 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models in Decision Making: A Survey
Feb 25, 2025In recent years, the exceptional performance of generative models in generative tasks has sparked significant interest in their integration into decision-making processes. Due to their ability to handle complex data distributions and their strong model capacity, generative models can be effectively incorporated into decision-making systems by generating trajectories that guide agents toward high-reward state-action regions or intermediate sub-goals. This paper presents a comprehensive review of the application of generative models in decision-making tasks. We classify seven fundamental types of generative models: energy-based models, generative adversarial networks, variational autoencoders, normalizing flows, diffusion models, generative flow networks, and autoregressive models. Regarding their applications, we categorize their functions into three main roles: controllers, modelers and optimizers, and discuss how each role contributes to decision-making. Furthermore, we examine the deployment of these models across five critical real-world decision-making scenarios. Finally, we summarize the strengths and limitations of current approaches and propose three key directions for advancing next-generation generative directive models: high-performance algorithms, large-scale generalized decision-making models, and self-evolving and adaptive models.
Unicorn: Unified Neural Image Compression with One Number Reconstruction
Dec 11, 2024Prevalent lossy image compression schemes can be divided into: 1) explicit image compression (EIC), including traditional standards and neural end-to-end algorithms; 2) implicit image compression (IIC) based on implicit neural representations (INR). The former is encountering impasses of either leveling off bitrate reduction at a cost of tremendous complexity while the latter suffers from excessive smoothing quality as well as lengthy decoder models. In this paper, we propose an innovative paradigm, which we dub \textbf{Unicorn} (\textbf{U}nified \textbf{N}eural \textbf{I}mage \textbf{C}ompression with \textbf{O}ne \textbf{N}number \textbf{R}econstruction). By conceptualizing the images as index-image pairs and learning the inherent distribution of pairs in a subtle neural network model, Unicorn can reconstruct a visually pleasing image from a randomly generated noise with only one index number. The neural model serves as the unified decoder of images while the noises and indexes corresponds to explicit representations. As a proof of concept, we propose an effective and efficient prototype of Unicorn based on latent diffusion models with tailored model designs. Quantitive and qualitative experimental results demonstrate that our prototype achieves significant bitrates reduction compared with EIC and IIC algorithms. More impressively, benefitting from the unified decoder, our compression ratio escalates as the quantity of images increases. We envision that more advanced model designs will endow Unicorn with greater potential in image compression. We will release our codes in \url{https://github.com/uniqzheng/Unicorn-Laduree}.
Private Wasserstein Distance with Random Noises
Apr 10, 2024Wasserstein distance is a principle measure of data divergence from a distributional standpoint. However, its application becomes challenging in the context of data privacy, where sharing raw data is restricted. Prior attempts have employed techniques like Differential Privacy or Federated optimization to approximate Wasserstein distance. Nevertheless, these approaches often lack accuracy and robustness against potential attack. In this study, we investigate the underlying triangular properties within the Wasserstein space, leading to a straightforward solution named TriangleWad. This approach enables the computation of Wasserstein distance between datasets stored across different entities. Notably, TriangleWad is 20 times faster, making raw data information truly invisible, enhancing resilience against attacks, and without sacrificing estimation accuracy. Through comprehensive experimentation across various tasks involving both image and text data, we demonstrate its superior performance and generalizations.
Meta Generative Flow Networks with Personalization for Task-Specific Adaptation
Jun 16, 2023Multi-task reinforcement learning and meta-reinforcement learning have been developed to quickly adapt to new tasks, but they tend to focus on tasks with higher rewards and more frequent occurrences, leading to poor performance on tasks with sparse rewards. To address this issue, GFlowNets can be integrated into meta-learning algorithms (GFlowMeta) by leveraging the advantages of GFlowNets on tasks with sparse rewards. However, GFlowMeta suffers from performance degradation when encountering heterogeneous transitions from distinct tasks. To overcome this challenge, this paper proposes a personalized approach named pGFlowMeta, which combines task-specific personalized policies with a meta policy. Each personalized policy balances the loss on its personalized task and the difference from the meta policy, while the meta policy aims to minimize the average loss of all tasks. The theoretical analysis shows that the algorithm converges at a sublinear rate. Extensive experiments demonstrate that the proposed algorithm outperforms state-of-the-art reinforcement learning algorithms in discrete environments.
Multi-agent Policy Reciprocity with Theoretical Guarantee
Apr 12, 2023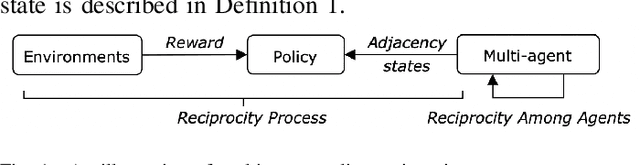
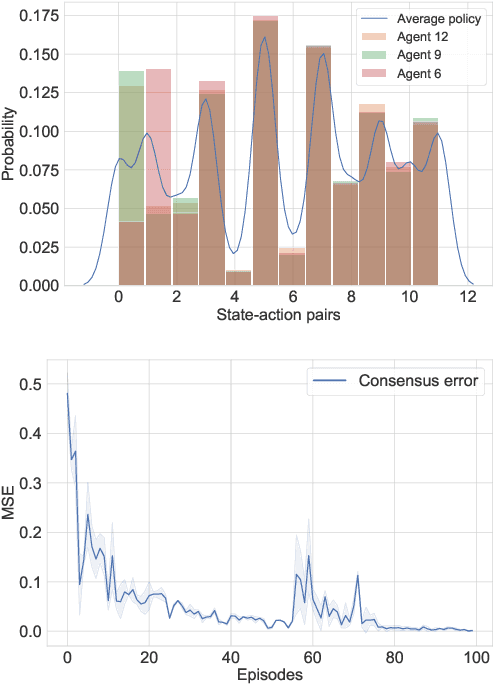
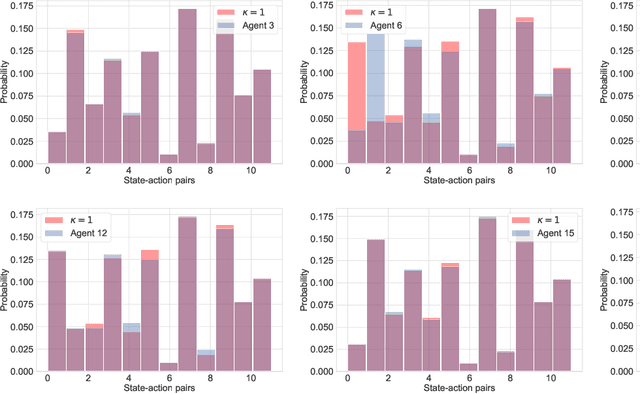
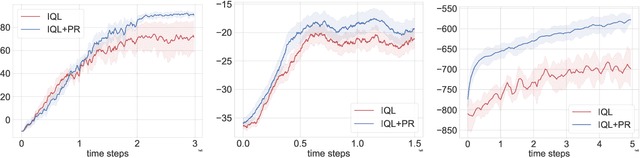
Modern multi-agent reinforcement learning (RL) algorithms hold great potential for solving a variety of real-world problems. However, they do not fully exploit cross-agent knowledge to reduce sample complexity and improve performance. Although transfer RL supports knowledge sharing, it is hyperparameter sensitive and complex. To solve this problem, we propose a novel multi-agent policy reciprocity (PR) framework, where each agent can fully exploit cross-agent policies even in mismatched states. We then define an adjacency space for mismatched states and design a plug-and-play module for value iteration, which enables agents to infer more precise returns. To improve the scalability of PR, deep PR is proposed for continuous control tasks. Moreover, theoretical analysis shows that agents can asymptotically reach consensus through individual perceived rewards and converge to an optimal value function, which implies the stability and effectiveness of PR, respectively. Experimental results on discrete and continuous environments demonstrate that PR outperforms various existing RL and transfer RL methods.
CFlowNets: Continuous Control with Generative Flow Networks
Mar 04, 2023Generative flow networks (GFlowNets), as an emerging technique, can be used as an alternative to reinforcement learning for exploratory control tasks. GFlowNet aims to generate distribution proportional to the rewards over terminating states, and to sample different candidates in an active learning fashion. GFlowNets need to form a DAG and compute the flow matching loss by traversing the inflows and outflows of each node in the trajectory. No experiments have yet concluded that GFlowNets can be used to handle continuous tasks. In this paper, we propose generative continuous flow networks (CFlowNets) that can be applied to continuous control tasks. First, we present the theoretical formulation of CFlowNets. Then, a training framework for CFlowNets is proposed, including the action selection process, the flow approximation algorithm, and the continuous flow matching loss function. Afterward, we theoretically prove the error bound of the flow approximation. The error decreases rapidly as the number of flow samples increases. Finally, experimental results on continuous control tasks demonstrate the performance advantages of CFlowNets compared to many reinforcement learning methods, especially regarding exploration ability.
On the Convergence Theory of Meta Reinforcement Learning with Personalized Policies
Sep 21, 2022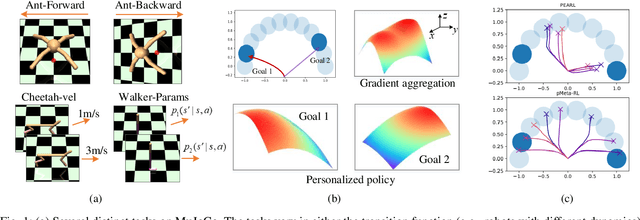

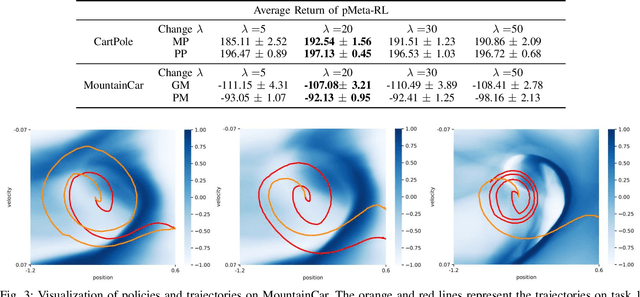
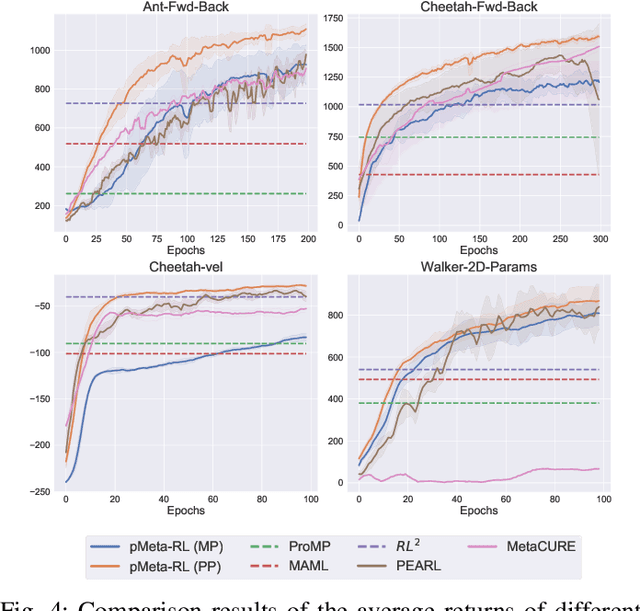
Modern meta-reinforcement learning (Meta-RL) methods are mainly developed based on model-agnostic meta-learning, which performs policy gradient steps across tasks to maximize policy performance. However, the gradient conflict problem is still poorly understood in Meta-RL, which may lead to performance degradation when encountering distinct tasks. To tackle this challenge, this paper proposes a novel personalized Meta-RL (pMeta-RL) algorithm, which aggregates task-specific personalized policies to update a meta-policy used for all tasks, while maintaining personalized policies to maximize the average return of each task under the constraint of the meta-policy. We also provide the theoretical analysis under the tabular setting, which demonstrates the convergence of our pMeta-RL algorithm. Moreover, we extend the proposed pMeta-RL algorithm to a deep network version based on soft actor-critic, making it suitable for continuous control tasks. Experiment results show that the proposed algorithms outperform other previous Meta-RL algorithms on Gym and MuJoCo suites.
Manifold Optimization Based Multi-user Rate Maximization Aided by Intelligent Reflecting Surface
Jan 22, 2022

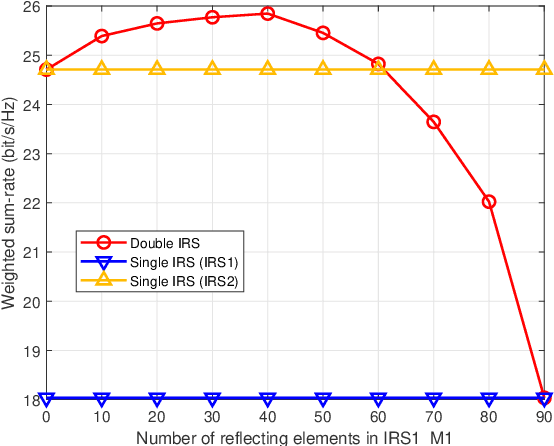

In this work, two problems associated with a downlink multi-user system are considered with the aid of intelligent reflecting surface (IRS): weighted sum-rate maximization and weighted minimal-rate maximization. For the first problem, a novel DOuble Manifold ALternating Optimization (DOMALO) algorithm is proposed by exploiting the matrix manifold theory and introducing the beamforming matrix and reflection vector using complex sphere manifold and complex oblique manifold, respectively, which incorporate the inherent geometrical structure and the required constraint. A smooth double manifold alternating optimization (S-DOMALO) algorithm is then developed based on the Dinkelbach-type algorithm and smooth exponential penalty function for the second problem. Finally, possible cooperative beamforming gain between IRSs and the IRS phase shift with limited resolution is studied, providing a reference for practical implementation. Numerical results show that our proposed algorithms can significantly outperform the benchmark schemes.
Multiple Intelligent Reflecting Surface aided Multi-user Weighted Sum-Rate Maximization using Manifold Optimization
Sep 29, 2021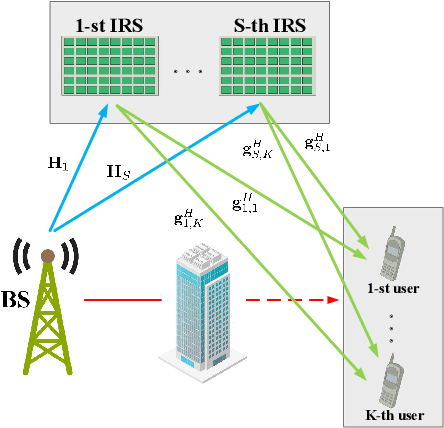

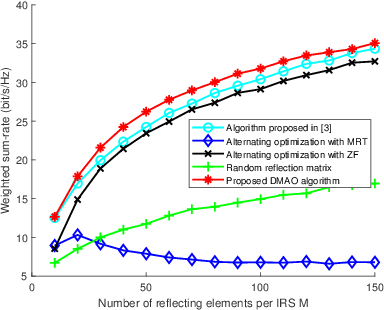
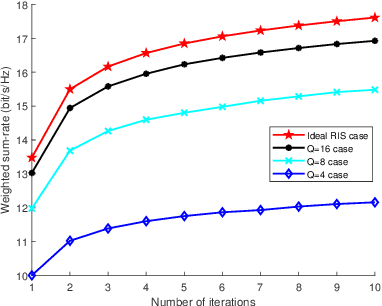
Intelligent reflecting surface (IRS) are able to amend radio propagation condition tasks on account of its functional properties in phase shift optimizing. In fact, there exists geometry manifold in the base-station (BS) beamforming matrix and IRS reflection vector. Therefore, we propose a novel double manifold alternating optimization (DMAO) algorithm which makes use of differential geometry theory to improve optimization performance. First, we develop a multi-IRS multi-user system model to maximize the weighted sum-rate, which may lead to the non-convexity in our optimization procedure. Then in order to allocate an optimized coefficients to each BS antenna and IRS reflecting element, we present the beamforming matrix and reflection vector using complex sphere manifold and complex oblique manifold, respectively, which integrates the inner geometry structure and the constrains. By an innovative alternative iteration method, the system gradually converges an optimized stable state, which is associating with the maximized sum-rate. Furthermore, we quantize the IRS reflection coefficient considering the practical constrains. Experimental results demonstrated that our approach significantly outperforms the conventional methods in terms of weighted sum-rate.