 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnicorn: Unified Neural Image Compression with One Number Reconstruction
Dec 11, 2024Prevalent lossy image compression schemes can be divided into: 1) explicit image compression (EIC), including traditional standards and neural end-to-end algorithms; 2) implicit image compression (IIC) based on implicit neural representations (INR). The former is encountering impasses of either leveling off bitrate reduction at a cost of tremendous complexity while the latter suffers from excessive smoothing quality as well as lengthy decoder models. In this paper, we propose an innovative paradigm, which we dub \textbf{Unicorn} (\textbf{U}nified \textbf{N}eural \textbf{I}mage \textbf{C}ompression with \textbf{O}ne \textbf{N}number \textbf{R}econstruction). By conceptualizing the images as index-image pairs and learning the inherent distribution of pairs in a subtle neural network model, Unicorn can reconstruct a visually pleasing image from a randomly generated noise with only one index number. The neural model serves as the unified decoder of images while the noises and indexes corresponds to explicit representations. As a proof of concept, we propose an effective and efficient prototype of Unicorn based on latent diffusion models with tailored model designs. Quantitive and qualitative experimental results demonstrate that our prototype achieves significant bitrates reduction compared with EIC and IIC algorithms. More impressively, benefitting from the unified decoder, our compression ratio escalates as the quantity of images increases. We envision that more advanced model designs will endow Unicorn with greater potential in image compression. We will release our codes in \url{https://github.com/uniqzheng/Unicorn-Laduree}.
CopyLens: Dynamically Flagging Copyrighted Sub-Dataset Contributions to LLM Outputs
Oct 06, 2024



Large Language Models (LLMs) have become pervasive due to their knowledge absorption and text-generation capabilities. Concurrently, the copyright issue for pretraining datasets has been a pressing concern, particularly when generation includes specific styles. Previous methods either focus on the defense of identical copyrighted outputs or find interpretability by individual tokens with computational burdens. However, the gap between them exists, where direct assessments of how dataset contributions impact LLM outputs are missing. Once the model providers ensure copyright protection for data holders, a more mature LLM community can be established. To address these limitations, we introduce CopyLens, a new framework to analyze how copyrighted datasets may influence LLM responses. Specifically, a two-stage approach is employed: First, based on the uniqueness of pretraining data in the embedding space, token representations are initially fused for potential copyrighted texts, followed by a lightweight LSTM-based network to analyze dataset contributions. With such a prior, a contrastive-learning-based non-copyright OOD detector is designed. Our framework can dynamically face different situations and bridge the gap between current copyright detection methods. Experiments show that CopyLens improves efficiency and accuracy by 15.2% over our proposed baseline, 58.7% over prompt engineering methods, and 0.21 AUC over OOD detection baselines.
Patch-enhanced Mask Encoder Prompt Image Generation
May 29, 2024Artificial Intelligence Generated Content(AIGC), known for its superior visual results, represents a promising mitigation method for high-cost advertising applications. Numerous approaches have been developed to manipulate generated content under different conditions. However, a crucial limitation lies in the accurate description of products in advertising applications. Applying previous methods directly may lead to considerable distortion and deformation of advertised products, primarily due to oversimplified content control conditions. Hence, in this work, we propose a patch-enhanced mask encoder approach to ensure accurate product descriptions while preserving diverse backgrounds. Our approach consists of three components Patch Flexible Visibility, Mask Encoder Prompt Adapter and an image Foundation Model. Patch Flexible Visibility is used for generating a more reasonable background image. Mask Encoder Prompt Adapter enables region-controlled fusion. We also conduct an analysis of the structure and operational mechanisms of the Generation Module. Experimental results show our method can achieve the highest visual results and FID scores compared with other methods.
SMP Challenge: An Overview and Analysis of Social Media Prediction Challenge
May 17, 2024



Social Media Popularity Prediction (SMPP) is a crucial task that involves automatically predicting future popularity values of online posts, leveraging vast amounts of multimodal data available on social media platforms. Studying and investigating social media popularity becomes central to various online applications and requires novel methods of comprehensive analysis, multimodal comprehension, and accurate prediction. SMP Challenge is an annual research activity that has spurred academic exploration in this area. This paper summarizes the challenging task, data, and research progress. As a critical resource for evaluating and benchmarking predictive models, we have released a large-scale SMPD benchmark encompassing approximately half a million posts authored by around 70K users. The research progress analysis provides an overall analysis of the solutions and trends in recent years. The SMP Challenge website (www.smp-challenge.com) provides the latest information and news.
SMP Challenge: An Overview of Social Media Prediction Challenge 2019
Oct 04, 2019
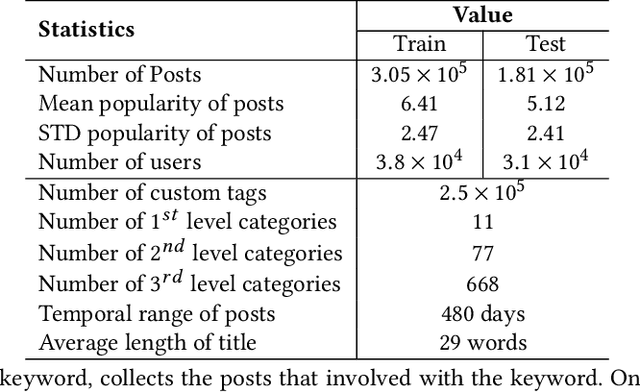


"SMP Challenge" aims to discover novel prediction tasks for numerous data on social multimedia and seek excellent research teams. Making predictions via social multimedia data (e.g. photos, videos or news) is not only helps us to make better strategic decisions for the future, but also explores advanced predictive learning and analytic methods on various problems and scenarios, such as multimedia recommendation, advertising system, fashion analysis etc. In the SMP Challenge at ACM Multimedia 2019, we introduce a novel prediction task Temporal Popularity Prediction, which focuses on predicting future interaction or attractiveness (in terms of clicks, views or likes etc.) of new online posts in social media feeds before uploading. We also collected and released a large-scale SMPD benchmark with over 480K posts from 69K users. In this paper, we define the challenge problem, give an overview of the dataset, present statistics of rich information for data and annotation and design the accuracy and correlation evaluation metrics for temporal popularity prediction to the challenge.
MemNet: Memory-Efficiency Guided Neural Architecture Search with Augment-Trim learning
Jul 22, 2019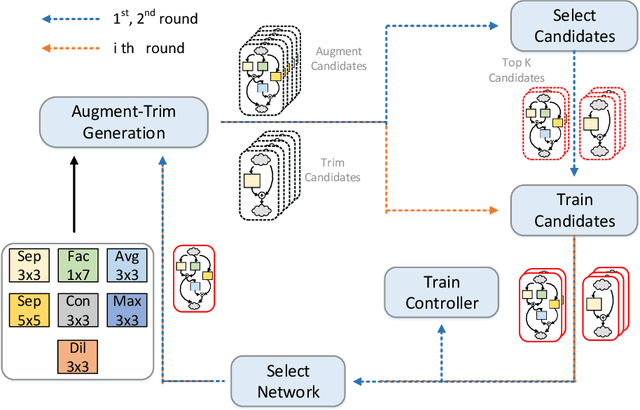
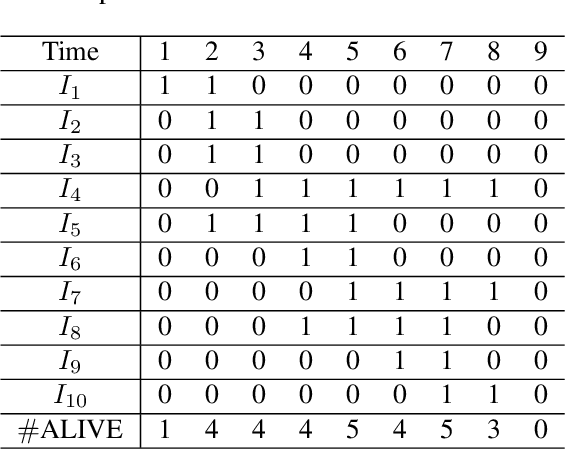

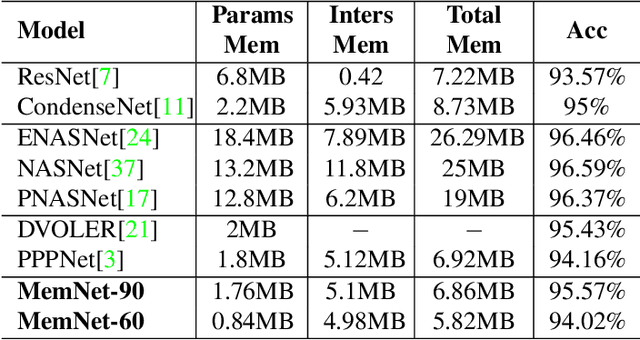
Recent studies on automatic neural architectures search have demonstrated significant performance, competitive to or even better than hand-crafted neural architectures. However, most of the existing network architecture tend to use residual, parallel structures and concatenation block between shallow and deep features to construct a large network. This requires large amounts of memory for storing both weights and feature maps. This is challenging for mobile and embedded devices since they may not have enough memory to perform inference with the designed large network model. To close this gap, we propose MemNet, an augment-trim learning-based neural network search framework that optimizes not only performance but also memory requirement. Specifically, it employs memory consumption based ranking score which forces an upper bound on memory consumption for navigating the search process. Experiment results show that, as compared to the state-of-the-art efficient designing methods, MemNet can find an architecture which can achieve competitive accuracy and save an average of 24.17% on the total memory needed.
KTAN: Knowledge Transfer Adversarial Network
Oct 18, 2018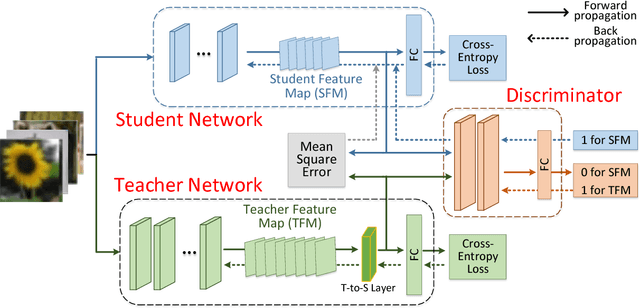



To reduce the large computation and storage cost of a deep convolutional neural network, the knowledge distillation based methods have pioneered to transfer the generalization ability of a large (teacher) deep network to a light-weight (student) network. However, these methods mostly focus on transferring the probability distribution of the softmax layer in a teacher network and thus neglect the intermediate representations. In this paper, we propose a knowledge transfer adversarial network to better train a student network. Our technique holistically considers both intermediate representations and probability distributions of a teacher network. To transfer the knowledge of intermediate representations, we set high-level teacher feature maps as a target, toward which the student feature maps are trained. Specifically, we arrange a Teacher-to-Student layer for enabling our framework suitable for various student structures. The intermediate representation helps the student network better understand the transferred generalization as compared to the probability distribution only. Furthermore, we infuse an adversarial learning process by employing a discriminator network, which can fully exploit the spatial correlation of feature maps in training a student network. The experimental results demonstrate that the proposed method can significantly improve the performance of a student network on both image classification and object detection tasks.