multi-camera systems remains very challenging. This is primarily due to the inherent under-calibration issues in multi-camera setup, including inconsistent imaging effects stemming from separately calibrated image signal processing units in diverse cameras, and system errors arising from mechanical vibrations during driving that affect relative camera poses. In this paper, we present UC-NeRF, a novel method tailored for novel view synthesis in under-calibrated multi-view camera systems. Firstly, we propose a layer-based color correction to rectify the color inconsistency in different image regions. Second, we propose virtual warping to generate more viewpoint-diverse but color-consistent virtual views for color correction and 3D recovery. Finally, a spatiotemporally constrained pose refinement is designed for more robust and accurate pose calibration in multi-camera systems. Our method not only achieves state-of-the-art performance of novel view synthesis in multi-camera setups, but also effectively facilitates depth estimation in large-scale outdoor scenes with the synthesized novel views.
Updated version: A Video Anomaly Detection Framework based on Appearance-Motion Semantics Representation Consistency
Mar 09, 2023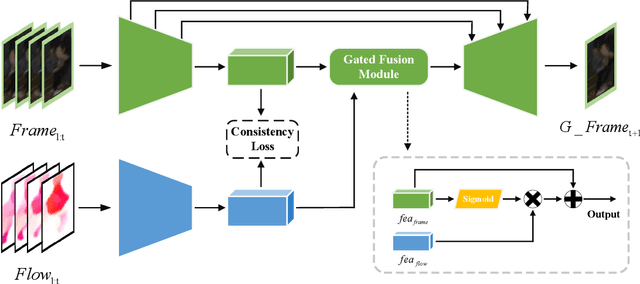
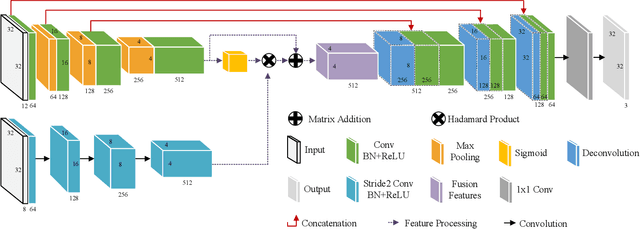
Video anomaly detection is an essential but challenging task. The prevalent methods mainly investigate the reconstruction difference between normal and abnormal patterns but ignore the semantics consistency between appearance and motion information of behavior patterns, making the results highly dependent on the local context of frame sequences and lacking the understanding of behavior semantics. To address this issue, we propose a framework of Appearance-Motion Semantics Representation Consistency that uses the gap of appearance and motion semantic representation consistency between normal and abnormal data. The two-stream structure is designed to encode the appearance and motion information representation of normal samples, and a novel consistency loss is proposed to enhance the consistency of feature semantics so that anomalies with low consistency can be identified. Moreover, the lower consistency features of anomalies can be used to deteriorate the quality of the predicted frame, which makes anomalies easier to spot. Experimental results demonstrate the effectiveness of the proposed method.
Multi-level Memory-augmented Appearance-Motion Correspondence Framework for Video Anomaly Detection
Mar 09, 2023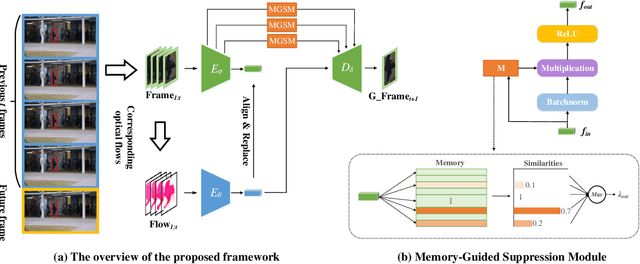



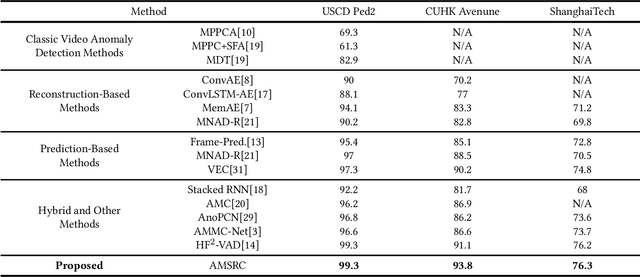
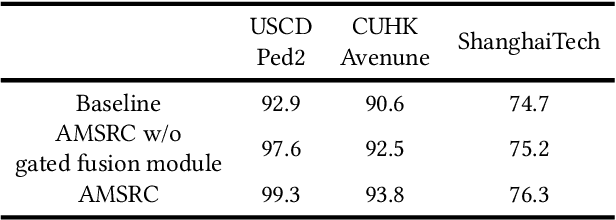
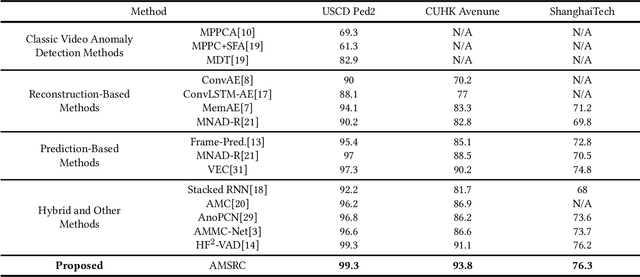
Frame prediction based on AutoEncoder plays a significant role in unsupervised video anomaly detection. Ideally, the models trained on the normal data could generate larger prediction errors of anomalies. However, the correlation between appearance and motion information is underutilized, which makes the models lack an understanding of normal patterns. Moreover, the models do not work well due to the uncontrollable generalizability of deep AutoEncoder. To tackle these problems, we propose a multi-level memory-augmented appearance-motion correspondence framework. The latent correspondence between appearance and motion is explored via appearance-motion semantics alignment and semantics replacement training. Besides, we also introduce a Memory-Guided Suppression Module, which utilizes the difference from normal prototype features to suppress the reconstruction capacity caused by skip-connection, achieving the tradeoff between the good reconstruction of normal data and the poor reconstruction of abnormal data. Experimental results show that our framework outperforms the state-of-the-art methods, achieving AUCs of 99.6\%, 93.8\%, and 76.3\% on UCSD Ped2, CUHK Avenue, and ShanghaiTech datasets.
Synthetic Pseudo Anomalies for Unsupervised Video Anomaly Detection: A Simple yet Efficient Framework based on Masked Autoencoder
Mar 09, 2023



Due to the limited availability of anomalous samples for training, video anomaly detection is commonly viewed as a one-class classification problem. Many prevalent methods investigate the reconstruction difference produced by AutoEncoders (AEs) under the assumption that the AEs would reconstruct the normal data well while reconstructing anomalies poorly. However, even with only normal data training, the AEs often reconstruct anomalies well, which depletes their anomaly detection performance. To alleviate this issue, we propose a simple yet efficient framework for video anomaly detection. The pseudo anomaly samples are introduced, which are synthesized from only normal data by embedding random mask tokens without extra data processing. We also propose a normalcy consistency training strategy that encourages the AEs to better learn the regular knowledge from normal and corresponding pseudo anomaly data. This way, the AEs learn more distinct reconstruction boundaries between normal and abnormal data, resulting in superior anomaly discrimination capability. Experimental results demonstrate the effectiveness of the proposed method.
Rate-Perception Optimized Preprocessing for Video Coding
Jan 25, 2023In the past decades, lots of progress have been done in the video compression field including traditional video codec and learning-based video codec. However, few studies focus on using preprocessing techniques to improve the rate-distortion performance. In this paper, we propose a rate-perception optimized preprocessing (RPP) method. We first introduce an adaptive Discrete Cosine Transform loss function which can save the bitrate and keep essential high frequency components as well. Furthermore, we also combine several state-of-the-art techniques from low-level vision fields into our approach, such as the high-order degradation model, efficient lightweight network design, and Image Quality Assessment model. By jointly using these powerful techniques, our RPP approach can achieve on average, 16.27% bitrate saving with different video encoders like AVC, HEVC, and VVC under multiple quality metrics. In the deployment stage, our RPP method is very simple and efficient which is not required any changes in the setting of video encoding, streaming, and decoding. Each input frame only needs to make a single pass through RPP before sending into video encoders. In addition, in our subjective visual quality test, 87% of users think videos with RPP are better or equal to videos by only using the codec to compress, while these videos with RPP save about 12% bitrate on average. Our RPP framework has been integrated into the production environment of our video transcoding services which serve millions of users every day.
A Video Anomaly Detection Framework based on Appearance-Motion Semantics Representation Consistency
Apr 08, 2022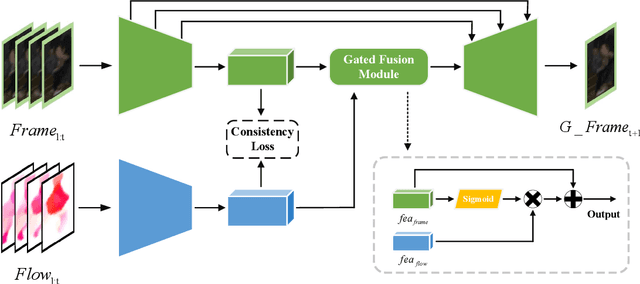
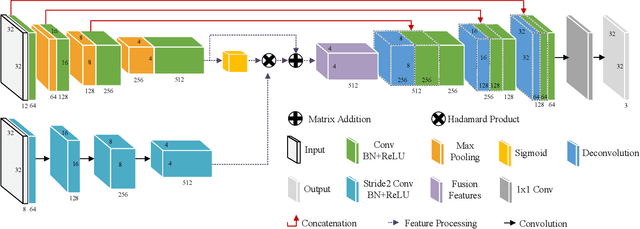
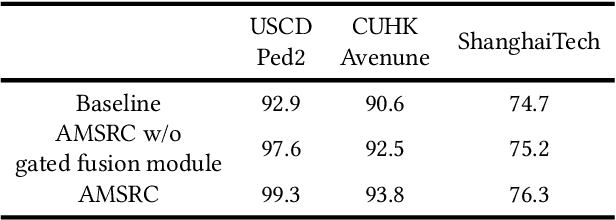
Video anomaly detection refers to the identification of events that deviate from the expected behavior. Due to the lack of anomalous samples in training, video anomaly detection becomes a very challenging task. Existing methods almost follow a reconstruction or future frame prediction mode. However, these methods ignore the consistency between appearance and motion information of samples, which limits their anomaly detection performance. Anomalies only occur in the moving foreground of surveillance videos, so the semantics expressed by video frame sequences and optical flow without background information in anomaly detection should be highly consistent and significant for anomaly detection. Based on this idea, we propose Appearance-Motion Semantics Representation Consistency (AMSRC), a framework that uses normal data's appearance and motion semantic representation consistency to handle anomaly detection. Firstly, we design a two-stream encoder to encode the appearance and motion information representations of normal samples and introduce constraints to further enhance the consistency of the feature semantics between appearance and motion information of normal samples so that abnormal samples with low consistency appearance and motion feature representation can be identified. Moreover, the lower consistency of appearance and motion features of anomalous samples can be used to generate predicted frames with larger reconstruction error, which makes anomalies easier to spot. Experimental results demonstrate the effectiveness of the proposed method.